This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data migration using Oracle Data Pump
When the size of the data to be migrated exceeds 10 GB, Oracle Data Pump is probably the best tool to use for migrating data to AWS. This method allows flexible data- extraction options, a high degree of parallelism, and scalable operations, which enables high-speed movement of data and metadata from one database to another. Oracle Data Pump is introduced with Oracle 10g as a replacement for the original Import/Export tools. It is available only on Oracle Database 10g Release 1 or later.
You can use the Oracle Data Pump method for both Amazon RDS for Oracle, and Oracle Database running on Amazon EC2. The process involved is similar for both, although Amazon RDS for Oracle requires a few additional steps.
Unlike the original Import/Export utilities, the Oracle Data Pump import requires the data files to be available in the database-server instance to import them into the database.
You cannot access the file system in the Amazon RDS instance directly, so you need to use one or more Amazon EC2 instances (bridge instances) to transfer files from the source to the Amazon RDS instance, and then import that into the Amazon RDS database. You need these temporary Amazon EC2 bridge instances only for the duration of the import; you can end the instances soon after the import is done. Use Amazon Linux-based instances for this purpose. You do not need an Oracle Database installation for an Amazon EC2 bridge instance; you only need to install the Oracle Instance Client.
Note
To use this method, your Amazon RDS database must be version 11.2.0.3 or later.
The following is the overall process for data migration using Oracle Data Pump for Oracle Database on Oracle for Amazon EC2 and Amazon RDS.
Migrating data to a database in Amazon EC2
-
Use Oracle Data Pump to export data from the source database as multiple compressed and encrypted files.
-
Use Tsunami UDP
to move the files to an Amazon EC2 instance running the destination Oracle database in AWS. -
Import that data into the destination database using the Oracle Data Pump import feature.
Migrating data to a database in Amazon RDS
-
Use Oracle Data Pump to export data from the source database as multiple files.
-
Use Tsunami UDP to move the files to Amazon EC2 bridge instances in AWS.
-
Using the provided Perl script that makes use of the
UTL_FILEpackage, move the data files to the Amazon RDS instance. -
Import the data into the Amazon RDS database using a PL/SQL script that utilizes the
DBMS_DATAPUMPpackage (an example is provided at the end of this section).
Using Oracle Data Pump to export data on the source instance
When you export data from a large database, you should run multiple threads in parallel and specify a size for each file. This speeds up the export, and also makes files available quickly for the next step of the process. There is no need to wait for the entire database to be exported before moving to the next step.
As each file completes, it can be moved to the next step. You can enable compression by
using the parameter COMPRESSION=ALL, which substantially reduces the size of
the extract files. You can encrypt files by providing a password, or by using an Oracle
wallet and specifying the parameter ENCRYPTION=all. To learn more about the
compression and encryption options, see the Oracle Data Pump
documentation
The following example shows the export of a 500 GB database, running eight threads in parallel, with each output file up to a maximum of 20 GB. This creates 22 files totaling 175 GB. The total file size is significantly smaller than the actual source database size because of the compression option of Oracle Data Pump:
