向 Amazon Aurora 数据库集群添加自动扩缩策略
您可以使用AWS Management Console、AWS CLI 或 Application Auto Scaling API 添加扩展策略。
注意
有关使用 AWS CloudFormation 添加扩展策略的示例,请参阅 AWS CloudFormation 用户指南中声明 Aurora 数据库集群的扩展策略。
您可以使用AWS Management Console将扩展策略添加到 Aurora 数据库集群中。
在 Aurora 数据库集群中添加 Auto Scaling 策略
登录AWS Management Console并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
在导航窗格中,选择 Databases (数据库)。
-
选择要添加策略的 Aurora 数据库集群。
-
选择 Logs & events (日志和事件) 选项卡。
-
在 Auto Scaling 策略部分中,选择添加。
将显示添加 Auto Scaling 策略对话框。
-
对于 Policy Name (策略名称),键入策略名称。
-
对于目标指标,请选择以下选项之一:
-
Aurora 副本的平均 CPU 使用率,用于创建基于平均 CPU 使用率的策略。
-
Aurora 副本的平均连接数,用于创建基于 Aurora 副本的平均连接数的策略。
-
-
对于目标值,请键入以下值之一:
-
如果在上一步中选择 Aurora 副本的平均 CPU 使用率,请键入要在 Aurora 副本上保持的 CPU 使用率百分比。
-
如果在上一步中选择 Aurora 副本的平均连接数,请键入要保持的连接数。
将添加或删除 Aurora 副本以使指标接近于指定的值。
-
-
(可选)展开 Additional Configuration(附加配置)以创建横向缩减或横向扩展冷却时间。
-
对于最小容量,请键入 Aurora Auto Scaling 策略需要保持的最小 Aurora 副本数。
-
对于最大容量,请键入 Aurora Auto Scaling 策略需要保持的最大 Aurora 副本数。
-
选择添加策略。
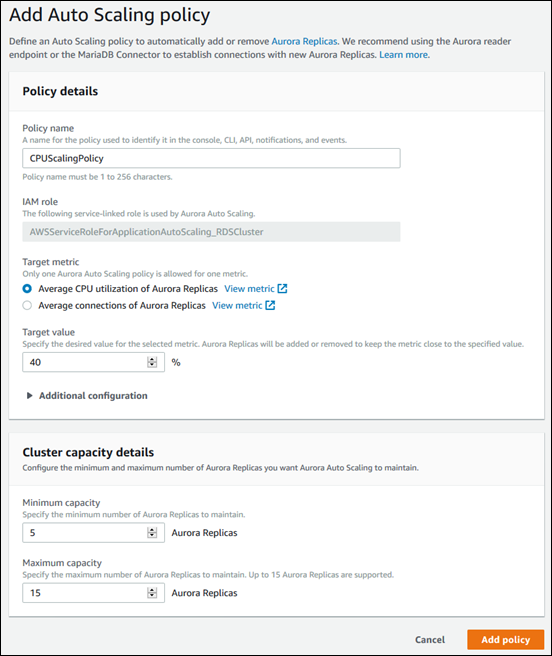
以下对话框创建一个基于平均 CPU 使用率 40% 的 Auto Scaling 策略。该策略指定最少 5 个 Aurora 副本,最多 15 个 Aurora 副本。
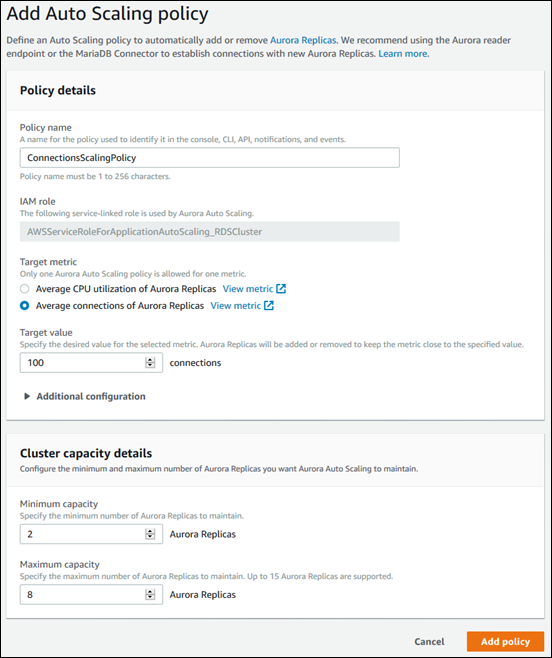
以下对话框创建一个基于平均连接数 100 的 Auto Scaling 策略。该策略指定最少 2 个 Aurora 副本,最多 8 个 Aurora 副本。
您可以应用基于预定义或自定义指标的扩展策略。为此,您可以使用 AWS CLI 或 Application Auto Scaling API。第一步是在 Application Auto Scaling 中注册 Aurora 数据库集群。
注册 Aurora 数据库集群
您必须先在 Application Auto Scaling 中注册 Aurora 数据库集群,然后才能在 Aurora 数据库集群中使用 Aurora Auto Scaling。这样做是为了定义应用于该集群的扩展维度和限制。Application Auto Scaling 沿 rds:cluster:ReadReplicaCount 可扩展维度动态扩展 Aurora 数据库集群,它表示 Aurora 副本的数量。
要注册 Aurora 数据库集群,您可以使用 AWS CLI 或 Application Auto Scaling API。
AWS CLI
要注册 Aurora 数据库集群,请使用具有以下参数的 register-scalable-target AWS CLI 命令:
-
--service-namespace– 将该值设置为rds。 -
--resource-id– Aurora 数据库集群的资源标识符。对于该参数,资源类型为cluster,唯一标识符为 Aurora 数据库集群的名称,例如,cluster:myscalablecluster。 -
--scalable-dimension– 将该值设置为rds:cluster:ReadReplicaCount。 -
--min-capacity– 由 Application Auto Scaling 管理的最小读取器数据库实例数。有关集群中--min-capacity、--max-capacity和数据库实例数之间关系的信息,请参阅 最小和最大容量。 -
--max-capacity– 由 Application Auto Scaling 管理的最大读取器数据库实例数。有关集群中--min-capacity、--max-capacity和数据库实例数之间关系的信息,请参阅 最小和最大容量。
在以下示例中,您注册一个名为 myscalablecluster 的 Aurora 数据库集群。该注册表示应动态扩展数据库集群以具有 1-8 个 Aurora 副本。
