本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
步骤 4:准备用于数据可视化的 Amazon Comprehend 输出
要准备用于创建数据可视化效果的情绪和实体分析任务的结果,请使用 AWS Glue 和 Amazon Athena。在此步骤中,您将提取到 Amazon Comprehend 结果文件。然后,您可以创建一个 AWS Glue 爬网程序,用于浏览您的数据并自动将其编入 AWS Glue Data Catalog中的表格中。之后,您可以使用无服务器的交互式查询服务访问和转换这些表。 Amazon Athena完成此步骤后,您的 Amazon Comprehend 结果就干净了,可以进行可视化了。
对于 PII 实体检测任务,输出文件是纯文本,而不是压缩存档。输出文件名与输入文件名相同,并在末尾附上 .out。您不需要提取输出文件的步骤。跳到将数据加载到 AWS Glue Data Catalog.
先决条件
在开始之前,请完成步骤 3:在 Amazon S3 中对文档运行分析任务。
下载输出结果
Amazon Comprehend 使用 Gzip 压缩来压缩输出文件并将其保存为 tar 存档。提取输出文件的最简单方法是在本地下载 output.tar.gz 存档。
在此步骤中,您将下载情绪和实体输出档案。
要查找每个任务的输出文件,请返回 Amazon Comprehend 控制台中的分析任务。分析任务提供输出的 S3 位置,您可以从中下载输出文件。
下载输出文件(控制台)
-
在 Amazon Comprehend 控制台
的导航窗格中,返回分析任务。 -
选择您的情绪分析任务
reviews-sentiment-analysis。 -
在输出下,选择输出数据位置旁边显示的链接。这会将您重定向到 S3 存储桶中的
output.tar.gz存档。 -
在概述选项卡中,选择下载。
-
在您的计算机上,将存档重命名为
sentiment-output.tar.gz。由于所有输出文件都具有相同的名称,因此这可以帮助您跟踪情绪和实体文件。 -
重复步骤 1 - 4,查找并下载
reviews-entities-analysis任务的输出。在您的计算机上,将存档重命名为entities-output.tar.gz。
要查找每个任务的输出文件,请使用分析任务中的 JobId 来查找输出的 S3 位置。然后,使用 cp 命令将输出文件下载到您的计算机。
下载输出文件 (AWS CLI)
-
要列出有关您的情绪分析任务的详细信息,请运行以下命令。替换
sentiment-job-idJobId。aws comprehend describe-sentiment-detection-job --job-idsentiment-job-id如果您不知道您的
JobId,则可以运行以下命令来列出所有情绪任务,并按名称筛选您的任务。aws comprehend list-sentiment-detection-jobs --filter JobName="reviews-sentiment-analysis" -
在
OutputDataConfig对象中,找到S3Uri值。S3Uri值应类似于以下格式:s3://amzn-s3-demo-bucket/.../output/output.tar.gz -
要将情绪输出存档下载到本地目录,请运行以下命令。将 S3 存储桶路径替换为您在上一步中复制的
S3Uri。将path/sentiment-output.tar.gz替换了原始存档名称,以帮助您跟踪情绪和实体文件。aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/sentiment-output.tar.gz -
要列出有关您的实体分析任务的详细信息,请运行以下命令。
