任务编辑器功能
任务编辑器提供以下功能,用于创建和编辑任务。
-
任务的可视图,每个任务任务都有一个节点:用于读取数据的数据源节点;用于修改数据的转换节点;用于写入数据的数据目标节点。
您可以查看和配置任务图中每个节点的属性。您还可以查看任务图中每个节点的架构和示例数据。这些功能可帮助您验证任务是否正在以正确的方式修改和转换数据,而无需运行任务。
-
Script viewing and editing (脚本查看和编辑) 选项卡,您可以在其中修改为任务生成的代码。
-
Job details (任务详细信息) 选项卡,您可以在其中配置各种设置,自定义 AWS Glue ETL 任务的运行环境。
Runs (运行) 选项卡,您可以在其中查看任务的当前运行和上一次运行,查看任务运行的状态,以及访问任务运行的日志。
-
“数据质量”选项卡,您可以在其中将数据质量规则应用于您的作业。
-
Schedules (计划) 选项卡,您可以在其中配置任务的开始时间,或设置定期任务运行。
-
“版本控制”选项卡,您可以在其中配置 Git 服务以用于您的作业。
在可视任务编辑器中使用架构预览
创建或编辑任务时,您可以使用 Output schema (输出架构) 选项卡查看数据的架构。
在查看架构之前,任务编辑器需要数据源的访问权限。您可以在编辑器的 Job details (任务详细信息) 选项卡上或者节点的 Output schema (输出架构) 选项卡上指定 IAM 角色。如果 IAM 角色具有数据源的所有必要访问权限,您可以在节点的 Output schema (输出架构) 选项卡上查看架构。