对于 Linux、macOS 或 Unix:
aws application-autoscaling register-scalable-target \ --service-namespace rds \ --resource-id cluster:myscalablecluster\ --scalable-dimension rds:cluster:ReadReplicaCount \ --min-capacity1\ --max-capacity8\
对于 Windows:
aws application-autoscaling register-scalable-target ^ --service-namespace rds ^ --resource-id cluster:myscalablecluster^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --min-capacity1^ --max-capacity8^
Application Auto Scaling API
要在 Application Auto Scaling 中注册 Aurora 数据库集群,请使用具有以下参数的 RegisterScalableTarget Application Auto Scaling API 操作:
-
ServiceNamespace– 将该值设置为rds。 -
ResourceID– Aurora 数据库集群的资源标识符。对于该参数,资源类型为cluster,唯一标识符为 Aurora 数据库集群的名称,例如,cluster:myscalablecluster。 -
ScalableDimension– 将该值设置为rds:cluster:ReadReplicaCount。 -
MinCapacity– 由 Application Auto Scaling 管理的最小读取器数据库实例数。有关集群中MinCapacity、MaxCapacity和数据库实例数之间关系的信息,请参阅 最小和最大容量。 -
MaxCapacity– 由 Application Auto Scaling 管理的最大读取器数据库实例数。有关集群中MinCapacity、MaxCapacity和数据库实例数之间关系的信息,请参阅 最小和最大容量。
在以下示例中,您使用 Application Auto Scaling API 注册一个名为 myscalablecluster 的 Aurora 数据库集群。该注册表示应动态扩展数据库集群以具有 1-8 个 Aurora 副本。
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.RegisterScalableTarget X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "MinCapacity":1, "MaxCapacity":8}
为 Aurora 数据库集群定义扩展策略
目标跟踪扩展策略配置是由 JSON 块表示的,其中定义了指标和目标值。您可以在文本文件中将扩展策略配置保存为 JSON 块。在调用 AWS CLI 或 Application Auto Scaling API 时,您可以使用该文本文件。有关策略配置语法的更多信息,请参阅 Application Auto Scaling API 参考 中的 TargetTrackingScalingPolicyConfiguration。
可以使用以下选项定义目标跟踪扩展策略配置。
使用预定义的指标
通过使用预定义的指标,您可以快速为 Aurora 数据库集群定义目标跟踪扩展策略,它非常适合 Aurora Auto Scaling 中的目标跟踪和动态扩展。
目前,Aurora 在 Aurora Auto Scaling 中支持以下预定义指标:
-
RDSReaderAverageCPUUtilization – CloudWatch 中的
CPUUtilization指标在 Aurora 数据库集群的所有 Aurora 副本中的平均值。 -
RDSReaderAverageDatabaseConnections – CloudWatch 中的
DatabaseConnections指标在 Aurora 数据库集群的所有 Aurora 副本中的平均值。
有关 CPUUtilization 和 DatabaseConnections 指标的更多信息,请参阅Amazon Aurora 的 Amazon CloudWatch 指标。
要在扩展策略中使用预定义的指标,您需要为扩展策略创建一个目标跟踪配置。该配置必须包含 PredefinedMetricSpecification 以表示预定义的指标,并包含 TargetValue 以表示该指标的目标值。
例