aws comprehend describe-entities-detection-job --job-identities-job-id如果您不知道您的
JobId,运行以下命令来列出所有实体任务,并按名称筛选您的任务。aws comprehend list-entities-detection-jobs --filter JobName="reviews-entities-analysis" -
从实体任务描述中的
OutputDataConfig对象中,复制S3Uri值。 -
要将实体输出存档下载到本地目录,请运行以下命令。将 S3 存储桶路径替换为您在上一步中复制的
S3Uri。将path/entities-output.tar.gz取代了原始存档名称。aws s3 cps3://amzn-s3-demo-bucket/.../output/output.tar.gzpath/entities-output.tar.gz
提取输出文件
在访问 Amazon Comprehend 结果之前,请先解压情绪和实体存档。您可以使用本地文件系统或终端来解压缩存档。
如果您使用的是 macOS,请双击 GUI 文件系统中的存档文件以从存档中提取输出文件。
如果您使用 Windows,则可以使用第三方工具(例如 7-Zip)在 GUI 文件系统中提取输出文件。在 Windows 中,必须执行两个步骤才能访问存档中的输出文件。首先解压存档,然后提取存档。
将情绪文件重命名为 sentiment-output,将实体文件重命名为 entities-output,以区分输出文件。
如果您使用的是 Linux 或 macOS,则可以使用标准终端。如果您使用 Windows,则必须有权访问 Unix 风格的环境(例如 Cygwin)才能运行 tar 命令。
要从情绪存档中提取情绪输出文件,请在本地终端中运行以下命令。
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
请注意,--transform 参数将前缀 sentiment- 添加到存档内的输出文件中,将文件重命名为 sentiment-output。这使您可以区分情绪和实体输出文件并防止覆盖。
要从实体存档中提取实体输出文件,请在本地终端中运行以下命令。
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
--transform 参数将前缀 entities- 添加到输出文件名中。
提示
为了节省 Amazon S3 中的存储成本,您可以在上传文件之前使用 Gzip 再次压缩文件。解压缩和解压缩原始存档很重要,因为 AWS Glue 无法自动从 tar 存档中读取数据。但是, AWS Glue 可以从 Gzip 格式的文件中读取。
上传提取的文件
解压文件后,将其上传到您的存储桶。为了正确读取数据,必须将情绪和实体输出文件存储在单独的文件夹中。 AWS Glue 在您的存储桶中,为提取的情绪结果创建一个文件夹,为提取的实体结果创建第二个文件夹。您可以使用 Amazon S3 控制台来创建文件夹,也可以使用 AWS CLI。
在您的 S3 存储桶中,为提取的情绪结果创建一个文件夹,为实体结果文件创建一个文件夹。然后,将提取的结果文件上传到各自的文件夹中。
将提取后的文件上传到 Amazon S3(控制台)
打开 Amazon S3 控制台,网址为 https://console.aws.amazon.com/s3/
。 -
在存储桶中,选择您的存储桶,然后选择创建文件夹。
-
对于新文件夹的名称,输入
sentiment-results并选择保存。此文件夹将包含提取的情绪输出文件。 -
在存储桶的概述选项卡中,从存储桶内容列表中选择新文件夹
sentiment-results。选择上传。 -
选择添加文件,从本地计算机中选择
sentiment-output文件,然后选择下一步。 -
将 “管理用户”、“其他 AWS 账户用户访问权限” 和 “管理公共权限” 选项保留为默认值。选择下一步。
