本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
自定义分类器指标
Amazon Comprehend 提供的指标可帮助您估算自定义分类器的性能。Amazon Comprehend 使用分类器训练任务中的测试数据来计算指标。这些指标可以准确地表示模型在训练期间的性能,因此它们近似于模型对相似数据进行分类的性能。
使用 API 操作(例如DescribeDocumentClassifier检索自定义分类器的指标)。
注意
请参阅指标:精度、召回率,并 FScore
Metrics
Amazon Comprehend 支持以下指标:
要查看分类器的指标,请在控制台中打开分类器详细信息页面。
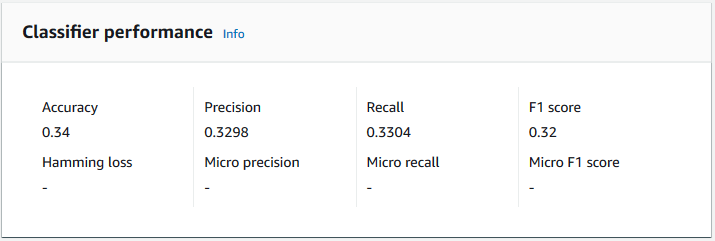
Accuracy
准确度表示模型从测试数据中准确预测出的标签百分比。要计算准确度,请将测试文档中准确预测的标签数除以测试文档中的标签总数。
例如
| 实际标签 | 预测标签 | 准确/不正确 |
|---|---|---|
|
1 |
1 |
准确 |
|
0 |
1 |
错误 |
|
2 |
3 |
错误 |
|
3 |
3 |
准确 |
|
2 |
2 |
准确 |
|
1 |
1 |
准确 |
|
3 |
3 |
准确 |
准确度由准确的预测数除以测试样本总数 = 5/7 = 0.714 或 71.4%
精度(宏观精度)
精度是衡量分类器结果在测试数据中是否有用的指标。其定义为准确分类的文档数除以该类别的分类总数。高精度意味着分类器返回的相关结果明显多于不相关的结果。
该 Precision 指标也被称为宏观精度。
以下示例显示了测试集的精度结果。
| 标签 | 样本量 | 标签精度 |
|---|---|---|
|
标签_1 |
400 |
0.75 |
|
标签_2 |
300 |
0.80 |
|
标签_3 |
30000 |
0.90 |
|
标签_4 |
20 |
0.50 |
|
标签_5 |
10 |
0.40 |
因此,该模型的精度(宏观精度)指标为:
Macro Precision = (0.75 + 0.80 + 0.90 + 0.50 + 0.40)/5 = 0.67召回(宏观召回)
这表示模型可以预测的文本中正确类别的百分比。该指标来自于所有可用标签的召回分数的平均值。召回率衡量的是分类器对测试数据结果的完整程度。
高召回率意味着分类器返回了大部分相关结果。
该 Recall 指标也被称为宏观召回。
以下示例显示了测试集的召回结果。
| 标签 | 样本量 | 标签召回 |
|---|---|---|
|
标签_1 |
400 |
0.70 |
|
标签_2 |
300 |
0.70 |
|
标签_3 |
30000 |
0.98 |
|
标签_4 |
20 |
0.80 |
|
标签_5 |
10 |
0.10 |
因此,该模型的召回(宏观召回)指标为:
Macro Recall = (0.70 + 0.70 + 0.98 + 0.80 + 0.10)/5 = 0.656F1 分数(宏观 F1 分数)
F1 分数源自 Precision 和 Recall 值。它衡量分类器的整体准确性。最高分为 1,最低分为 0。
Amazon Comprehend 计算宏观 F1 分数。这是标签 F1 分数的未加权平均值。以以下测试集为例:
| 标签 | 样本量 | 标签 F1 分数 |
|---|---|---|
|
标签_1 |
400 |
0.724 |
|
标签_2 |
300 |
0.824 |
|
标签_3 |
30000 |
0.94 |
|
标签_4 |
20 |
0.62 |
|
标签_5 |
10 |
0.16 |
模型的 F1 分数(宏观 F1 分数)的计算方法如下:
Macro F1 Score = (0.724 + 0.824 + 0.94 + 0.62 + 0.16)/5 = 0.6536汉明损失
错误预测的标签比例。也被视为错误标签占标签总数的比例。分数接近零越好。
微观精度
原始:
与精度指标类似,不同之处在于微观精度是基于所有精度分数相加的总分。
微观召回
与召回指标类似,不同之处在于微型召回是基于所有召回分数相加的总分。
微观 F1 分数
微观 F1 分数是微观精度和微观召回指标的组合。
提高自定义分类器的性能
这些指标可以深入了解您的自定义分类器在分类任务期间的表现。如果指标较低,则分类模型可能对您的使用案例无效。您可以通过多种方式来提高分类器的性能:
-
在您的训练数据中,提供具体的示例,以定义类别的明确区分。例如,提供使用 unique words/sentences 来表示类别的文档。
-
在训练数据中为代表性不足的标签添加更多数据。
-
尽量减少类别中的偏差。如果数据中最大的标签中的文档数量是最小标签中文档的 10 倍以上,请尝试增加最小标签的文档数量。确保将代表性较高的类别和代表性最少的类别之间的偏差率降低到最多 10:1。您也可以尝试从代表性较高的类中移除输入文档。
