本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
节点和工作负载效率
提高工作负载和节点的效率可以减少工作负载和节点, complexity/cost 同时提高性能和规模。在规划这种效率时,有许多因素需要考虑,最容易从权衡角度来考虑,而不是为每个功能设置一个最佳实践设置。让我们在下一节中深入探讨这些权衡。
节点选择
使用稍大一点的节点大小(4-12xlarge)会增加我们用于运行 Pod 的可用空间,因为这样可以减少用于 “开销”(例如DaemonSets
注意
由于 k8s 通常水平扩展,因此对于大多数应用程序来说,考虑 NUMA 大小节点对性能的影响是没有意义的,因此建议使用低于该节点大小的范围。
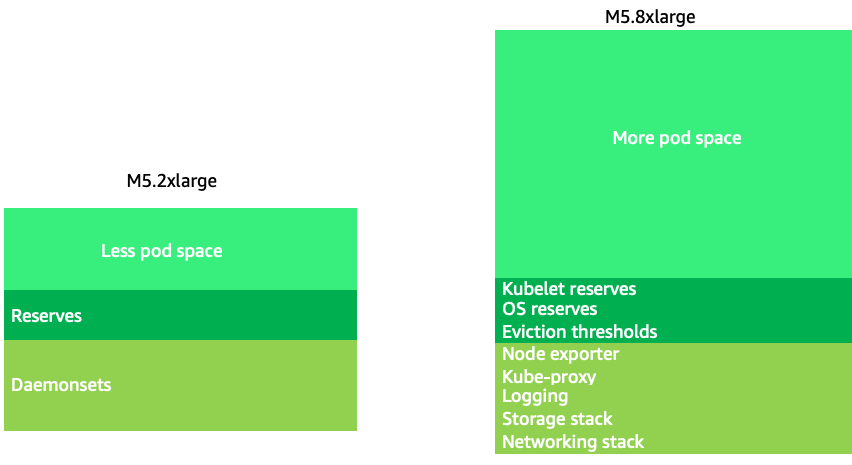
较大的节点大小允许我们在每个节点上拥有更高的可用空间百分比。但是,通过在节点上打包太多 pod 以至于会导致错误或使节点饱和,可以将此模型发挥到极致。监控节点饱和度是成功使用更大节点大小的关键。
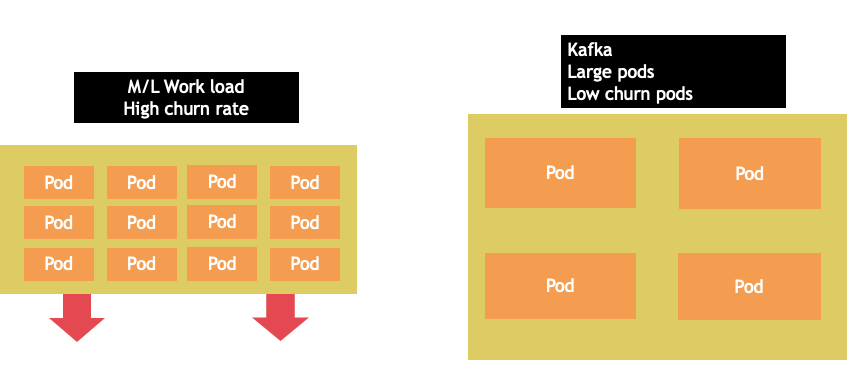
节点选择很少是一个 one-size-fits-all命题。通常,最好将流失率截然不同的工作负载分成不同的节点组。流失率高的小批量工作负载最好由 4xlarge 系列实例来处理,而 12xlarge 系列可以更好地为像 Kafka 这样的占用 8 个 vCPU 且流失率低的大型应用程序提供服务。
注意
对于非常大的节点大小,需要考虑的另一个因素是,CGROUPS 不会向容器化应用程序隐藏 vCPU 的总数。动态运行时通常会产生意外数量的操作系统线程,从而造成难以排除故障的延迟。对于这些应用程序,建议使用 CPU 固定
节点装箱
Kubernetes 与 Linux 规则