以下示例说明了 Aurora 数据库集群的典型目标跟踪扩展策略配置。在该配置中,RDSReaderAverageCPUUtilization 预定义指标用于根据所有 Aurora 副本中的平均 CPU 使用率 40% 调整 Aurora 数据库集群。
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } }
使用自定义指标
通过使用自定义指标,您可以定义满足您的自定义要求的目标跟踪扩展策略。您可以根据随扩展按比例变化的任何 Aurora 指标定义一个自定义指标。
并非所有 Aurora 指标都适用于目标跟踪。指标必须是有效的使用率指标,它用于描述实例的繁忙程度。指标值必须随 Aurora 数据库集群中的 Aurora 副本数按比例增加或减少。要使用指标数据按比例扩展或缩减 Aurora 副本数,必须按比例进行这种增加或减少。
例
以下示例说明了扩展策略的目标跟踪配置。在该配置中,一个自定义指标根据名为 my-db-cluster 的 Aurora 数据库集群的所有 Aurora 副本中的平均 CPU 使用率 50% 调整该 Aurora 数据库集群。
{ "TargetValue": 50, "CustomizedMetricSpecification": { "MetricName": "CPUUtilization", "Namespace": "AWS/RDS", "Dimensions": [ {"Name": "DBClusterIdentifier","Value": "my-db-cluster"}, {"Name": "Role","Value": "READER"} ], "Statistic": "Average", "Unit": "Percent" } }
使用冷却时间
您可以为 ScaleOutCooldown 指定一个值(秒)以添加扩展 Aurora 数据库集群的冷却时间。同样,您可以为 ScaleInCooldown 添加一个值(秒)以添加缩减 Aurora 数据库集群的冷却时间。有关 ScaleInCooldown 和 ScaleOutCooldown 的更多信息,请参阅 Application Auto Scaling API 参考 中的 TargetTrackingScalingPolicyConfiguration。
以下示例说明了扩展策略的目标跟踪配置。在此配置中,RDSReaderAverageCPUUtilization 预定义指标用于根据 Aurora 数据库集群中所有 Aurora 副本上 40% 的平均 CPU 利用率来调整该 Aurora 数据库集群。该配置将缩减冷却时间指定为 10 分钟,并将扩展冷却时间指定为 5 分钟。
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "ScaleInCooldown": 600, "ScaleOutCooldown": 300 }
禁用缩减活动
您可以禁用缩减活动以禁止目标跟踪扩展策略配置缩减 Aurora 数据库集群。禁用缩减活动将禁止扩展策略删除 Aurora 副本,同时仍允许扩展策略根据需要创建副本。
您可以为 DisableScaleIn 指定一个布尔值,以便为 Aurora 数据库集群启用或禁用缩减活动。有关 DisableScaleIn 的更多信息,请参阅 Application Auto Scaling API 参考 中的 TargetTrackingScalingPolicyConfiguration。
以下示例说明了扩展策略的目标跟踪配置。在该配置中,RDSReaderAverageCPUUtilization 预定义指标根据一个 Aurora 数据库集群的所有 Aurora 副本中的平均 CPU 使用率 40% 调整该 Aurora 数据库集群。该配置禁用扩展策略的缩减活动。
{ "TargetValue": 40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" }, "DisableScaleIn": true }
为 Aurora 数据库集群应用扩展策略
在 Application Auto Scaling 中注册 Aurora 数据库集群并定义扩展策略后,您可以将扩展策略应用于注册的 Aurora 数据库集群。要将扩展策略应用于 Aurora 数据库集群,您可以使用 AWS CLI 或 Application Auto Scaling API。
要将扩展策略应用于 Aurora 数据库集群,请使用具有以下参数的 put-scaling-policy AWS CLI 命令:
-
--policy-name– 扩展策略的名称。 -
--policy-type– 将该值设置为TargetTrackingScaling。 -
--resource-id– Aurora 数据库集群的资源标识符。对于该参数,资源类型为cluster,唯一标识符为 Aurora 数据库集群的名称,例如,cluster:myscalablecluster。 -
--service-namespace– 将该值设置为rds。 -