在可视任务编辑器中使用数据预览
数据预览有助于您使用数据样本来创建和测试任务,而无需重复运行作业。借助数据预览,您可以:
-
测试 IAM 角色以确保您有权访问您的数据来源或数据目标。
-
检查转换功能是否在以预期的方式修改数据。例如,如果您使用筛选条件转换,则可以确保筛选条件正在选择合适的数据子集。
-
检查数据。如果数据集包含具有多种类型值的列,则数据预览会显示这些列的元组列表。每个元组都包含数据类型及其值。
注意
如果使用数据预览会话和自定义 SQL 或自定义代码节点,则数据预览会话将按原样对整个数据集执行 SQL 或代码块。
创建或编辑作业时,您可以使用作业画布下方的数据预览选项卡查看数据示例。如果作业中已经配置了该角色或账户中已设置了默认的 IAM 角色,则将自动启动新的数据预览会话。如果之前未配置过任何角色,则可以选择该角色以启动会话。
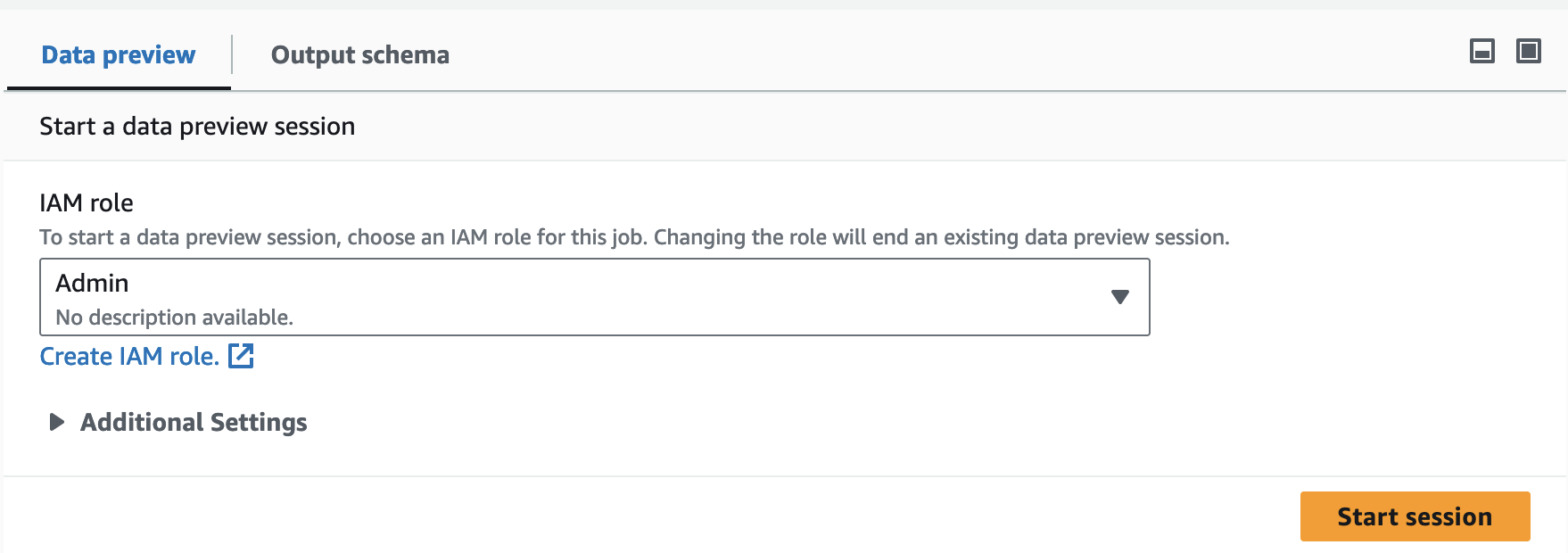
注意
您为数据预览会话选择的角色也将用于该作业。
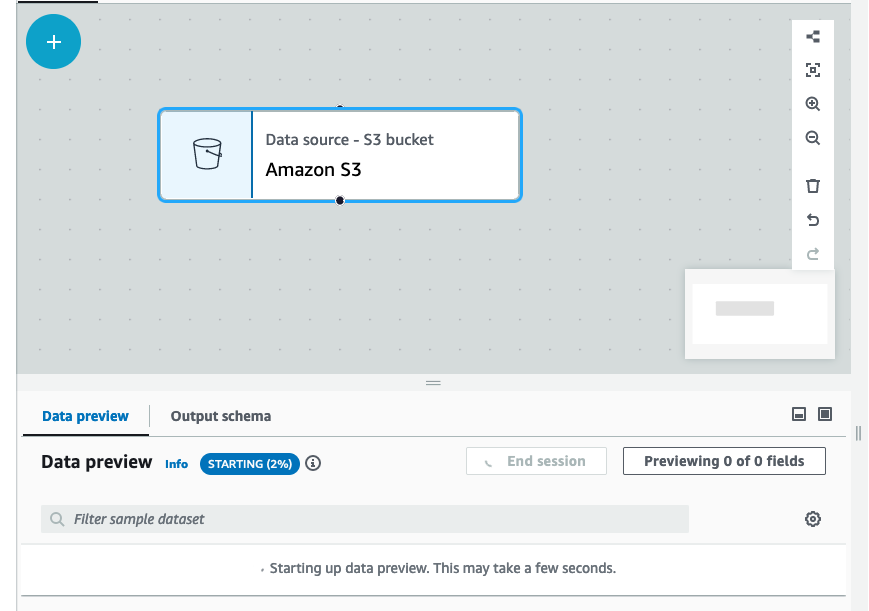
您可以单击信息图标来查看会话的状态和进度,以及会话的详细信息。
会话准备就绪后,AWS Glue Studio 将加载所选节点的数据。您可以在加载过程中查看完成百分比。
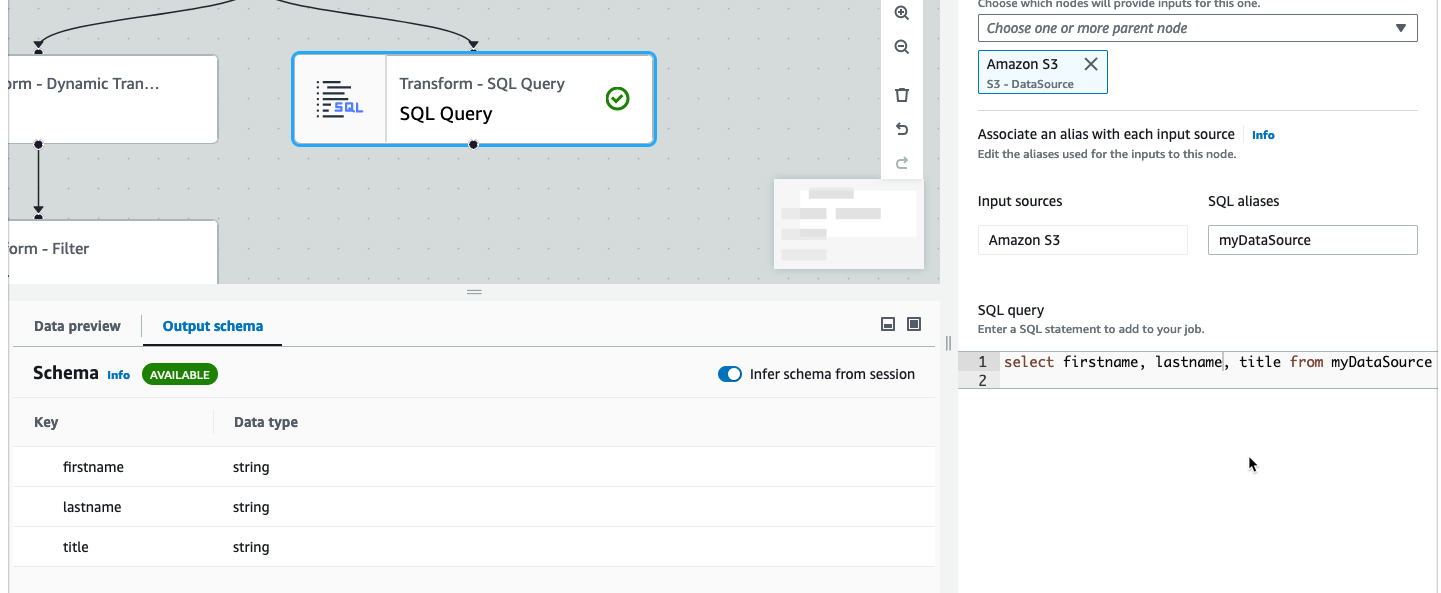