在处理 Kubernetes 上的工作负载时,我们需要注意两组规则。Kubernetes 调度器的规则,它使用请求值在节点上调度 Pod,然后在调度 pod 之后会发生什么,这是 Linux 的领域,而不是 Kubernetes 的领域。
Kubernetes 调度器完成后,一套新的规则取而代之,即 Linux 完全公平的调度器 (CFS)。关键要点是 Linux CFS 没有内核的概念。我们将讨论为什么在内核中思考会导致优化工作负载以实现规模化时出现重大问题。
在核心中思考
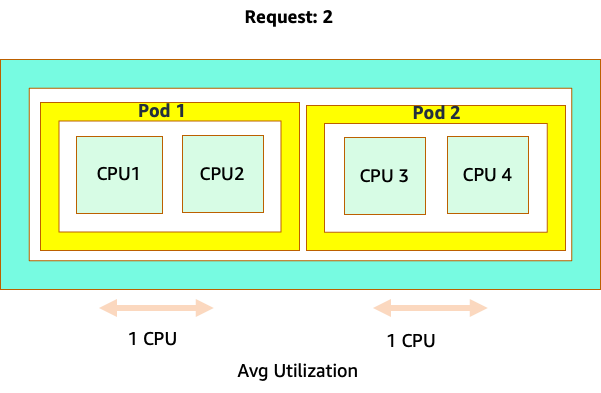
混乱之所以开始,是因为 Kubernetes 调度器确实有内核的概念。从 Kubernetes 调度器的角度来看,如果我们看一个包含 4 个 NGINX Pod 的节点,每个节点都有一个核心集的请求,那么该节点将如下所示。
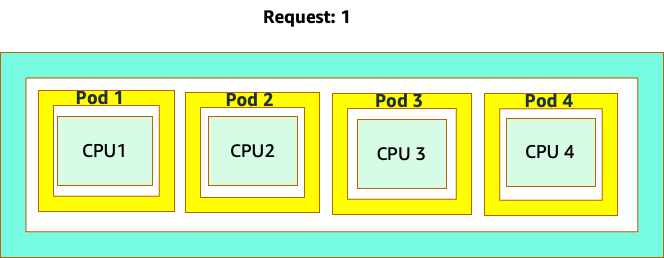
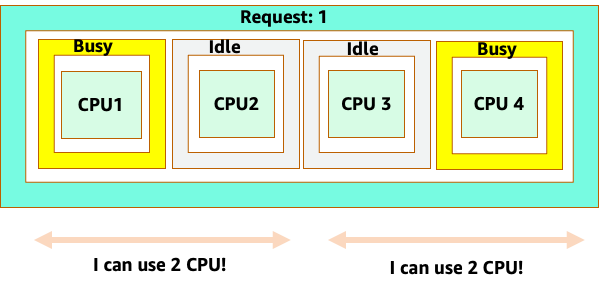
但是,让我们做一个思想实验,看看从 Linux CFS 的角度来看,这看起来有何不同。使用 Linux CFS 系统时要记住的最重要的一点是:繁忙的容器 (CGROUPS) 是唯一计入共享系统的容器。在这种情况下,只有第一个容器处于繁忙状态,因此允许它使用节点上的所有 4 个内核。
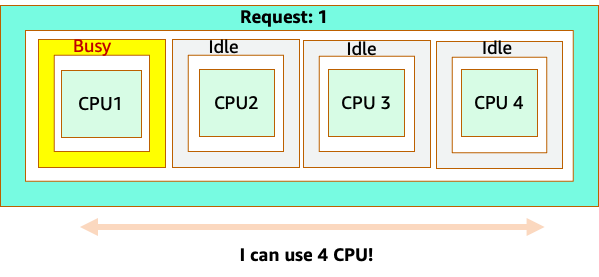
为什么这很重要? 假设我们在一个开发集群中进行了性能测试,其中 NGINX 应用程序是该节点上唯一繁忙的容器。当我们将应用程序移至生产环境时,会发生以下情况:NGINX 应用程序需要 4 个 vCPU 资源,但是,由于节点上的所有其他 pod 都处于繁忙状态,因此我们的应用程序的性能受到限制。
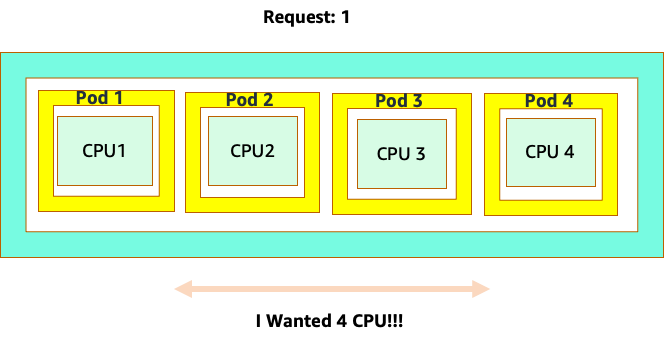
这种情况会导致我们不必要地添加更多容器,因为我们不允许我们的应用程序扩展到其 “最佳位置”。让我们更详细地探讨一下这个重要"sweet spot"的 a 概念。
