排查 Lambda 配置问题
内存配置
您可以将 Lambda 函数配置为使用 128 MB 与 10240 MB 之间的内存。默认情况下,为在控制台中创建的任何函数都分配了最小量的内存。虽然许多 Lambda 函数在此最低设置下性能良好,但如果您要导入大型代码库或完成内存密集型任务,则 128 MB 是不够的。
如果函数的运行速度比预期慢得多,则第一步是增加内存设置。对于内存受限函数,这将解决瓶颈问题,且可以提高函数性能。
CPU 受限配置
对于计算密集型操作,如果您的 Lambda 函数性能低于预期,则这可能是由于您的函数受 CPU 限制。在这种情况下,函数的计算能力无法跟上工作进度。
虽然 Lambda 配置中没有直接暴露的 CPU 配置,但这是通过内存设置间接控制。当您分配更多内存时,Lambda 服务会按比例分配更多虚拟 CPU。内存为 1.8 GB 时,Lambda 函数会分配整个 vCPU,而在此级别以上,它可以访问多个 vCPU 核心。在 10240 MB 时,有 6 个可用的 vCPU。
在这些情况下,即使函数没有使用所有内存,您也可以通过增加内存分配来提高性能。
超时
Lambda 函数的超时可以设置在 1 到 900 秒(15 分钟)之间,Lambda 控制台默认为 3 秒。超时值是一个安全缓冲区,用于结束永不退出的函数以继续无限期地运行。一旦达到超时值,Lambda 服务便会停止该函数。
如果将超时值设置得接近函数的平均持续时间,则会增加函数意外超时的风险。函数的持续时间可能因数据传输和处理量以及与该函数交互的任何服务的延迟而不同。导致超时的一些常见原因包括:
-
从 S3 存储桶或其他数据存储下载数据时,下载量会比平均值更大或花费更长时间。
-