在编写可视化作业过程中,当您在输出 Schema 选项卡中切换从会话推断 Schema 时,AWS Glue Studio 将自动更新所选节点的 Schema。
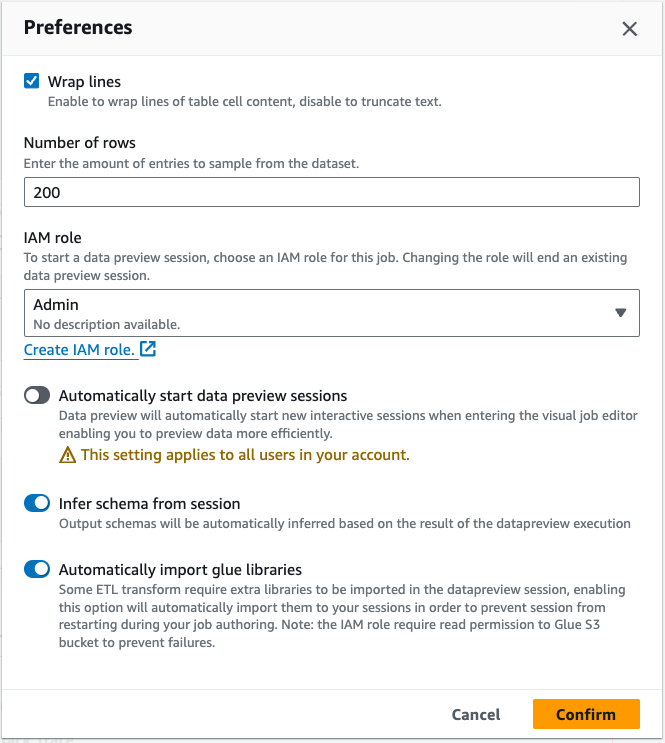
配置数据预览首选项:
选择设置图标(齿轮符号)以配置数据预览的首选项。这些设置适用于任务图中的所有节点。您可以:
-
选择此选项以将文本换行。此选项将默认启用
-
更改行数(默认为 200)
-
选择一个 IAM 角色或根据需要创建一个 IAM 角色
-
选择此选项以在编写作业时自动启动新会话。这将在编写作业时预置新的交互式会话。此设置适用于账户级别。设置完成后,在编辑任何作业时,它将适用于账户中的所有用户。
-
选择自动推断 Schema。系统将自动推断所选节点的输出 Schema
-
选择此选项以自动导入 AWS Glue 库。此功能非常实用,因为可以在添加需要重新启动会话的新转换时防止数据预览重新启动新会话
其他功能包括:
-
选择 Previewing x of y fields (预览 y 个字段中的 x 个字段) 按钮,选择要预览的列(字段)。您使用默认设置预览数据时,任务编辑器会显示数据集的前 5 列。您可以更改此选项以显示全部或不显示(不推荐)。
-
水平和垂直滚动浏览数据预览窗口。
-
使用最大化按钮展开“数据预览”选项卡展以叠加任务图,以便更好地查看数据和数据结构。同样,使用最小化按钮最小化“数据预览”选项卡。您也可以抓住手柄窗格并向上拖动以展开数据预览选项卡。