正确调整应用程序大小
每个应用程序都有一个特定的点,它无法再占用流量。超过此点可能会增加处理时间,甚至在远远超过此点时会降低流量。这被称为应用程序的饱和点。为避免缩放问题,我们应该尝试在应用程序达到饱和点之前对其进行缩放。让我们称这一点为最佳位置。
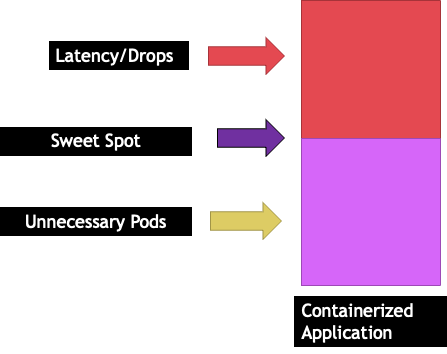
我们需要测试每个应用程序以了解其最佳位置。由于每个应用程序都不同,因此这里没有通用的指导。在这次测试中,我们试图了解显示应用程序饱和点的最佳指标。通常,利用率指标被用来表示应用程序已饱和,但这很快就会导致扩展问题(我们将在后面的章节中详细探讨这个主题)。一旦我们有了这个 “最佳位置”,我们就可以用它来有效地扩展我们的工作负载。
相反,如果我们在最佳位置之前就扩大规模并创建不必要的 pod,会发生什么? 让我们在下一节中探讨这个问题。
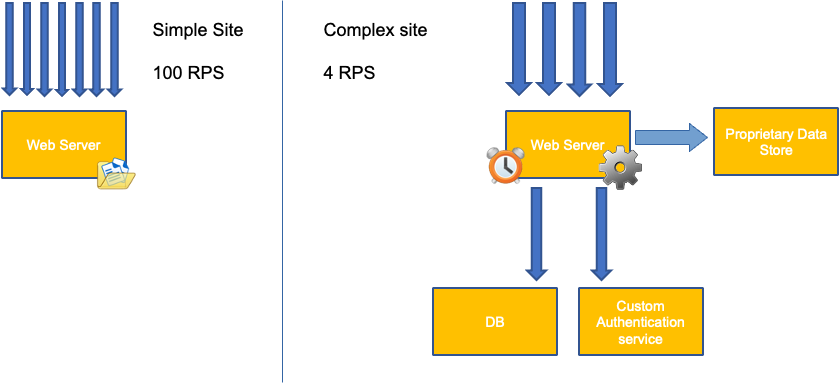
吊舱蔓延
要了解创建不必要的 pod 会如何很快失控,让我们看一下左边的第一个示例。每秒处理 100 个请求时,此容器的正确垂直缩CPUs 放会占用大约 2 v 的利用率。但是,如果我们通过将请求设置为半个内核来少调请求值,那么现在我们实际需要的每个 pod 需要 4 个 pod。更糟糕的是,如果我们的 HPA
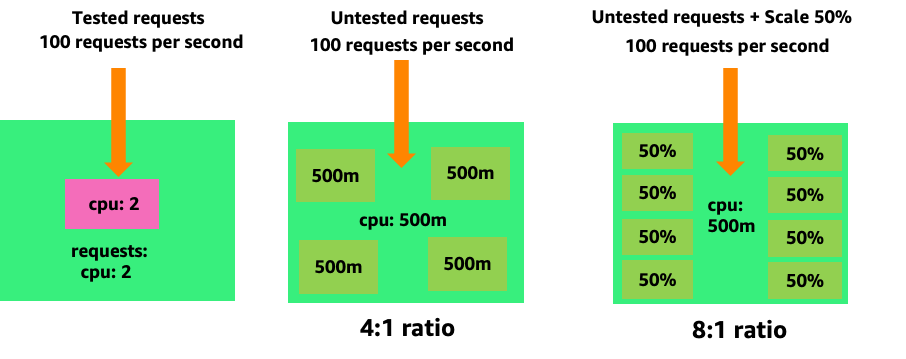
放大这个问题,我们可以很快看到这个问题是如何失控的。部署十个最佳位置设置不正确的 pod 可能会迅速上升到 80 个 pod 以及运行它们所需的额外基础架构。
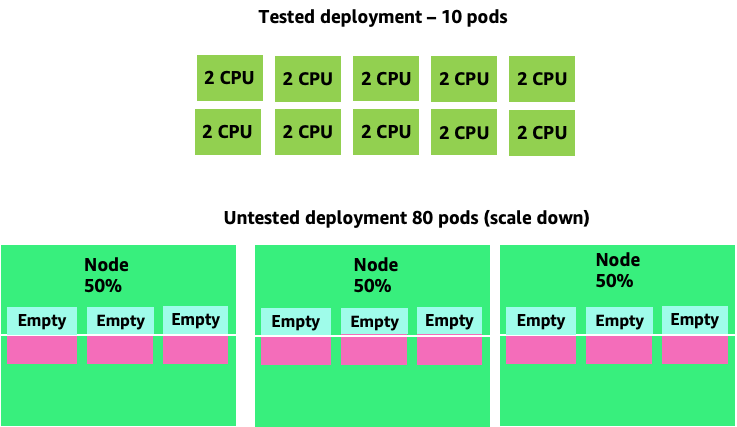
既然我们已经了解了不允许应用程序在其最佳位置运行的影响,那么让我们回到节点级别,问一下为什么 Kubernetes 调度器和 Linux CFS 之间的这种区别如此重要?