一个函数向另一项服务发出请求,这需要更长的时间才能响应。
-
提供给函数的参数要求函数具有更高的计算复杂度,这会导致调用花费更长的时间。
在文档存储库示例

-
随着 PDF 文件大小的增长,处理这种格式的 npm 库需要更长时间。PDF 的处理时间有一个上限,超过此上限则需要 3 秒以上时间。
-
媒体二进制文件(例如 JPG 文件)可能非常大。存在一个上限,超过该上限后,从 S3 存储桶下载文件所需的时间超过 3 秒。
-
在处理 JPG 文件时,Amazon Rekognition 需要更长时间来处理较大的对象和更复杂的对象。此项服务可能需要 3 秒以上的时间才能响应。
超时是一种安全机制,在正常运行中不会对成本产生负面影响,因为 Lambda 服务按持续时间收费。请确保您的超时值设置得不要太接近函数的平均持续时间,以避免意外超时。
在测试应用程序时,请确保您的测试准确反映数据的大小和数量以及真实的参数值。为方便起见,测试通常使用少量样本,但您应该在您的工作负载合理预期值的上限使用数据集。
在可行的情况下,对工作负载实施上限限制。在本示例中,应用程序可以对每种文件类型使用最大大小限制。然后,您可以针对一系列的预期文件大小(达到并包括最大限制)来测试应用程序的性能。
两次调用之间的内存泄漏
Lambda 调用的 INIT 阶段中存储的全局变量和对象在暖调用之间保留其状态。只有在执行环境首次运行时(也称为“冷启动”),它们才会完全重置。处理程序退出时,存储在处理程序中的任何变量都会销毁。最佳实践是使用 INIT 阶段来设置数据库连接、加载库、创建缓存和加载不可变资产。
