本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Bedrock 知识库的运作方式
Amazon Bedrock 知识库可帮助您利用检索增强生成 (RAG),这是一种流行的技术,涉及从数据存储中提取信息以增强大型语言模型生成的响应 ()。LLMs当您使用数据源建立知识库时,您的应用程序可以查询知识库以返回信息,以便使用来自来源的直接报价或根据查询结果生成的自然响应来回答查询。
借助 Amazon Bedrock 知识库,您可以构建通过查询知识库获得的上下文丰富应用程序。它从繁重的建筑管道中抽象出来,为您提供 out-of-the-box RAG解决方案来缩短应用程序的构建时间,从而缩短上市时间。添加知识库还可以提高成本效益,因为无需持续训练模型即可利用您的私有数据。
下面的示意图说明了 RAG 的执行方法。知识库可以通过自动执行 RAG 的设置和实施中的几个步骤来简化这个过程。
预处理非结构化数据
为了实现对非结构化私有数据(结构化数据存储中不存在的数据)的有效检索,一种常见的做法是将数据转换为文本,然后将其拆分为可管理的部分。然后将这些部分或分块转换为嵌入内容并写入向量索引,同时保持与原文档的映射。这些嵌入内容用于确定查询和数据来源文本之间的语义相似性。下图说明了如何预处理向量数据库的数据。
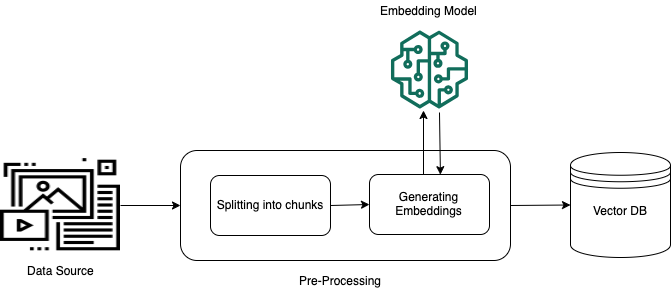
矢量嵌入是一系列数字,代表每块文本。模型将每个文本块转换为一系列数字(称为向量),以便可以对文本进行数学比较。这些向量可以是浮点数 (float32),也可以是二进制数。默认情况下,Amazon Bedrock 支持的大多数嵌入模型都使用浮点向量。但是,某些模型支持二进制向量。如果选择二进制嵌入模型,则还必须选择支持二进制向量的模型和向量存储。
每维度仅使用 1 位的二进制向量不如浮点 (float32) 向量那么昂贵,后者每维度使用 32 位。但是,二进制向量在表示文本时不如浮点向量那么精确。
以下示例以三种表示形式显示了一段文本:
| 表示 | 值 |
|---|---|
| 文本 | “Amazon Bedrock使用领先的人工智能公司和亚马逊的高性能基础模型。” |
| 浮点向量 | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| 二进制向量 | [1,1,0,0,0, ...] |
运行时执行
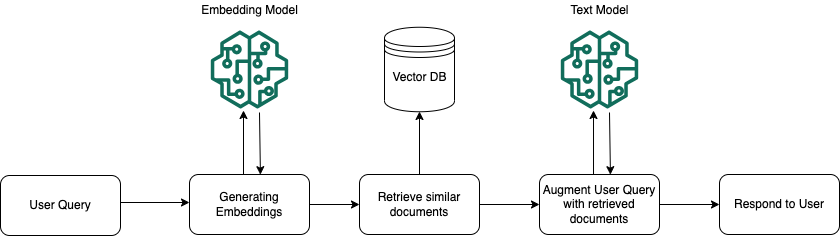
在运行时,使用嵌入模型将用户的查询转换为向量。然后,通过将文档向量与用户查询向量进行比较来查询向量索引,查找与用户查询在语义上相似的数据块。最后,使用从向量索引中检索到的数据块中的附加上下文来增强用户提示。接下来,将提示和附加上下文一起发送给模型,以便为用户生成响应。下图说明了 RAG 如何在运行时运行以增强对用户查询的响应。
要详细了解如何将数据转换为知识库、如何在设置知识库后查询知识库,以及在摄取期间可以应用于数据源的自定义设置,请参阅以下主题:
