本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建 Amazon Chime SDK 数据湖
Amazon Chime SDK 呼叫分析数据湖允许您将基于机器学习的见解和来自 Amazon Kinesis Data Streams 的任何元数据流传输到您的 Amazon S3 存储桶。例如,使用数据湖 URLs 访问录音。要创建数据湖,您可以从 Amazon Chime 软件开发工具包控制台部署一组 AWS CloudFormation 模板,也可以使用以编程方式部署一组模板。 AWS CLI数据湖使您能够通过引用 Amazon Athena 中的 AWS Glue 数据表来查询您的通话元数据和语音分析数据。
先决条件
要创建 Amazon Chime SDK 数据湖,您必须具备以下物品:
-
Amazon Kinesis Data Streams。有关更多信息,请参阅《Amazon Kinesis 流开发者指南》中的通过 AWS 管理控制台创建流。
-
一个 S3 存储桶。有关更多信息,请参阅《Amazon S3 用户指南》中的创建第一个 Amazon S3 存储桶。
数据湖术语和概念
使用以下术语和概念来理解数据湖的工作原理。
- Amazon Kinesis Data Firehose
-
提取、转换、加载 (ETL) 服务,可靠地捕获、转换、传送流数据到数据湖、数据存储和分析服务。有关更多信息,请参阅什么是 Amazon Kinesis Data Firehose?
- Amazon Athena
-
Amazon Athena 是一种交互式查询服务,让您能够使用标准 SQL 分析 Amazon S3 中的数据。Athena 无服务器,因此您无需管理基础设施,只需为运行的查询付费。要使用 Athena,请指向 Amazon S3 中的数据,定义架构,然后使用标准 SQL 查询。您还可以使用工作组对用户进行分组,并控制他们在运行查询时可以访问的资源。工作组使您能够管理查询并发性,并在不同的用户组和工作负载之间确定查询执行的优先级。
- Glue 数据目录
-
在 Amazon Athena 中,表和数据库包含详细说明底层源数据架构的元数据。每个数据集都必须在 Athena 中有一个对应的表。表中的元数据将 Amazon S3 存储桶的位置告知 Athena。元数据还指定数据结构,例如列名、数据类型和表名。数据库仅保存数据集的元数据和架构信息。
创建多个数据湖
通过提供唯一的 Glue 数据库名称来指定呼叫见解的存储位置,可以创建多个数据湖。对于给定 AWS 账户,可以有多种呼叫分析配置,每种配置都有相应的数据湖。这意味着可以将数据分离应用于某些用例,例如自定义保留策略和数据存储方式的访问策略。可以采用不同的安全策略来访问见解、记录和元数据。
数据湖区域可用性
Amazon Chime SDK 数据湖在以下区域中推出。
区域 |
Glue 表 |
QuickSight |
|---|---|---|
us-east-1 |
可用 |
Available |
us-west-2 |
可用 |
Available |
eu-central-1 |
可用 |
Available |
数据湖架构
下图显示的是数据湖的架构。绘图中的数字对应于下面的编号文本。
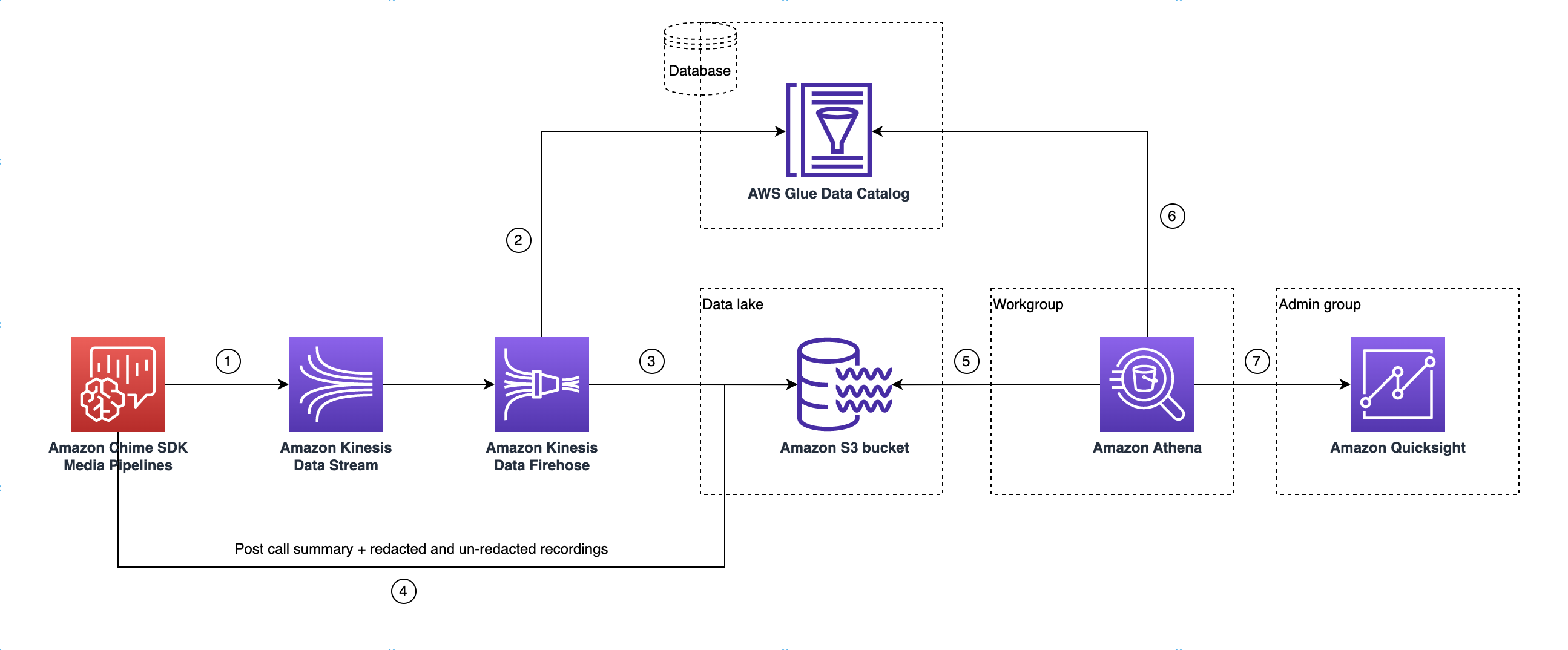
在图中,使用 AWS 控制台从媒体见解管道配置设置工作流程部署 CloudFormation模板后,以下数据将流向 Amazon S3 存储桶:
-
Amazon Chime SDK 呼叫分析将开始将实时数据流式传输到客户的 Kinesis Data Streams。
-
Amazon Kinesis Firehose 会缓冲这些实时数据,直到其累积 128MB,或时间达到 60 秒,以先到者为准。然后,Firehose 使用 Glue 数据目录中的
amazon_chime_sdk_call_analytics_firehose_schema来压缩数据,并将 JSON 记录转换为 Parquet 文件。 -