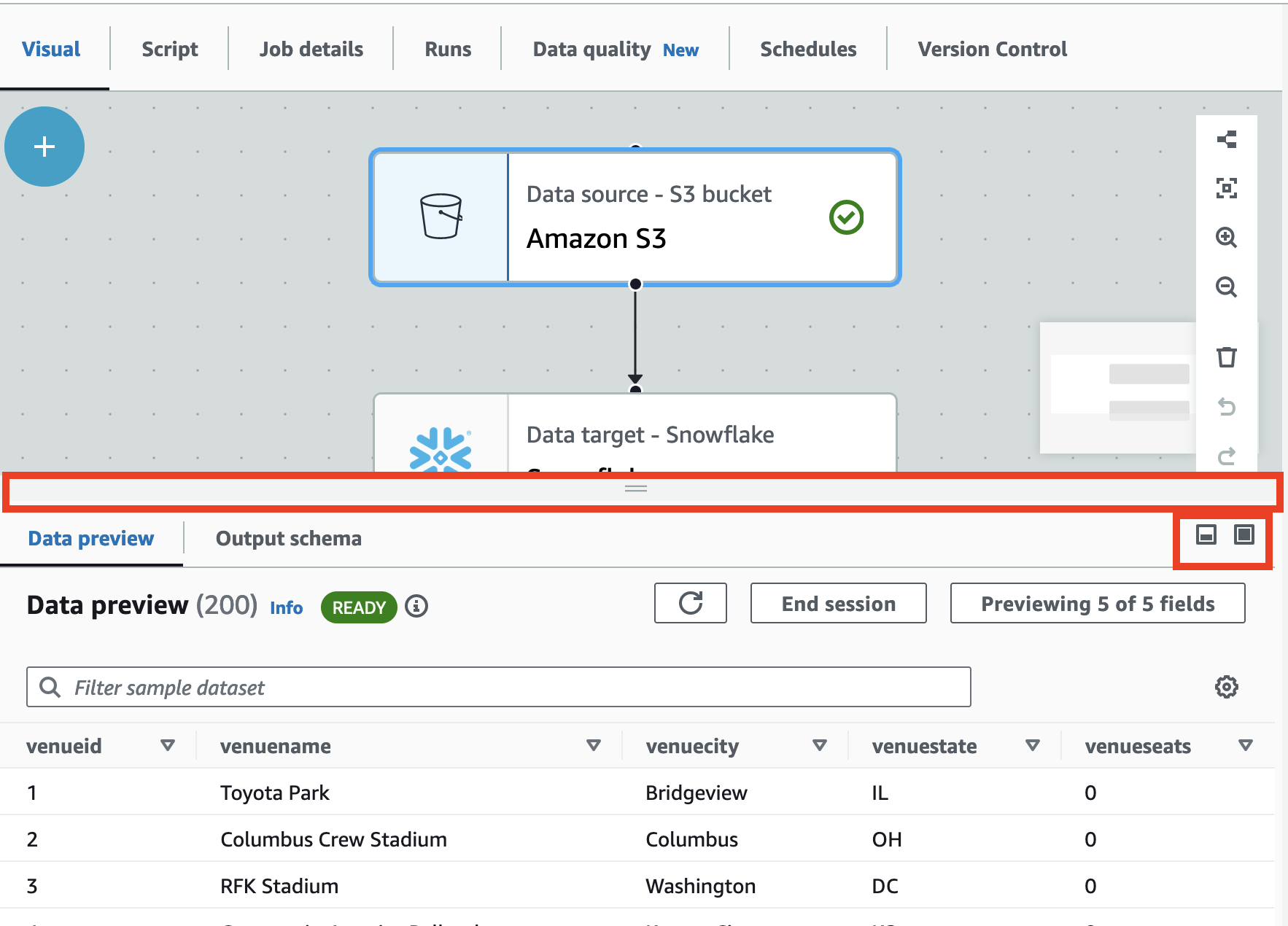
-
使用结束会话停止数据预览。停止会话后,您可以选择新的 IAM 角色,并设置其他设置(例如开启或关闭设置)以自动启动新会话、推断架构或导入 AWS Glue 库,然后重新启动会话。
使用数据预览时的限制
使用数据预览时,您可能会遇到以下限制。
-
您首次选择 Data preview (数据预览) 选项卡时,您必须选择 IAM 角色。此角色必须有权访问创建数据预览所需的数据和其他资源。
-
提供 IAM 角色后,需要一段时间才能查看数据。对于数据少于 1GB 的数据集,可能最多需要一分钟。如果您拥有较大的数据集,则应使用分区来缩短加载时间。直接从 Amazon S3 加载数据可以实现更出色的性能。
-
如果您拥有非常大的数据集,并且查询用于数据预览的数据需要 15 分钟以上,则请求将超时。数据预览有 30 分钟的空闲超时。要缓解此情况,请减小数据集大小以使用数据预览。
-
默认情况下,您可以查看“数据预览”选项卡中的前 50 列。如果列没有数据值,您将收到一条消息,指明没有要显示的数据。您可以增加采样的行数,也可以选择不同的列来查看数据值。
-
数据预览当前不支持流式处理数据源或使用自定义连接器的数据源。
-
一个节点上的错误会影响整个任务。如果任何一个节点在数据预览中出现错误,则该错误将在所有节点上显示,直到您更正。
-