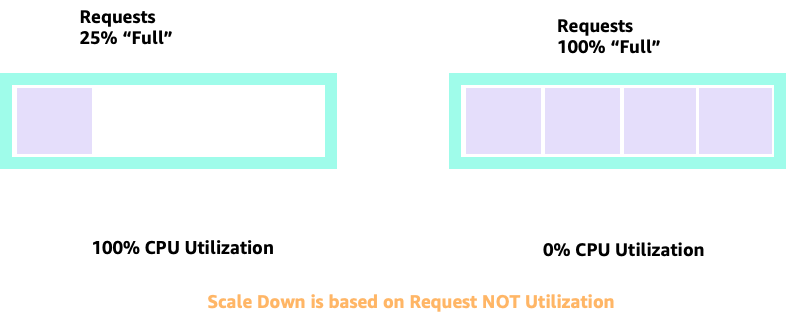
使用 HPA 向上和向下扩展时,我们可能会遇到这样一种情况:我们有足够的空间来分配更多 pod。这将是一个错误的决定,因为左边所示的节点已经达到了 100% 的 CPU 利用率。在一个不切实际但理论上可能的场景中,我们可能会遇到另一个极端,即我们的节点完全已满,但我们的 CPU 利用率为零。
设置请求
将请求设置为该应用程序的 “最佳位置” 值很诱人,但这会导致效率低下,如下图所示。这里我们将请求值设置为 2 个 vCPU,但是这些 pod 的平均利用率大部分时间仅运行 1 个 CPU。这种设置会导致我们浪费 50% 的 CPU 周期,这是不可接受的。
这使我们想到了问题的复杂答案。容器利用率不能在真空中考虑;必须考虑节点上运行的其他应用程序。在以下示例中,本质上是爆发的容器与两个可能受内存限制的 CPU 利用率低的容器混合在一起。通过这种方式,我们允许容器在不对节点造成负担的情况下达到最佳位置。
要从这一切中汲取的重要概念是,使用 Kubernetes 调度程序的内核概念来理解 Linux 容器性能可能会导致决策不佳,因为它们并不相关。
注意
Linux CFS 有其优点。对于 I/O 基于的工作负载尤其如此。但是,如果您的应用程序使用不带边车的完整内核,并且没有 I/O 要求,则CPU固定可以消除此过程中的大量复杂性,因此建议您注意这些警告。
利用率与饱和度
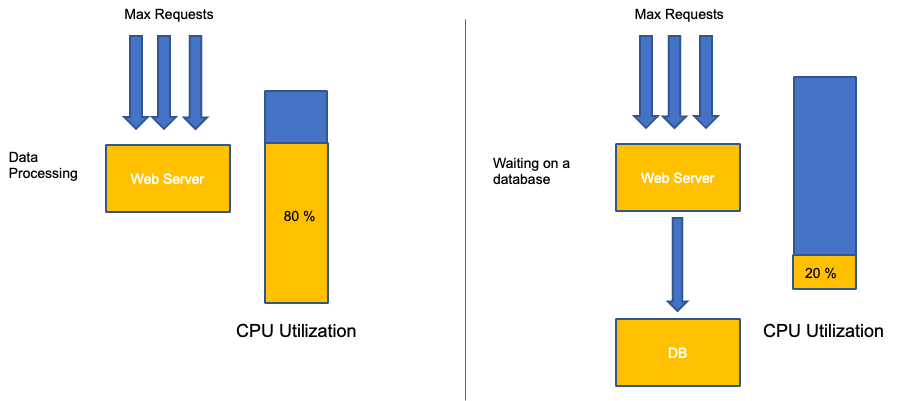
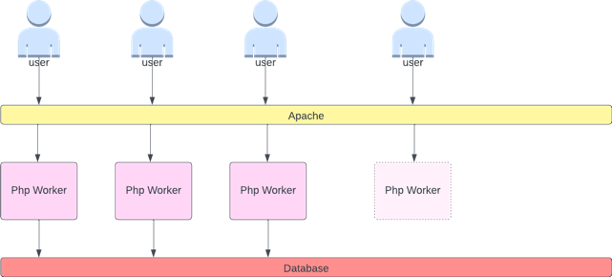
应用程序扩展中的一个常见错误是仅将 CPU 利用率作为扩展指标。在复杂的应用程序中,这几乎总是一个很差的指标,表明应用程序实际上已经充满了请求。在左边的示例中,我们看到我们所有的请求实际上都在发送 Web 服务器,因此 CPU 利用率在饱和度方面表现良好。
在现实世界的应用程序中,其中一些请求很可能会由数据库层或身份验证层等提供服务。在这种更常见的情况下,请注意 CPU 没有跟踪饱和度,因为请求是由其他实体提供服务的。在这种情况下,CPU 的饱和度指标很差。
在应用程序性能中使用错误的指标是 Kubernetes 中出现不必要和不可预测的扩展的首要原因。在为所使用的应用程序类型选择正确的饱和度指标时,必须格外小心。值得注意的是,没有可以给出 “一刀切” 的建议。根据所使用的语言和相关应用程序的类型,有各种各样的饱和度指标。
我们可能认为这个问题只出在 CPU 利用率上,但是其他常见指标(例如每秒请求数)也可能属于与上面讨论的完全相同的问题。请注意,请求也可能转到数据库层、身份验证层,而不是由我们的 Web 服务器直接提供服务,因此衡量 Web 服务器本身的真实饱和度是一个很差的指标。