Parquet 文件以分区格式存放在您的 Amazon S3 存储桶中。
-
除了实时数据外,通话后的 Amazon Transcribe 通话分析功能摘要 .wav 文件(如果在配置中指定,则经过编辑和未编辑)和通话录音 .wav 文件也将发送到您的 Amazon S3 存储桶。
-
您可以使用 Amazon Athena 和标准 SQL 来查询 Amazon S3 存储桶中的数据。
-
该 CloudFormation 模板还创建了一个 Glue 数据目录,用于通过 Athena 查询此通话后摘要数据。
-
Amazon S3 存储桶上的所有数据也可以使用 QuickSight可视化。 QuickSight 使用亚马逊 Athena 与亚马逊 S3 存储桶建立连接。
Amazon Athena 表使用以下功能来优化查询性能:
- 数据分区
-
分区可将您的表格分成多个部分,并根据日期、国家和地区等列值将相关数据保存在一起。分区充当虚拟列。在这种情况下, CloudFormation 模板在创建表时定义分区,这有助于减少每次查询扫描的数据量并提高性能。您还可以按分区筛选,以限制查询所扫描的数据量。有关更多信息,请参阅《Amazon Athena 用户指南》中的 在 Athena 中对数据进行分区。
此示例介绍了日期为 2023 年 1 月 1 日的分区结构:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
其中,
DETAIL_TYPE为下列项之一:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- 优化列式数据存储的生成
-
Apache Parquet 使用按列压缩、基于数据类型的压缩和谓词下推来存储数据。更好的压缩率或跳过数据块意味着从 Amazon S3 存储桶中读取更少的字节。这样可以实现更佳的查询性能和更低的成本。为了进行此优化,在 Amazon Kinesis Data Firehose 中启用了从 JSON 到 parquet 的数据转换。
- 分区投影
-
这项 Athena 功能会自动为每天创建分区,以提高基于日期的查询性能。
数据湖设置
使用 Amazon Chime SDK 控制台完成以下步骤。
-
启动 Amazon Chime SDK 控制台( https://console.aws.amazon.com/chime-sdk/主页
),然后在导航窗格的 “呼叫分析” 下,选择 “配置”。 -
完成步骤 1,选择下一步,然后在步骤 2 页面上,选中语音分析复选框。
-
在 “输出详细信息” 下,选中 “要执行历史分析的数据仓库” 复选框,然后选择 “部署 CloudFormation 堆栈” 链接。
系统会将您发送到 CloudFormation 控制台中的快速创建堆栈页面。
-
输入堆栈的名称,然后输入以下参数:
-
DataLakeType— 选择 “创建通话分析” DataLake。 -
KinesisDataStreamName:选择您的流。它应该是用于呼叫分析流的流。 -
S3BucketURI:选择您的 Amazon S3 存储桶。URI 必须具有前缀s3://bucket-name -
GlueDatabaseName:选择一个唯一的 AWS Glue 数据库名称。您不能重复使用 AWS 账户中的现有数据库。
-
-
选中确认复选框,然后选择 Create data lake。等待 10 分钟让系统创建数据湖。
使用数据湖设置 AWS CLI
AWS CLI 用于创建具有调用创建堆栈权限 CloudFormation的角色。按照以下步骤创建和设置 IAM 角色。有关更多信息,请参阅《AWS CloudFormation 用户指南》中的创建堆栈。
-
创建一个名为 AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role 的角色,并将信任策略附加到允许担任该角色的角色。 CloudFormation