如果更改任务的数据源,您可能需要更新该数据源的子节点以匹配新架构。例如,如果您有用于修改列的 ApplyMapping 节点,并且该列不存在于替换数据源中,您需要更新 ApplyMapture 转换节点。
-
如果您查看 SQL 查询转换节点的 Data preview (数据预览) 选项卡,并且 SQL 查询使用不正确的字段名称,则 Data preview (数据预览) 选项卡将显示错误。
脚本代码生成
使用可视化编辑器创建任务时,将自动为您生成 ETL 代码。AWS Glue Studio 会创建功能完整的任务脚本,并将其保存在 Amazon S3 位置。
AWS Glue Studio 生成的代码有两种形式:原始版本,即经典版本,以及更新的精简版本。预设情况下,会使用新的代码生成器创建任务脚本。选择 Generate classic script(生成经典脚本)切换按钮,就可以使用 Script(脚本)选项卡上的经典代码生成器生成任务脚本。
生成的新版本代码中的一些差异包括:
-
大型的注释数据块将不再添加到脚本中
-
代码中的输出结构将使用您在可视化编辑器中指定的节点名称。在类脚本中,输出结构将简单地命名为
DataSource0、DataSource1、Transform0、Transform1、DataSink0、DataSink1等。 -
长命令将拆分为多行,以免滚动页面才能查看整条命令。
AWS Glue Studio 中的新功能需要新版本的代码生成,并且不适用于经典代码脚本。尝试运行这些任务时,系统会提示您更新。