不幸的是,在选择正确的饱和度指标时,没有简单的答案。以下是一些需要考虑的指导方针:
-
了解您的语言运行时——具有多个操作系统线程的语言的反应与单线程应用程序不同,因此对节点的影响也不同。
-
了解正确的垂直缩放比例——在缩放新 pod 之前,你想在应用程序的垂直比例中放多少缓冲区?
-
哪些指标能真正反映应用程序的饱和度-Kafka Producer 的饱和度指标将与复杂的 Web 应用程序大不相同。
-
节点上的所有其他应用程序如何相互影响-应用程序性能不是在真空中完成的,节点上的其他工作负载会产生重大影响。
为了结束本节,很容易将上述内容视为过于复杂和不必要。我们经常会遇到问题,但我们没有意识到问题的真正本质,因为我们看错了指标。在下一节中,我们将探讨如何发生这种情况。
节点饱和度
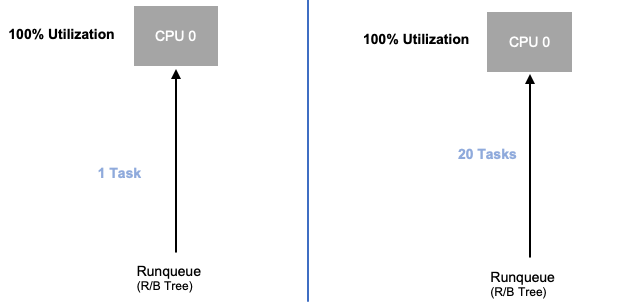
现在我们已经探讨了应用程序饱和度,让我们从节点的角度来看同样的概念。让我们以两个 CPUs 100% 利用率为例,看看利用率与饱和度之间的区别。
左边的 vCPU 利用率为 100%,但是没有其他任务等待在这个 vCPU 上运行,因此从纯粹的理论意义上讲,这非常高效。同时,在第二个示例中,我们有 20 个单线程应用程序等待由 vCPU 处理。现在,所有 20 个应用程序在等待轮到 vCPU 处理时都会遇到某种类型的延迟。换句话说,右边的 vCPU 已饱和。
如果我们只看利用率,我们不仅不会看到这个问题,而且我们可能会将这种延迟归因于不相关的东西,例如网络,这会导致我们走上错误的道路。
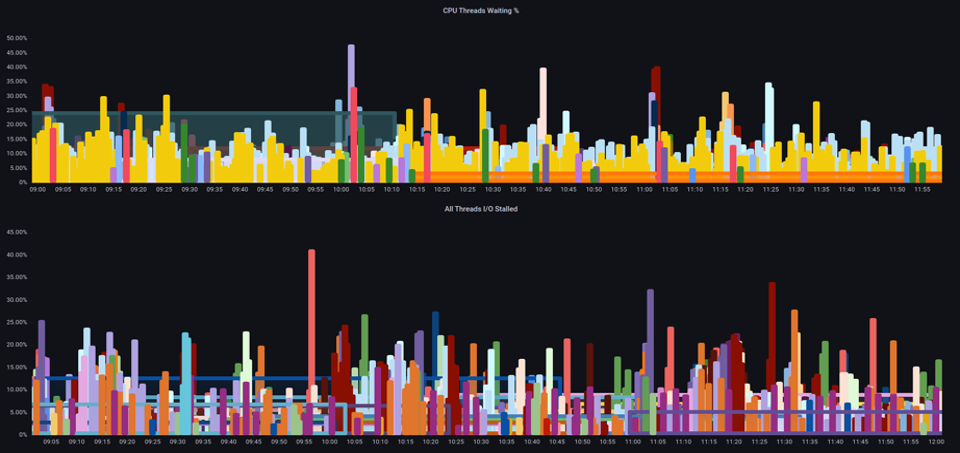
在任何给定时间增加节点上运行的 Pod 总数时,重要的是要查看饱和度指标,而不仅仅是利用率指标,因为我们很容易忽略节点过饱和的事实。对于此任务,我们可以使用压力失速信息指标,如下图所示。
PromQL-I/O 停滞不前
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
注意
有关压力失速指标的更多信息,请参阅 https://facebookmicrosites.github。 io/psi/docs/overview
通过这些指标,我们可以判断线程是否在 CPU 上等待,或者即使盒子上的每个线程都停滞不前,等待内存等资源还是在 1 分钟I/O. For example, we could see what percentage every thread on the instance was stalled waiting on I/O内停滞不前。