在同一执行环境中跨多个调用使用第三方库时,务必查看其文档以了解在无服务器计算环境中的使用情况。某些数据库连接和日志记录库可能会保存中间调用结果和其他数据。这会导致这些库的内存使用量随着随后的暖调用而增长。在内存快速增长的情况下,即使您的自定义代码正确处理了变量,您也可能会发现 Lambda 函数的内存不足。
此问题会影响在暖执行环境中发生的调用。例如,以下代码会在两次调用之间产生内存泄漏。Lambda 函数通过增加全局数组的大小,每次调用都会占用额外的内存:
let a = []
exports.handler = async (event) => {
a.push(Array(100000).fill(1))
}
配置了 128 MB 内存,在调用此函数 1000 次后,Lambda 函数的“监控”选项卡会显示在发生内存泄漏时调用、持续时间和错误计数的典型变化:
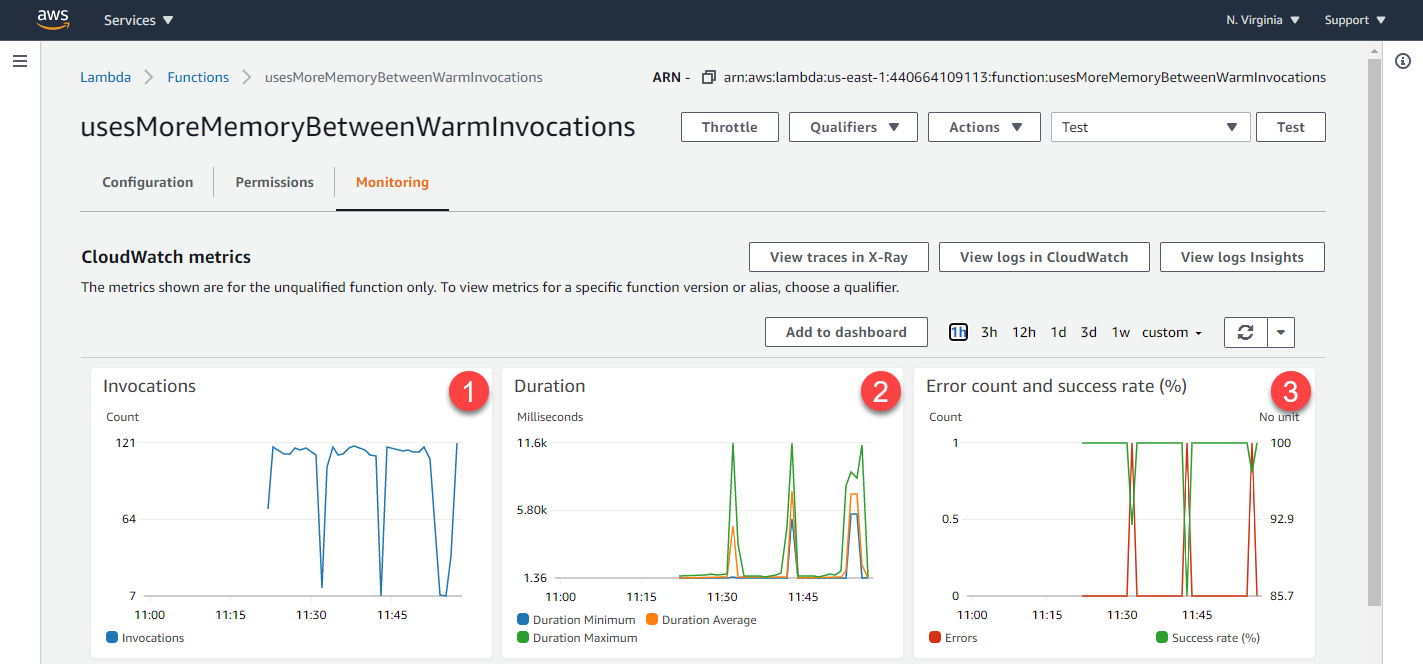
-
调用:由于调用需要更长时间才能完成,因此会定期中断稳定的事务速率。在稳定状态期间,内存泄漏不会使用函数分配的所有内存。随着性能下降,操作系统会对本地存储进行分页以适应函数所需的不断增长的内存,从而减少要完成的事务量。
-
持续时间:在函数的内存不足之前,它会以稳定的两位数毫秒速率完成调用。随着分页的发生,持续时间会延长一个数量级。
-
错误计数:由于内存泄漏超出分配的内存,最终函数因计算超出超时而出错,或者执行环境停止该函数。
错误发生后,Lambda 服务会重新启动执行环境,这解释了为什么所有三个图表中的指标都恢复到原始状态。扩展 CloudWatch 持续时间指标可提供最短、最大和平均持续时间统计数据的更多详细信息:
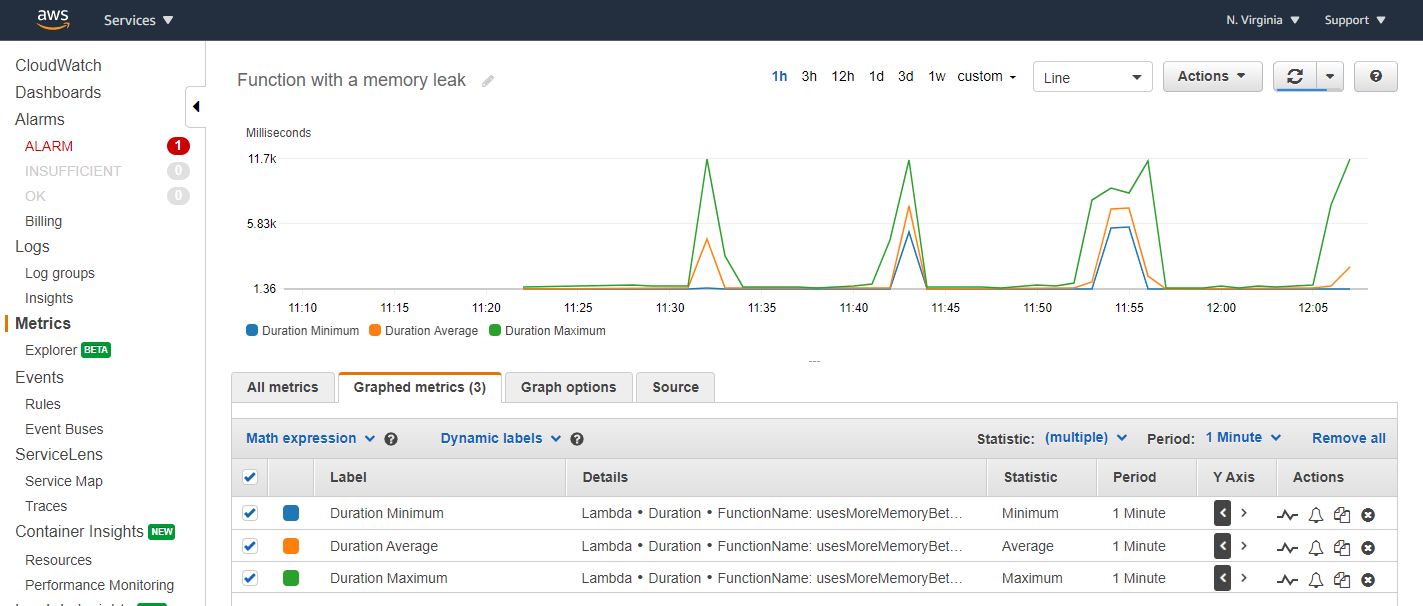