expdp demoreinv/demo full=y dumpfile=data_pump_exp1:reinvexp1%U.dmp, data_pump_exp2:reinvexp2%U.dmp, data_pump_exp3:reinvexp3%U.dmp filesize=20G parallel=8 logfile=data_pump_exp1:reinvexpdp.log compression=all ENCRYPTION= all ENCRYPTION_PASSWORD=encryption_password job_name=reInvExp
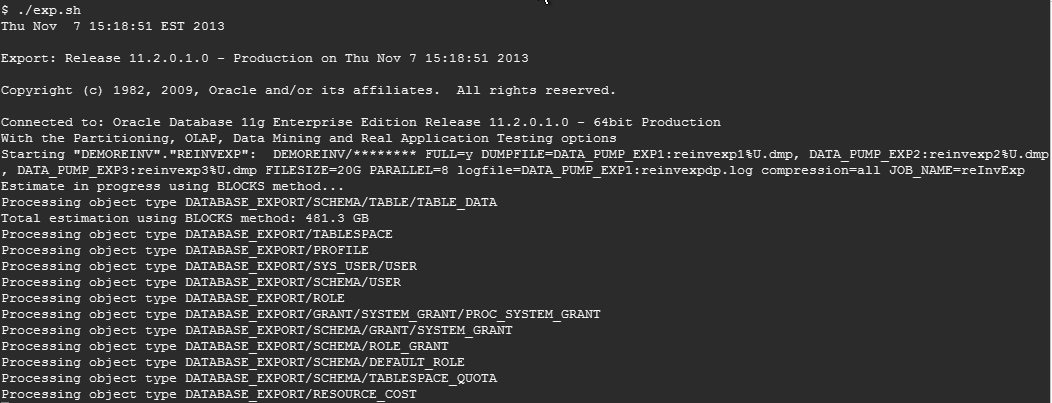
Using Oracle Data Pump to export data from the source database instance
Spreading the output files across different disks enhances input/output (I/O) performance. In the following examples, three different disks are used to avoid I/O contention.

Parallel run in multiple threads writing to three different disks

Dump files generated in each disk
The most time-consuming part of this entire process is the file transportation to AWS, so optimizing the file transport significantly reduces the time required for the data migration. The following steps show how to optimize the file transport:
-
Compress the dump files during the export.
-
Serialize the file transport in parallel. Serialization here means sending the files one after the other; you don’t need to wait for the export to finish before uploading the files to AWS. Uploading many of these files in parallel (if enough bandwidth is available) further improves the performance. We recommend that you parallel upload as many files as there are disks being used, and use the same number of Amazon EC2 bridge instances to receive those files in AWS.
-
Use Tsunami UDP
or a commercial wide area network (WAN) accelerator to upload the data files to the Amazon EC2 instances.
Using Tsunami to upload files to Amazon EC2
The following example shows how to install Tsunami on both the source database server and the Amazon EC2 instance:
yum -y install make yum -y install automake yum -y install gcc yum -y install autoconf yum -y install cvs wget http://sourceforge.net/projects/tsunami-udp/files/latest/download tar -xzf tsunami*gz cd tsunami-udp* ./recompile.sh make install
After you’ve installed Tsunami, open port 46224 to enable Tsunami communication. On the source database server, start a Tsunami server, as shown in the following example. If you do parallel upload, then you need to start multiple Tsunami servers:
cd/mnt/expdisk1 tsunamid *
On the destination Amazon EC2 instances, start a Tsunami server, as shown in the following example.
If you do multiple parallel file uploads, then you need to start a Tsunami server on each Amazon EC2 bridge instance.
If you do not use parallel file uploads, and if the migration is to an Oracle database on Amazon EC2 (not Amazon RDS), then you can avoid the Amazon EC2 bridge instance. Instead, you can upload the files directly to the Amazon EC2 instance where the database is running. If the destination database is Amazon RDS for Oracle, then the bridge instances are necessary because a Tsunami server cannot be run on the Amazon RDS server:
cd /mnt/data_files tsunami tsunami> connect source.db.server tsunami> get *
From this point forward, the process differs for a database on Amazon EC2 versus a database on Amazon RDS. The following sections show the processes for each service.
Next steps for a database on an Amazon EC2 instance
If you used one or more Amazon EC2 bridge instances in the preceding steps, then bring all the dump files from the Amazon EC2 bridge instances into the Amazon EC2 database instance. The easiest way to do this is to detach the Amazon Elastic Block Store (Amazon EBS) volumes that contain the files from the Amazon EC2 bridge instances, and connect them to the Amazon EC2 database instance.