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
使用这个指标,我们可以在上面的图表中看到,盒子上的每个线程在最高水位等候的时间中有45%的时间 I/O 处于停滞状态,这意味着我们在那一分钟内浪费了所有CPU周期。了解这种情况的发生可以帮助我们节省大量的 vCPU 时间,从而提高扩展效率。
HPA V2
建议使用 HPA API 的自动缩放/v2 版本。在某些边缘情况下,旧版本的 HPA API 可能会卡住扩展。它还被限制为 pod 在每个扩展步骤中只能翻一番,这给需要快速扩展的小型部署带来了问题。
AutoScaling/v2 使我们能够更灵活地包含多个标准来进行扩展,并在使用自定义和外部指标(非 K8s 指标)时为我们提供了极大的灵活性。
例如,我们可以按三个值中最高的值进行缩放(见下文)。如果所有 pod 的平均利用率超过 50%,如果自定义指标每秒入口的数据包平均超过 1,000 个,或者入口对象超过每秒 1 万个请求,我们就会进行扩展。
注意
这只是为了展示自动缩放 API 的灵活性,我们建议不要使用在生产中难以排除故障的过于复杂的规则。
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
但是,我们了解了将此类指标用于复杂的 Web 应用程序的危险。在这种情况下,使用能够准确反映应用程序饱和度与利用率相比的自定义或外部指标可以更好地为我们服务。 HPAv2 通过能够根据任何指标进行扩展来实现这一点,但是我们仍然需要找到该指标并将其导出到 Kubernetes 以供使用。
例如,我们可以查看 Apache 中的活动线程队列数。这通常会创建一个 “更平滑” 的缩放配置文件(稍后会详细介绍该术语)。如果线程处于活动状态,则无论该线程是在数据库层等待还是在本地处理请求,如果所有应用程序线程都在使用中,则很好地表明应用程序已饱和。
我们可以使用这种线程耗尽作为信号,创建一个线程池完全可用的新 pod。这也使我们能够控制在流量繁忙时要在应用程序中吸收多大的缓冲区。例如,如果我们的线程池总数为 10,则按使用的 4 个线程而不是使用的 8 个线程进行扩展将对我们在扩展应用程序时可用的缓冲区产生重大影响。对于需要在重负载下快速扩展的应用程序来说,设置为 4 是有意义的,如果我们有足够的时间进行扩展,因为请求数量的增长缓慢而不是随着时间的推移而急剧增加,那么如果我们有足够的时间进行扩展,那么设置为 8 会更有效地利用我们的资源。