-
对于存储类别,选择标准。将加密、元数据和标记选项保留为默认值。选择下一步。
-
查看上传选项,然后选择上传。
-
重复步骤 1 - 8,创建一个名为
entities-results的文件夹,并将entities-output文件上传到该文件夹。
使用 cp 命令上传文件时,您可以在 S3 存储桶中创建文件夹。
将提取后的文件上传到 Amazon S3 (AWS CLI)
-
通过运行以下命令创建一个情绪文件夹,并将您的情绪文件上传到该文件夹。
path/aws s3 cppath/sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/ -
通过运行以下命令创建一个实体输出文件夹,并将您的实体文件上传到该文件夹。
path/aws s3 cppath/entities-output s3://amzn-s3-demo-bucket/entities-results/
将数据加载到 AWS Glue Data Catalog
要将结果导入数据库,你可以使用 AWS Glue 爬虫。 AWS Glue 爬虫会扫描文件并发现数据的架构。然后,它将数据排列在 AWS Glue Data Catalog (无服务器数据库)中的表中。您可以使用 AWS Glue 控制台或. 创建爬虫。 AWS CLI
创建可分别扫描您的sentiment-results和entities-results文件夹的 AWS Glue 抓取工具。 AWS Glue
的新 IAM 角色授予爬虫程序访问您的 S3 存储桶的权限。您在设置爬网程序时创建此 IAM 角色。
将数据加载到 AWS Glue Data Catalog (控制台)
-
确保您所在的地区支持该功能 AWS Glue。如果您在另一区域,请在导航栏中,从区域选择器中选择选择支持的区域。有关支持的区域列表 AWS Glue,请参阅《全球基础设施指南》中的区域表
。 打开 AWS Glue 控制台,网址为https://console.aws.amazon.com/glue/
。 -
在导航窗格中,选择爬网程序,然后选择添加爬网程序。
-
对于爬网程序名称,输入
comprehend-analysis-crawler,然后选择下一步。 -
对于爬网程序源类型,选择数据存储,然后选择下一步。
-
对于添加数据存储,请执行以下操作:
-
对于选择数据存储,请选择 S3。
-
将连接留空。
-
对于爬网数据位于选项,选择在我的账户中指定路径。
-
在包含路径中,输入情绪输出文件夹的完整 S3 路径:
s3://amzn-s3-demo-bucket/sentiment-results。 -
选择下一步。
-
-
对于添加其他数据存储,请依次选择是、下一步。重复步骤 6,但输入实体输出文件夹的完整 S3 路径:
s3://amzn-s3-demo-bucket/entities-results。 -
对于添加其他数据存储,请依次选择是、下一步。
-
对于选择 IAM 角色,请执行以下操作之一:
-
选择创建 IAM 角色。
-
对于 IAM 角色,输入
glue-access-role,然后选择下一步。
-
-
在为此爬网程序创建计划中,选择按需运行,然后选择下一步。
-
对于配置爬网程序的输出,请执行以下操作:
-
对于数据库,选择添加数据库。
-
对于 Database name (数据库名称),请输入
comprehend-results。该数据库将存储您的 Amazon Comprehend 输出表。 -
将其他选项保留为默认设置,然后选择下一步。
-
-
检查爬网程序信息,然后选择完成。
-
在 Glue 控制台的爬网程序中,选择
comprehend-analysis-crawler并选择运行爬网程序。爬网程序可能需要几分钟时间来完成。