Once all the dump files are available in the Amazon EC2 database instance, use the Oracle Data Pump import feature to get the data into the destination Oracle database on Amazon EC2, as shown in the following example:
impdp demoreinv/demo full=y DIRECTORY=DPUMP_DIR dumpfile= reinvexp1%U.dmp,reinvexp2%U.dmp, reinvexp3%U.dmp parallel=8 logfile=DPimp.log ENCRYPTION_PASSWORD=encryption_password job_name=DPImp
This imports all data into the database. Check the log file to make sure everything went well, and validate the data to confirm that all the data was migrated as expected.
Next steps for a database on Amazon RDS
Because Amazon RDS is a managed service, the Amazon RDS instance does not provide access to the
file system. However, an Oracle RDS instance has an externally accessible Oracle directory
object named DATA_PUMP_DIR. You can copy Oracle Data Pump dump files to this
directory by using an Oracle UTL_FILE package.
Amazon. RDS supports Amazon S3 integration as well. You could transfer files between the S3
bucket and Amazon RDS instance through S3 integration of RDS. The S3 integration option is
recommended when you want to transfer moderately large files to the RDS instance
dba_directories. Alternatively, you can use a PerlDATA_PUMP_DIR of the Amazon RDS instance.
Preparing a bridge Instance
To prepare a bridge instance, make sure that Oracle Instant Client, Perl DBI, and Oracle DBD modules are installed so that Perl can connect to the database. You can use the following commands to verify if the modules are installed:
$perl -e 'use DBI; print $DBI::VERSION,"\n";' $perl -e 'use DBD::Oracle; print $DBD::Oracle::VERSION,"\n";'
If the modules are not already installed, use the following process below to install them before proceeding further:
-
Download Oracle Database Instant Client from the Oracle website and unzip it into
ORACLE_HOME. -
Set up the environment variable, as shown in the following example:
$ export ORACLE_BASE=$HOME/oracle $ export ORACLE_HOME=$ORACLE_BASE/instantclient_11_2 $ export PATH=$ORACLE_HOME:$PATH $ export TNS_ADMIN=$HOME/etc $ export LD_LIBRARY_PATH=$ORACLE_HOME:$LD_LIBRARY_PATH -
Download and unzip
DBD::Oracle, as shown in the following example:$ wget http://www.cpan.org/authors/id/P/PY/PYTHIAN/DBD-Oracle-1.74.tar.gz $ tar xzf DBD-Oracle-1.74.tar.gz $ cd DBD-Oracle-1.74 -
Install
DBD::Oracle, as shown in the following example:$ mkdir $ORACLE_HOME/log $ perl Makefile.PL $ make $ make install
Transferring files to an Amazon RDS instance
To transfer files to an Amazon RDS instance, you need an Amazon RDS instance with at least twice as much storage as the actual database, because it needs to have space for the database and the Oracle Data Pump dump files. After the import is successfully completed, you can delete the dump files so that space can be utilized.
It might be a better approach to use an Amazon RDS instance solely for data migration. Once the data is fully imported, take a snapshot of RDS DB. Create a new Amazon RDS instance using the snapshot and then decommission the data migration instance. Use a single Availability Zone instance for data migration.