在缩放方面,“平滑” 一词是什么意思? 请注意下图,其中我们使用 CPU 作为指标。此部署中的 pod 将在短时间内激增,从 50 个 pod 一直到 250 个 pod,然后立即再次缩小。这是效率极低的扩展是集群流失的主要原因。
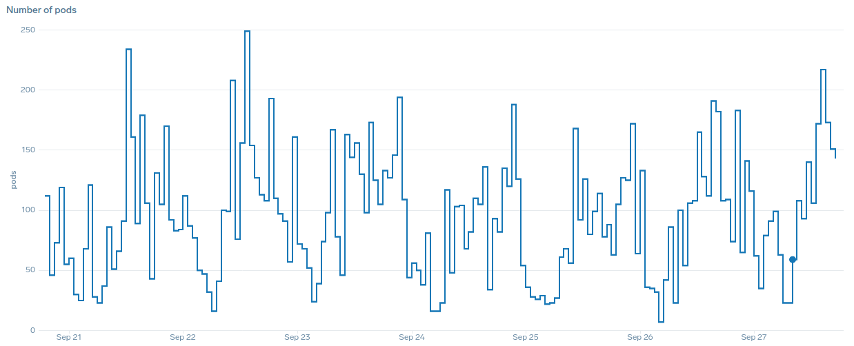
请注意,在我们更改为反映应用程序正确最佳位置的指标(图表的中间部分)之后,我们如何能够平稳地进行扩展。现在,我们的缩放效率很高,我们的 pod 可以根据我们通过调整请求设置提供的余量进行完全扩展。现在,一小群吊舱正在做以前数百个吊舱所做的工作。现实世界的数据表明,这是 Kubernetes 集群可扩展性的首要因素。
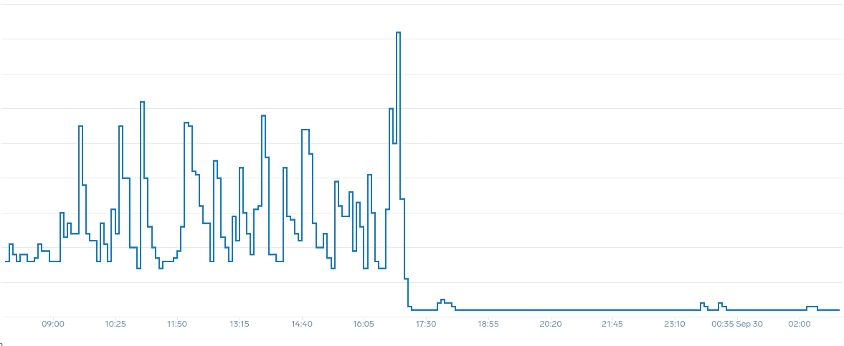
关键要点是 CPU 利用率只是应用程序和节点性能的一个维度。使用 CPU 利用率作为节点和应用程序的唯一运行状况指标会带来扩展、性能和成本方面的问题,这些都是紧密联系的概念。应用程序和节点的性能越高,需要扩展的次数就越少,这反过来又会降低成本。
通过查找和使用正确的饱和度指标来扩展您的特定应用程序,您还可以监控该应用程序的真正瓶颈并发出警报。如果跳过这一关键步骤,将很难甚至不可能理解有关性能问题的报告。
设置 CPU 限制
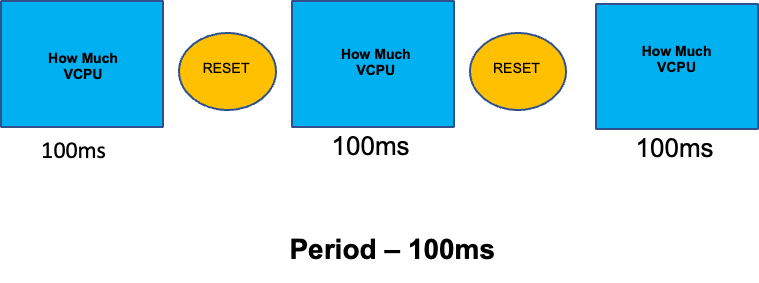
为了完善本节关于被误解的话题,我们将介绍 CPU 限制。简而言之,限制是与容器关联的元数据,该容器具有每 100 毫秒重置一次的计数器。这有助于 Linux 跟踪特定容器在 100 毫秒的时间段内在节点范围内使用了多少 CPU 资源。
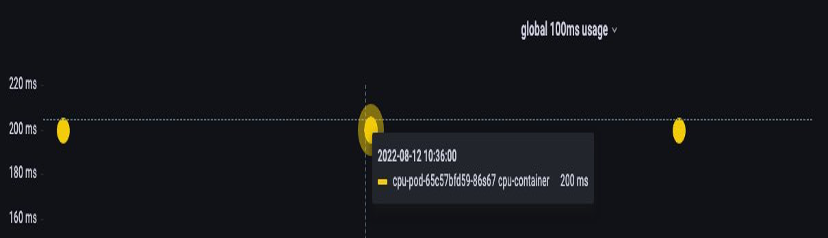
设置限制时的一个常见错误是假设应用程序是单线程的,并且只能在其 “`分配的” vCPU上运行。在上一节中,我们了解到 CFS 不分配内核,实际上,运行大型线程池的容器将在盒子上所有可用的 vCPU 上进行调度。
如果 64 个操作系统线程在 64 个可用内核上运行(从 Linux 节点的角度来看),则在将所有 64 个内核上的运行时间相加后,我们将在将 100 毫秒内的 CPU 使用时间总账单计算得相当大。由于这可能只发生在垃圾收集过程中,因此很容易错过这样的事情。这就是为什么在尝试设置限制之前,有必要使用指标来确保随着时间的推移我们有正确的使用情况。
幸运的是,我们可以准确地看到应用程序中所有线程使用了多少 vCPU。我们将使用该指标来container_cpu_usage_seconds_total实现此目的。
由于限制逻辑每 100 毫秒发生一次,并且该指标是每秒的指标,因此我们将 PromQL 与这个 100 毫秒周期相匹配。如果您想深入了解这个 PromQL 语句的工作原理,请参阅以下博客