--scalable-dimension– 将该值设置为rds:cluster:ReadReplicaCount。 -
--target-tracking-scaling-policy-configuration– 用于 Aurora 数据库集群的目标跟踪扩展策略配置。
在以下示例中,您使用 Application Auto Scaling 将名为 myscalablepolicy 的目标跟踪扩展策略应用于名为 myscalablecluster 的 Aurora 数据库集群。为此,请使用在名为 config.json 的文件中保存的策略配置。
对于 Linux、macOS 或 Unix:
aws application-autoscaling put-scaling-policy \ --policy-namemyscalablepolicy\ --policy-type TargetTrackingScaling \ --resource-id cluster:myscalablecluster\ --service-namespace rds \ --scalable-dimension rds:cluster:ReadReplicaCount \ --target-tracking-scaling-policy-configurationfile://config.json
对于 Windows:
aws application-autoscaling put-scaling-policy ^ --policy-namemyscalablepolicy^ --policy-type TargetTrackingScaling ^ --resource-id cluster:myscalablecluster^ --service-namespace rds ^ --scalable-dimension rds:cluster:ReadReplicaCount ^ --target-tracking-scaling-policy-configurationfile://config.json
要使用 Application Auto Scaling API 将扩展策略应用于 Aurora 数据库集群,请使用具有以下参数的 PutScalingPolicy Application Auto Scaling API 操作:
-
PolicyName– 扩展策略的名称。 -
ServiceNamespace– 将该值设置为rds。 -
ResourceID– Aurora 数据库集群的资源标识符。对于该参数,资源类型为cluster,唯一标识符为 Aurora 数据库集群的名称,例如,cluster:myscalablecluster。 -
ScalableDimension– 将该值设置为rds:cluster:ReadReplicaCount。 -
PolicyType– 将该值设置为TargetTrackingScaling。 -
TargetTrackingScalingPolicyConfiguration– 用于 Aurora 数据库集群的目标跟踪扩展策略配置。
在以下示例中,您使用 Application Auto Scaling 将名为 myscalablepolicy 的目标跟踪扩展策略应用于名为 myscalablecluster 的 Aurora 数据库集群。您使用的策略配置基于 RDSReaderAverageCPUUtilization 预定义指标。
POST / HTTP/1.1 Host: autoscaling.us-east-2.amazonaws.com Accept-Encoding: identity Content-Length: 219 X-Amz-Target: AnyScaleFrontendService.PutScalingPolicy X-Amz-Date: 20160506T182145Z User-Agent: aws-cli/1.10.23 Python/2.7.11 Darwin/15.4.0 botocore/1.4.8 Content-Type: application/x-amz-json-1.1 Authorization: AUTHPARAMS { "PolicyName": "myscalablepolicy", "ServiceNamespace": "rds", "ResourceId": "cluster:myscalablecluster", "ScalableDimension": "rds:cluster:ReadReplicaCount", "PolicyType": "TargetTrackingScaling", "TargetTrackingScalingPolicyConfiguration": { "TargetValue":40.0, "PredefinedMetricSpecification": { "PredefinedMetricType": "RDSReaderAverageCPUUtilization" } } }
