从 Amazon S3 数据导入数据概述
将 S3 数据导入到 Aurora PostgreSQL
首先,收集您需要为该函数提供的详细信息。其中包括 Aurora PostgreSQL 数据库集群的实例上的表名称、桶名称、文件路径、文件类型以及存储 Amazon S3 数据的 AWS 区域。有关更多信息,请参阅《Amazon Simple Storage Service 用户指南》中的查看对象。
注意
目前不支持从 Amazon S3 导入分段数据。
获取
aws_s3.table_import_from_s3函数要向其中导入数据的表的名称。例如,以下命令创建表t1,供在后面的步骤中使用。postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));获取有关 Amazon S3 桶和要导入的数据的详细信息。为此,请通过以下网址打开 Amazon S3 控制台:https://console.aws.amazon.com/s3/
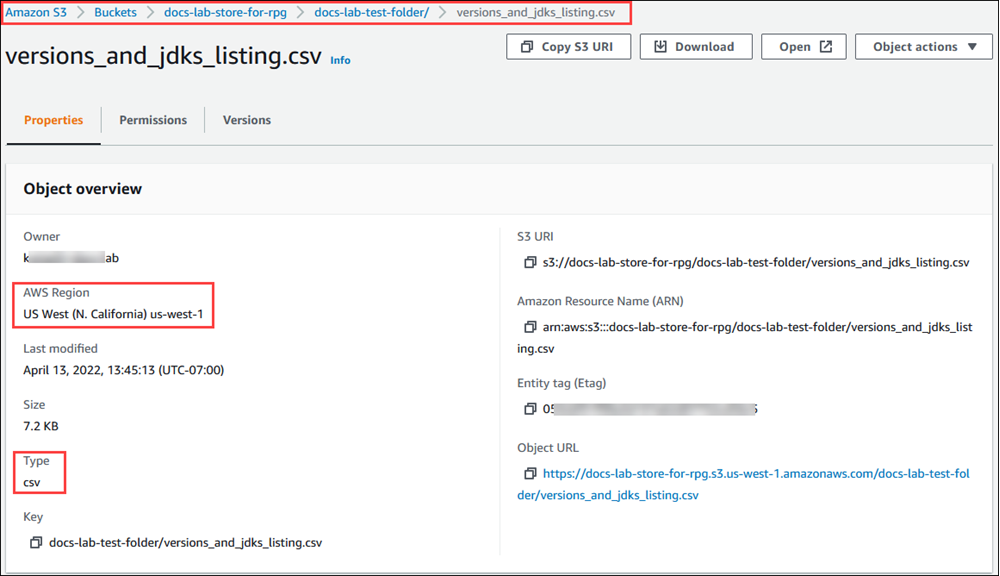
,然后选择 Buckets(桶)。在列表中找到包含您的数据的桶。选择桶,打开其 Object overview(对象概述)页面,然后选择 Properties(属性)。 记下桶名称、路径、AWS 区域和文件类型。您稍后需要提供 Amazon 资源名称(ARN),以便通过 IAM 角色设置对 Amazon S3 的访问权限。有关更多信息,请参阅设置 Amazon S3 存储桶的访问权限。下图显示了一个示例。
您可以使用 AWS CLI 命令
aws s3 cp验证 AmazonS3 桶上数据的路径。如果该信息正确无误,该命令将下载 Amazon S3 文件的副本。aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
在 Aurora PostgreSQL 数据库集群上设置权限,以允许访问 Amazon S3 桶中的文件。为此,您可以使用 AWS Identity and Access Management(IAM)角色或安全凭证。有关更多信息,请参阅 设置 Amazon S3 存储桶的访问权限。
将收集的路径和其他 Amazon S3 对象详细信息(请参阅步骤 2)提供给用于构造 Amazon S3 URI 对象的
create_s3_uri函数。要了解有关此函数的更多信息,请参阅aws_commons.create_s3_uri。以下是在 psql 会话期间构造此对象的示例。postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gset在下一步中,您将此对象(
aws_commons._s3_uri_1)传递到aws_s3.table_import_from_s3函数,以便将数据导入表中。-
调用
aws_s3.table_import_from_s3函数,以将数据从 Amazon S3 导入到您的表中。有关参考信息,请参阅aws_s3.table_import_from_s3。有关示例,请参阅将数据从 Amazon S3 导入到 Aurora PostgreSQL 数据库集群。