为创建一个 IAM 角色 AWS Glue 以提供访问您的 S3 存储桶的权限。然后,在 AWS Glue Data Catalog中创建数据库。最后,创建并运行一个爬网程序,将您的数据加载到数据库的表中。
将数据加载到 AWS Glue Data Catalog (AWS CLI)
-
要为创建 IAM 角色 AWS Glue,请执行以下操作:
-
将以下信任策略另存为计算机上名为
glue-trust-policy.json的 JSON 文档。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } -
运行以下命令以创建 IAM 角色。将
path/aws iam create-role --role-name glue-access-role --assume-role-policy-document file://path/glue-trust-policy.json -
AWS CLI 列出新角色的 Amazon 资源编号 (ARN) 时,将其复制并保存到文本编辑器中。
-
将以下 IAM policy 另存为计算机上名为
glue-access-policy.json的 JSON 文档。该策略授予对您的结果文件夹进行爬网的 AWS Glue 权限。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*", "arn:aws:s3:::amzn-s3-demo-bucket/entities-results*" ] } ] } -
要创建 IAM policy,请运行以下命令。将
path/aws iam create-policy --policy-name glue-access-policy --policy-document file://path/glue-access-policy.json -
AWS CLI 列出访问策略的 ARN 后,将其复制并保存到文本编辑器中。
-
使用以下命令将新策略附加到 IAM 角色。将
policy-arnaws iam attach-role-policy --policy-arnpolicy-arn--role-name glue-access-role -
通过运行以下命令将 AWS 托管策略附加
AWSGlueServiceRole到您的 IAM 角色。aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole --role-name glue-access-role
-
-
通过运行以下命令创建 AWS Glue 数据库。
aws glue create-database --database-input Name="comprehend-results" -
通过运行以下命令创建新的 AWS Glue 爬虫。
glue-iam-role-arnaws glue create-crawler --name comprehend-analysis-crawler --roleglue-iam-role-arn--targets S3Targets=[ {Path="s3://amzn-s3-demo-bucket/sentiment-results"}, {Path="s3://amzn-s3-demo-bucket/entities-results"}] --database-name comprehend-results -
通过运行以下命令启动爬网程序。
aws glue start-crawler --name comprehend-analysis-crawler爬网程序可能需要几分钟时间来完成。
准备数据以供分析
现在,您的数据库中填充了 Amazon Comprehend 结果。但是,结果是嵌套的。要解除它们的嵌套,你需要在中运行几条 SQL 语句。 Amazon Athena Amazon Athena 是一项交互式查询服务,可使用标准 SQL 轻松分析 Amazon S3 中的数据。Athena 是无服务器的,因此无需管理基础架构,而且它有定价模式。 pay-per-query在此步骤中,您将创建用于分析和可视化的已清理数据的新表。您可以使用 Athena 控制台来准备数据。