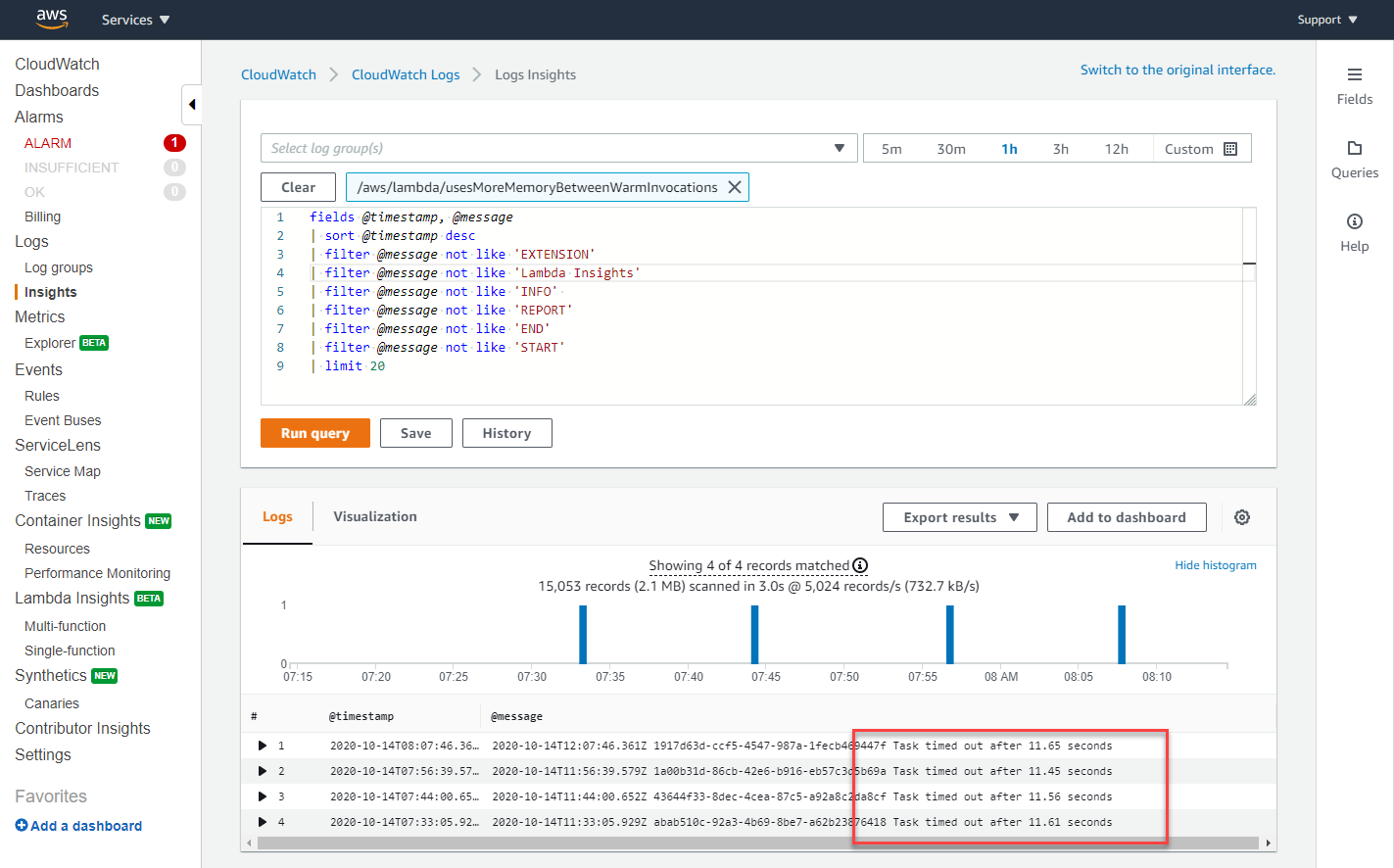
要查找在 1000 次调用中所生成的错误,您可以使用 CloudWatch Insights 查询语言。以下查询排除信息日志,以仅报告错误:
fields @timestamp, @message | sort @timestamp desc | filter @message not like 'EXTENSION' | filter @message not like 'Lambda Insights' | filter @message not like 'INFO' | filter @message not like 'REPORT' | filter @message not like 'END' | filter @message not like 'START'
针对此函数的日志组运行时,这表明超时是造成周期性错误的原因:
返回给以后调用的异步结果
对于使用异步模式的函数代码,一次调用的回调结果可能会在未来调用中返回。此示例使用 Node.js,但相同逻辑可以应用于使用异步模式的其他运行时。该函数使用 JavaScript 中传统的回调语法。它调用一个带有增量计数器的异步函数,用于跟踪调用次数:
let seqId = 0 exports.handler = async (event, context) => { console.log(`Starting: sequence Id=${++seqId}`) doWork(seqId, function(id) { console.log(`Work done: sequence Id=${id}`) }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