The following example shows a basic Perl script to transfer files to an Amazon RDS instance. Make changes as necessary. Because this script runs in a single thread, it uses only a small portion of the network bandwidth. You can run multiple instances of the script in parallel for a quicker file transfer to the Amazon RDS instance, but make sure to load only one file per process so that there won’t be any overwriting and data corruption. If you have used multiple bridge instances, you can run this script from all of the bridge instances in parallel, thereby expediting file transfer into the Amazon RDS instance:
# RDS instance info my $RDS_PORT=4080; my $RDS_HOST="myrdshost.xxx.us-east-1-devo.rds- dev.amazonaws.com"; my $RDS_LOGIN="orauser/orapwd"; my $RDS_SID="myoradb"; my $dirname = "DATA_PUMP_DIR"; my $fname= $ARGV[0]; my $data = ‘‘dummy’’; my $chunk = 8192; my $sql_open = "BEGIN perl_global.fh := utl_file.fopen(:dirname, :fname, 'wb', :chunk); END;"; my $sql_write = "BEGIN utl_file.put_raw(perl_global.fh, :data, true); END;"; my $sql_close = "BEGIN utl_file.fclose(perl_global.fh); END;"; my $sql_global = "create or replace package perl_global as fh utl_file.file_type; end;"; my $conn = DBI- >connect('dbi:Oracle:host='.$RDS_HOST.';sid='.$RDS_SID.';por t='.$RDS_PORT,$RDS_LOGIN, '') || die ( $DBI::errstr . "\n") ; my $updated=$conn->do($sql_global); my $stmt = $conn->prepare ($sql_open); $stmt->bind_param_inout(":dirname", \$dirname, 12); $stmt->bind_param_inout(":fname", \$fname, 12); $stmt->bind_param_inout(":chunk", \$chunk, 4); $stmt->execute() || die ( $DBI::errstr . "\n"); open (INF, $fname) || die "\nCan't open $fname for reading: $!\n"; binmode(INF); $stmt = $conn->prepare ($sql_write); my %attrib = ('ora_type’,’24’); my $val=1; while ($val > 0) { $val = read (INF, $data, $chunk); $stmt->bind_param(":data", $data , \%attrib); $stmt->execute() || die ( $DBI::errstr . "\n"); }; die "Problem copying: $!\n" if $!; close INF || die "Can't close $fname: $!\n"; $stmt = $conn->prepare ($sql_close); $stmt->execute() || die ( $DBI::errstr . "\n");
You can check the list of files in the DBMS_DATAPUMP directory using the following query:
SELECT * from table(RDSADMIN.RDS_FILE_UTIL.LISTDIR('DATA_PUMP_DIR'));
Once all files are successfully transferred to the Amazon RDS instance, connect to the Amazon RDS
database as a database administrator (DBA) user and submit a job by using a PL/SQLDBMS_DATAPUMP to import the files into the database, as shown in the
following PL/SQL script. Make any changes as necessary:
Declare h1 NUMBER; begin h1 := dbms_datapump.open (operation => 'IMPORT', job_mode => 'FULL', job_name => 'REINVIMP', version => 'COMPATIBLE'); dbms_datapump.set_parallel(handle => h1, degree => 8); dbms_datapump.add_file(handle => h1, filename => 'IMPORT.LOG', directory => 'DATA_PUMP_DIR', filetype => 3); dbms_datapump.set_parameter(handle => h1, name => 'KEEP_MASTER', value => 0); dbms_datapump.add_file(handle => h1, filename => 'reinvexp1%U.dmp', directory => 'DATA_PUMP_DIR', filetype => 1); dbms_datapump.add_file(handle => h1, filename => 'reinvexp2%U.dmp', directory => 'DATA_PUMP_DIR', filetype => 1); dbms_datapump.add_file(handle => h1, filename => 'reinvexp3%U.dmp', directory => 'DATA_PUMP_DIR', filetype => 1); dbms_datapump.set_parameter(handle => h1, name => 'INCLUDE_METADATA', value => 1); dbms_datapump.set_parameter(handle => h1, name => 'DATA_ACCESS_METHOD', value => 'AUTOMATIC'); dbms_datapump.set_parameter(handle => h1, name => 'REUSE_DATAFILES', value => 0); dbms_datapump.set_parameter(handle => h1, name => 'SKIP_UNUSABLE_INDEXES', value => 0); dbms_datapump.start_job(handle => h1, skip_current => 0, abort_step => 0); dbms_datapump.detach(handle => h1); end; /
Once the job is complete, check the Amazon RDS database to make sure all the data has been
successfully imported. At this point, you can delete all the dump files using
UTL_FILE.FREMOVE to reclaim disk space.