-
使用以下模板创建 IAM 信任策略,并将文件保存为 .json 格式。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
运行 aws iam create-role 命令并将信任策略作为参数传递。
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
记下响应中返回的角色 ARN。在下一步中需要用到角色 ARN。
-
-
创建具有创建 CloudFormation堆栈权限的策略。
-
使用以下模板创建 IAM 策略,并将文件保存为 .json 格式。调用 create-policy 时需要此文件。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
运行 aws iam create-policy 并将创建堆栈策略作为参数传递。
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
记下响应中返回的角色 ARN。在下一步中需要用到角色 ARN。
-
-
将 aws iam attach-role-policy 策略附加到该角色。
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
创建 CloudFormation 堆栈并输入所需参数:aws cloudformation create-stack。
为每种 ParameterKey 使用提供参数值 ParameterValue。
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
由数据湖设置创建的资源
下表列出了创建数据湖时创建的资源。
资源类型 |
资源名称和描述 |
服务名称 |
|---|---|---|
AWS Glue 数据目录数据库 |
GlueDatabaseName— 对属于通话见解和语音分析的所有 AWS Glue 数据表进行逻辑分组。 |
呼叫分析、语音分析 |
|
AWS Glue 数据目录表 |
amazon_chime_sdk_call_analytics_firehose_schema:提供给 Kinesis Firehose 的呼叫分析语音分析的组合架构。 |
呼叫分析、语音分析 |
call_analytics_metadata:呼叫分析元数据的架构。包含 SIPmetadata 和 OneTimeMetadata。 |
呼叫分析 |
|
| call_analytics_recording_metadata:录音架构和语音增强元数据 | 呼叫分析、语音分析 | |
transc@@ ribe_call_analytics — Payload “Utterance TranscribeCallAnalytics |
呼叫分析 |
|
tranc@@ ribe_call_analytics_category_events — Payload 的架构 TranscribeCallAnalytics |
呼叫分析 |
|
transcribe_call_analytics_post_call:通话后转录呼叫分析摘要有效负载的架构 |
呼叫分析 |
|
transcribe:转录有效载荷的架构 |
呼叫分析 |
|
voice_analytics_status:语音分析就绪事件的架构 |
语音分析 |
|
speaker_search_status:标识匹配的架构 |
语音分析 |
|
voice_tone_analysis_status:语调分析事件架构 |
语音分析 |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics-— Kinesis D |
呼叫分析、语音分析 |
Amazon Athena 工作组 |
GlueDatabaseName-AmazonChime SDKData Analytics — 用户逻辑组,用于控制他们在运行查询时可以访问的资源。 |
呼叫分析、语音分析 |
