本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Braket 混合作业运行混合作业
要使用 Amazon Braket 混合作业运行混合作业,您首先需要定义算法。您可以通过使用 Amazon Braket Python 软件开发工具包编写算法脚本以及其他依赖项文件来定义它,也可以使用 Amazon Braket Python SDK 或
无论哪种情况,接下来都要使用 Amazon Braket 创建混合作业API,在其中提供算法脚本或容器,选择混合作业要使用的目标量子设备,然后从各种可选设置中进行选择。为这些可选设置提供的默认值适用于大多数用例。对于运行混合作业(Hybrid Job)的目标设备,您可以在 QPU、按需模拟器(例如SV1、DM1或TN1)或经典混合作业实例本身之间进行选择。使用按需模拟器或 QPU,您的混合作业容器可以对远程设备进行 API 调用。使用嵌入式仿真器,仿真器与算法脚本嵌入在同一个容器中。中的闪电模拟 PennyLane 器
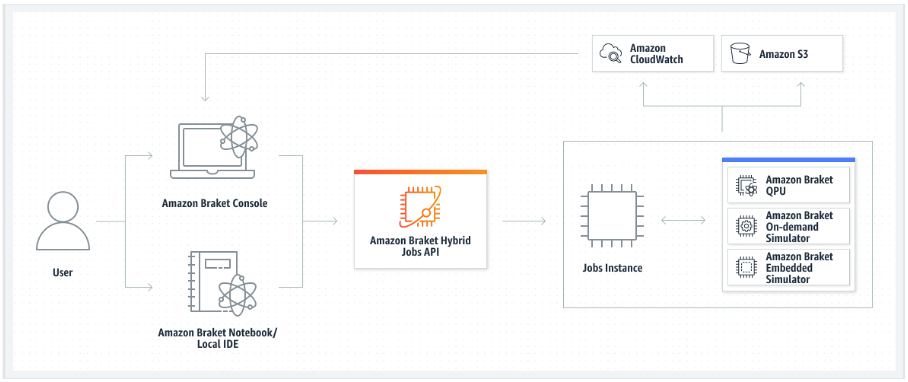
如果您的目标设备是按需模拟器或嵌入式模拟器,Amazon Braket 会立即开始运行混合任务。它启动混合作业实例(您可以在API调用中自定义实例类型),运行算法,将结果写入 Amazon S3,然后释放您的资源。此版本的资源可确保您只需为实际使用的资源付费。
每个量子处理单元 (QPU) 的并发混合任务总数受到限制。如今,在任何给定时间,QPU 上只能运行一个混合作业。队列用于控制允许运行的混合作业的数量,以免超过允许的限制。如果您的目标设备是 QPU,则混合作业将首先进入所选 QPU 的作业队列。Amazon Braket 启动所需的混合作业实例,并在设备上运行您的混合作业。在算法持续时间内,您的混合作业具有优先访问权限,这意味着混合作业中的量子任务优先于设备上排队的其他 Braket 量子任务,前提是该作业的量子任务每隔几分钟提交给 QPU 一次。混合任务完成后,资源就会被释放,这意味着您只需为实际使用的资源付费。
注意
设备是区域性的,您的混合任务与主设备在 AWS 区域 同一设备上运行。
在模拟器和 QPU 目标场景中,您可以选择将自定义算法指标(例如哈密顿能量)定义为算法的一部分。这些指标会自动报告给亚马逊, CloudWatch 然后在亚马逊Braket控制台中以近乎实时的方式显示。
注意
如果您想使用基于 GPU 的实例,请务必使用 Braket 上嵌入式模拟器中提供的基于 GPU 的模拟器(例如)。lightning.gpu如果您选择基于 CPU 的嵌入式模拟器之一(例如lightning.qubit、或braket:default-simulator),则不会使用 GPU,并且可能会产生不必要的成本。