准备数据
从 https://console.aws.amazon.com/athena/
打开 Athena 控制台。 -
在查询编辑器中,选择 Settings(设置),然后选择 Manage(管理)。
-
在查询结果的位置中,输入
s3://amzn-s3-demo-bucket/query-results/。这将在您的存储桶query-results中创建一个名为的新文件夹,用于存储您运行的 Amazon Athena 查询的输出。选择保存。 -
在查询编辑器中,选择编辑器。
-
对于数据库,选择您创建 AWS Glue 的数据
comprehend-results库。 -
在表部分中,应该有两个名为
sentiment_results和entities_results的表。预览表格,确保爬网程序加载了数据。在每个表格的选项(表格名称旁边的三个点)中,选择预览表格。自动运行简短查询。检查结果窗格以确保表中包含数据。提示
如果表中没有任何数据,请尝试检查 S3 存储桶中的文件夹。确保有一个用于存储实体结果的文件夹和一个用于存储情绪结果的文件夹。然后,尝试运行新的 AWS Glue 爬虫。
-
要取消嵌套
sentiment_results表,请在查询编辑器中输入以下查询,然后选择运行。CREATE TABLE sentiment_results_final AS SELECT file, line, sentiment, sentimentscore.mixed AS mixed, sentimentscore.negative AS negative, sentimentscore.neutral AS neutral, sentimentscore.positive AS positive FROM sentiment_results -
要开始取消嵌套实体表,请在查询编辑器中输入以下查询,然后选择运行。
CREATE TABLE entities_results_1 AS SELECT file, line, nested FROM entities_results CROSS JOIN UNNEST(entities) as t(nested) -
要完成取消嵌套实体表,请在查询编辑器中输入以下查询,然后选择运行查询。
CREATE TABLE entities_results_final AS SELECT file, line, nested.beginoffset AS beginoffset, nested.endoffset AS endoffset, nested.score AS score, nested.text AS entity, nested.type AS category FROM entities_results_1
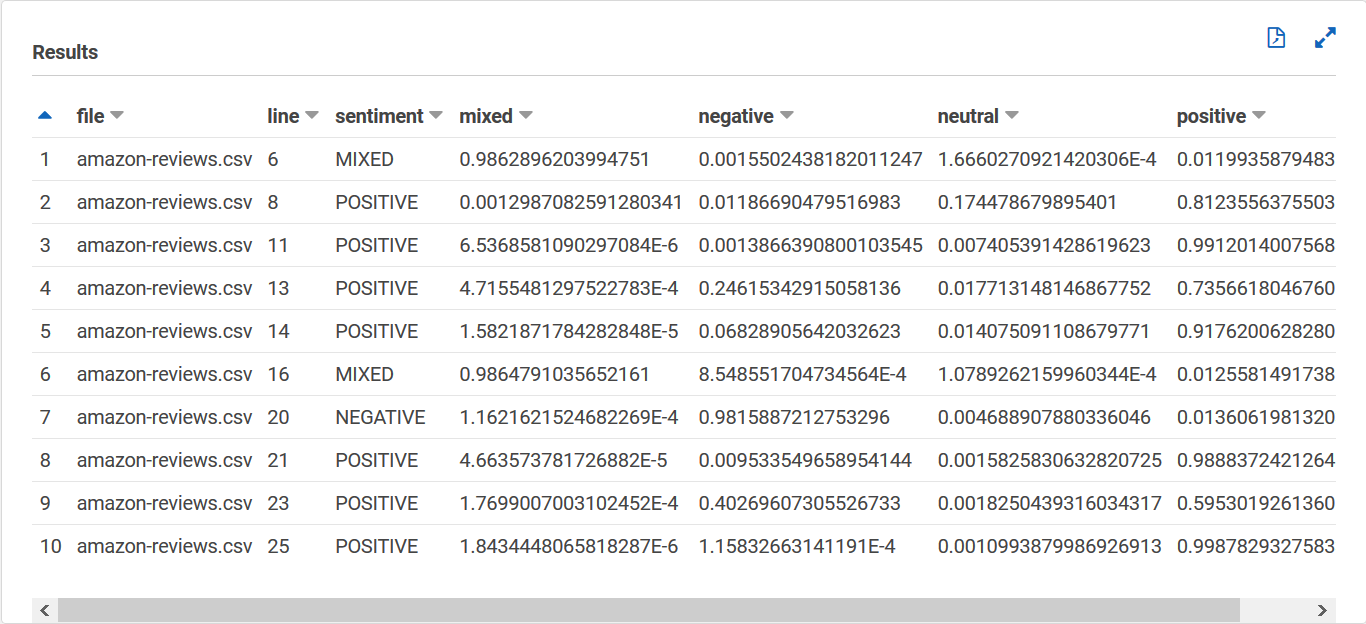
您的 sentiment_results_final 表格应如下所示,列名分别为文件、行、情绪、混合、消极、中性和积极。该表的每个单元格应有一个值。情绪列描述了某条评论中最有可能的总体情绪。混合、消极、中性、积极的列给出了每种情绪的分数。
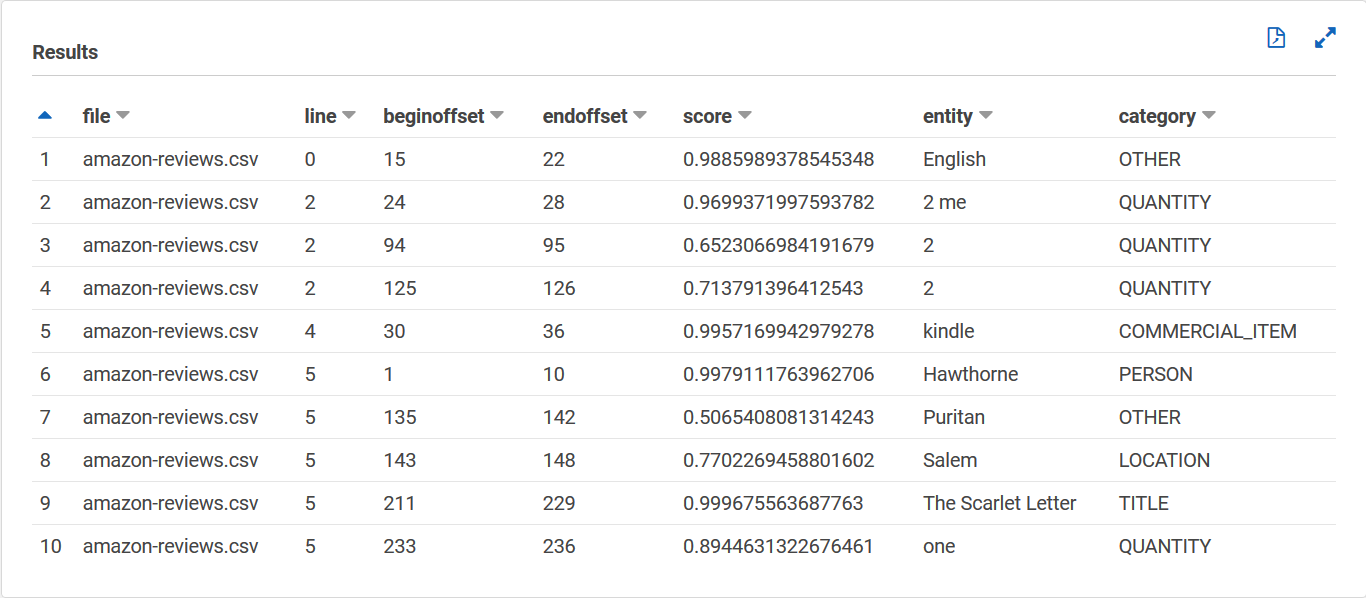
您 entities_results_final 表应如下所示,列名分别为文件、行、开始偏移量、结束偏移量、分数、实体 和 类别。该表的每个单元格应有一个值。分数列表示 Amazon Comprehend 对其检测到的实体的置信度。该类别表示 Comprehend 检测到的是哪种实体。
现在,您已将 Amazon Comprehend 结果加载到表格中,您可以对数据进行可视化并从中提取有意义的见解。