PromQL 查询:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

一旦我们觉得自己有正确的价值,我们就可以限制生产。然后,有必要查看我们的应用程序是否由于意外情况而受到限制。我们可以通过看一下来做到这一点 container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
内存
内存分配是另一个很容易将 Kubernetes 调度行为与 Linux 行为混为一谈的例子。 CGroup 这是一个更加细致入微的话题,因为 CGroup v2 在 Linux 中处理内存的方式发生了重大变化,而 Kubernetes 也更改了语法以反映这一点;阅读此博客了解更多详情。
与 CPU 请求不同,在调度过程完成后,内存请求将处于未使用状态。这是因为我们无法像使用 CPU 那样在 CGroup v1 中压缩内存。这只给我们留下了内存限制,这些限制旨在通过完全终止 pod 来保护内存泄漏。这是一个全有要么全有要么全无的风格主张,但是我们现在有了解决这个问题的新方法。
首先,重要的是要明白,为容器设置正确的内存量并不像看上去那样简单。Linux 中的文件系统将使用内存作为缓存来提高性能。这种缓存会随着时间的推移而增长,很难知道有多少内存可以用来存放缓存,但是可以在不对应用程序性能产生重大影响的情况下回收多少内存。这通常会导致对内存使用情况的误解。
具有 “压缩” 内存的能力是 CGroup v2 背后的主要驱动力之一。有关为何需要 CGroup V2 的更多历史记录,请参阅 Chris Down 的演讲
幸运的是,Kubernetes 现在有了 “和” 之下的概念。memory.min memory.high requests.memory这使我们可以选择主动释放缓存的内存供其他容器使用。一旦容器达到内存上限,内核就可以积极回收该容器的内存,最高可达设置为的值。memory.min因此,当节点承受内存压力时,我们可以获得更大的灵活性。
关键问题变成了,memory.min要设置为什么值? 这就是内存压力失速指标发挥作用的地方。我们可以使用这些指标来检测容器级别的内存 “抖动”。然后,我们可以使用诸如 fbtaxmemory.min通过查找内存抖动来检测正确的值,并将该memory.min值动态设置为该设置。
摘要
总而言之,可以很容易地将以下概念混为一谈:
-
利用率和饱和度
-
使用 Kubernetes 调度器逻辑的 Linux 性能规则
必须格外小心,将这些概念分开。性能和规模在深层次上是相互关联的。不必要的缩放会造成性能问题,进而造成扩展问题。