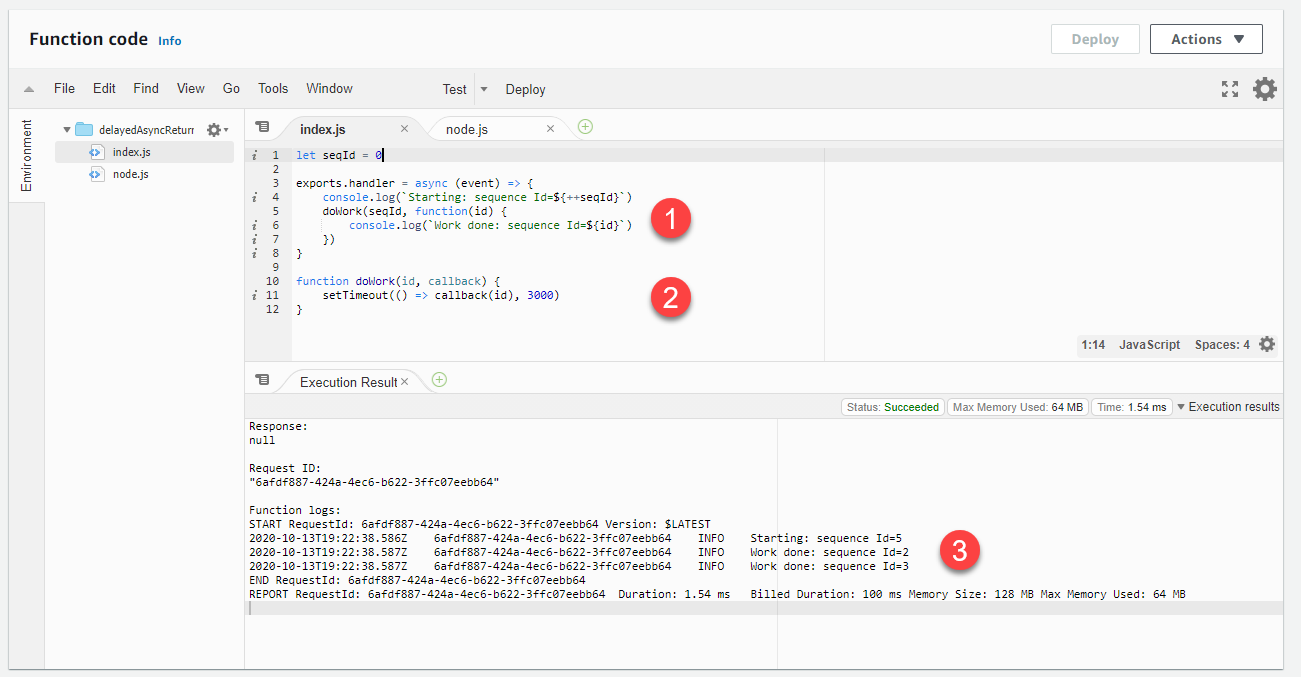
连续多次调用时,回调的结果会出现在后续调用中:
-
代码调用 doWork 函数,提供回调函数作为最后一个参数。
-
在调用回调之前,doWork 函数需要一段时间来完成。
-
该函数的日志记录表明调用将在 doWork 函数完成执行之前结束。此外,在开始迭代之后,将处理先前迭代的回调,如日志所示。
在 JavaScript 中,异步回调通过事件循环
这使得前一次调用的私有数据有可能出现在后续调用中。有两种方法可防止或检测此行为。首先,JavaScript 提供了 async 和 await 关键字
let seqId = 0 exports.handler = async (event) => { console.log(`Starting: sequence Id=${++seqId}`) const result = await doWork(seqId) console.log(`Work done: sequence Id=${result}`) } function doWork(id) { return new Promise(resolve => { setTimeout(() => resolve(id), 4000) }) }
使用此语法可防止处理程序在异步函数完成之前退出。在这种情况下,如果回调的时间超过 Lambda 函数的超时时间,则该函数将引发错误,而不是在以后的调用中返回回调结果:

-
该代码在处理程序中使用 await 关键字调用异步 doWork 函数。
-
