在 DynamoDB 中为关系数据建模的初始步骤
重要
NoSQL 设计需要不同于 RDBMS 设计的思维模式。对于 RDBMS,可以创建规范化数据模型,不考虑访问模式。以后出现新问题和查询要求后进行扩展。而在 Amazon DynamoDB 中,应先了解需要解决的问题,再开始设计架构。预先了解业务问题和应用程序使用案例是至关重要的。
要开始设计能够高效扩展的 DynamoDB 表,必须先采取几个措施,确定其需要的支持的运营和业务支持系统 (OSS/BSS) 所需的访问模式。
对于新应用程序,查看有关活动和目标的用户案例。记录确定的各种使用案例,然后分析这些案例需要的访问模式。
对于现有应用程序,分析查询日志以了解人们目前使用该系统的方式,以及键访问模式。
完成此过程后,应获得一个可能如下所示的列表。
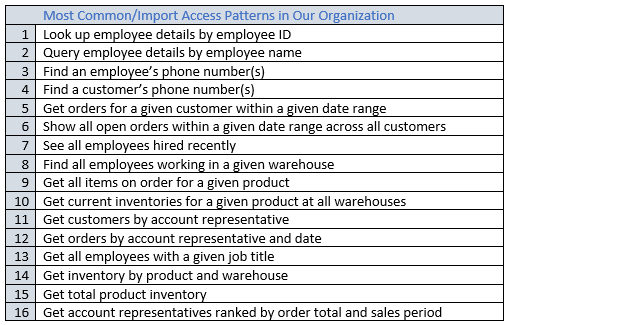
实际应用程序的列表可能更长。这个列表代表生产环境中可能出现的查询模式复杂性的范围。
DynamoDB 架构设计的常见方法是确定应用程序层实体,利用去规范化和复合键聚合降低查询复杂性。
在 DynamoDB 中,这意味着使用复合排序键、重载全局二级索引、分区表/索引以及其他设计模式。可以使用这些元素构造数据,使得应用程序可以在表或索引上使用单个查询,检索对于给定访问模式所需的任何内容。可以用于建模 关系建模 显示的规范化架构的主要模式是邻接列表模式。此设计使用的其他模式包括全局二级索引写入分片、全局二级索引重载、复合键和具体化聚合。
重要
通常应保持 DynamoDB 应用程序中的表保留尽可能少。例外情况包括涉及大量时间序列数据,或者数据集具有明显不同的访问模式的情况。具有反向索引的单个表通常支持简单查询,创建和检索应用程序所需的复杂层次数据结构。
要使用 NoSQL Workbench for DynamoDB 来帮助可视化您的分区键设计,请参阅使用 NoSQL Workbench 构建数据模型。
