This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data federation using SQL engine
Amazon Athena: Introduction
Amazon Athena
Amazon Athena Federated Query is a new Athena feature that
enables data analysts, engineers, and data scientists to run
SQL queries across data stored in relational, non-relational,
object, and custom data sources. With Amazon Athena Federated
Query, customers can submit a single SQL query and analyze
data from multiple sources running on-premises or hosted on
the cloud. Athena runs federated queries using Data Source
Connectors that run
on AWS Lambda
Customers can use these connectors to run federated SQL queries in Athena across multiple data sources, including SaaS applications. Additionally, using Query Federation SDK, customers can build connectors to any proprietary data source, and enable Athena to run SQL queries against the data source. Because connectors run on Lambda, customers continue to benefit from Athena’s serverless architecture and do not have to manage infrastructure or scale for peak demands.
Architecture overview
Athena Federated query connector allows Athena to connect to SaaS applications like Salesforce, Snowflake, and Google BigQuery. Once a connection is established, you can write SQL queries to retrieve data stored in these SaaS applications. To store data in Amazon S3 data lake, you can use Athena statements Create Table as Select (CTAS) and INSERT INTO for ETL, which then store the data in Amazon S3 and create a table in the AWS AWS Glue Data Catalog.
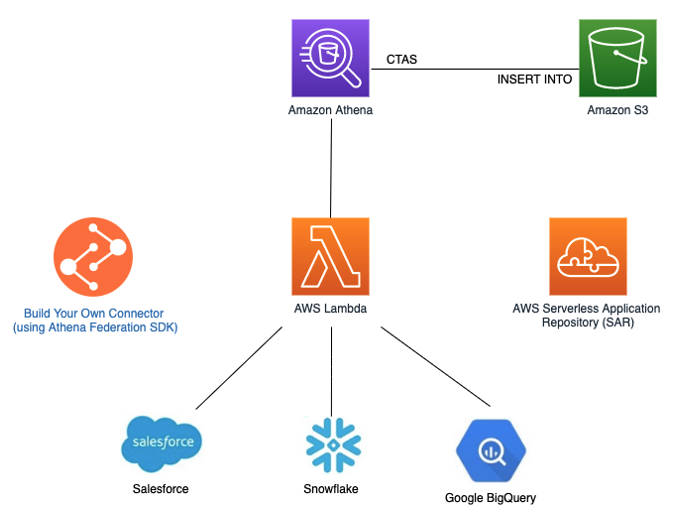
Amazon Athena-based data ingestion pattern
Usage patterns
This pattern is ideal for anyone who can write ANSI SQL
queries. Also, the Create Table as Select (CTAS) statement of
Athena provides the flexibility to create a table in AWS AWS Glue Data Catalog with the selected fields from the query, along
with the file type for the data to be stored in Amazon S3. You
can do an ETL transformation with ease, and the final datasets
can be made ready for end user consumption. You can also use
AWS Step Functions
Some use cases are as follows:
-
Analysts need to create a real-time, data-driven narrative, and identify specific data points.
-
Administrators need to deprecate old ingestion pipelines, and move to a serverless ingestion pipeline using just a few SQL queries.
-
Data engineers do not need to learn different data access paradigms; they can use SQL to source data from any particular data source.
-
Data scientists needs to use data from any SaaS data source to train their machine learning (ML) models, and that helps them to improve the accuracy of their ML models as well.
Considerations
Some third-party Athena connectors found in the AWS Serverless Application Repository are paid connectors, so due diligence should be done on the pricing aspect of such SaaS connectors. Also, SaaS applications may have their own bulk export limits and/or data export charges that need to be accounted for.