在解析 promise 之前,doWork 函数需要一段时间才能完成。
-
该函数超时,因为 doWork 花费的时间超过了超时限制允许的时间,并且在以后的调用中不会返回回调结果。
通常,您应确保代码中的任何后台进程或回调在代码退出前已完成。如果在您的使用案例中无法做到这一点,您可以使用标识符来确保回调属于当前调用。为此,您可以使用上下文对象所提供的 awsRequestId。通过将此值传递给异步回调,您可以将传递的值与当前值进行比较,以检测回调是否来自另一个调用:
let currentContext exports.handler = async (event, context) => { console.log(`Starting: request id=$\{context.awsRequestId}`) currentContext = context doWork(context.awsRequestId, function(id) { if (id != currentContext.awsRequestId) { console.info(`This callback is from another invocation.`) } }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
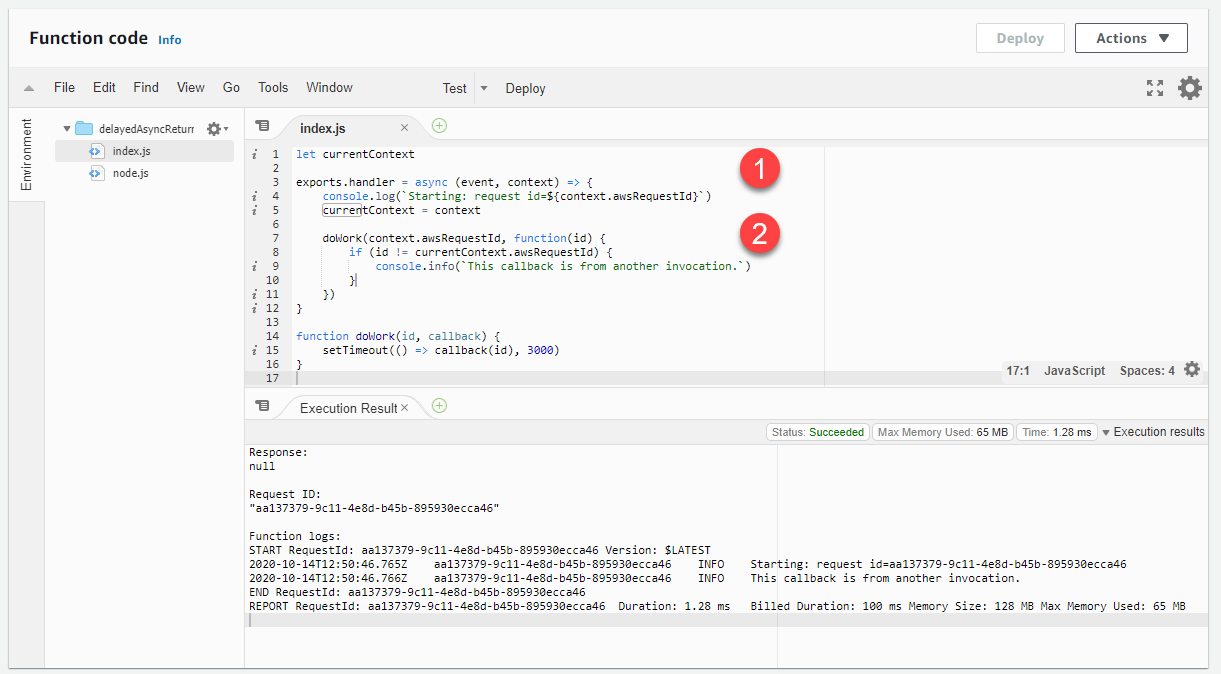
-
Lambda 函数处理程序取用上下文参数,该参数提供对唯一调用请求 ID 的访问权限。
-
将 awsRequestId 传递给 doWork 函数。在回调中,将 ID 与当前调用的 awsRequestId 进行比较。如果这些值不同,则代码可以相应地采取行动。
