本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Lambda 执行环境
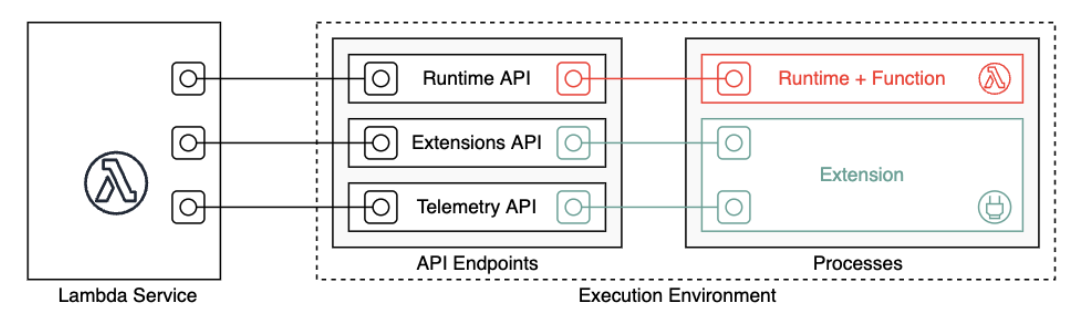
Lambda 在执行环境中调用您的函数,该环境提供一个安全和隔离的运行时环境。执行环境管理运行函数所需的资源。执行环境为函数的运行时以及与函数关联的任何外部扩展提供生命周期支持。
函数的运行时使用运行时 API 与 Lambda 进行通信。扩展使用扩展 API 与 Lambda 进行通信。扩展还可借助遥测 API,从该函数接收日志消息与其他遥测数据。
创建 Lambda 函数时,您需要指定配置信息,例如可用内存量和函数允许的最长执行时间。Lambda 使用此信息设置执行环境。
函数的运行时和每个外部扩展都是在执行环境中运行的进程。权限、资源、凭证和环境变量在函数和扩展之间共享。
Lambda 执行环境生命周期

每个阶段都以 Lambda 发送到运行时和所有注册的扩展的事件开始。运行时和每个扩展通过发送 Next API 请求来指示完成。当运行时和每个扩展完成且没有挂起的事件时,Lambda 会冻结执行环境。
Init 阶段
在 Init 阶段,Lambda 执行三项任务:
-
开启所有扩展 (
Extension init) -
引导运行时 (
Runtime init) -
运行函数的静态代码 (
Function init) -
运行任何
beforeCheckpoint运行时挂钩(仅限 Lambda SnapStart )
当运行时和所有扩展通过发送 Init API 请求表明它们已准备就绪时, Next 阶段结束。Init 阶段限制为 10 秒。如果所有三个任务都未在 10 秒内完成,Lambda 在第一个函数调用时使用配置的函数超时值重试 Init 阶段。
激活 Lambda SnapStart 后,在您发布一个函数版本时会发生 Init 阶段。Lambda 保存初始化的执行环境的内存和磁盘状态的快照,永久保存加密快照并对其进行缓存以实现低延迟访问。如果您具有 beforeCheckpoint 运行时挂钩,则该代码将在 Init 阶段结束时运行。
注意
10 秒的超时不适用于使用预配置并发的函数或。 SnapStart对于预配置的并发和 SnapStart 函数,您的初始化代码最多可以运行 15 分钟。时间限制为 130 秒或配置的函数超时(最大 900 秒),以较高者为准。
使用预置并发时,Lambda 会在您为函数配置 PC 设置时初始化执行环境。Lambda 还确保初始化的执行环境在调用之前始终可用。您会发现函数的调用和初始化阶段之间存在时间差。根据函数的运行时系统和内存配置,在初始化的执行环境中首次调用时可能会发生一些延迟变化。
对于使用按需并发的函数,Lambda 可能会在调用请求之前偶尔初始化执行环境。发生这种情况时,您可能会观察到函数的初始化和调用阶段之间存在时间差。我们建议您不要依赖此行为。
在 Init 阶段失败
如果函数在 Init 阶段崩溃或超时,Lambda 会在日志中发出错误信息。INIT_REPORT
例 — INIT_REPORT 超时日志
INIT_REPORT Init Duration: 1236.04 ms Phase: init Status: timeout
例 — INIT_REPORT 扩展失败日志
INIT_REPORT Init Duration: 1236.04 ms Phase: init Status: error Error Type: Extension.Crash
如果该Init阶段成功,Lambda 不会发出日INIT_REPORT志 SnapStart,除非已激活。 SnapStart 函数总是发出。INIT_REPORT有关更多信息,请参阅监控 Lambda SnapStart。
恢复阶段(仅限 Lambda SnapStart )
当您首次调用函数时,随着SnapStart函数的扩展,Lambda 会从保留的快照恢复新的执行环境,而不是从头开始初始化函数。如果您有 afterRestore() 运行时挂钩,则代码将在 Restore 阶段结束时运行。afterRestore() 运行时挂钩执行期间将产生费用。必须加载运行时(JVM),并且 afterRestore() 运行时挂钩必须在超时限制(10 秒)内完成。否则,你会得到一个 SnapStartTimeoutException。Restore 阶段完成后,Lambda 将调用函数处理程序(调用阶段)。
在 Restore 阶段失败
如果 Restore 阶段失败,Lambda 会在 RESTORE_REPORT 日志中发出错误信息。
例 — RESTORE_REPORT 超时日志
RESTORE_REPORT Restore Duration: 1236.04 ms Status: timeout
例 — RESTORE_REPORT 运行时系统钩子失败日志
RESTORE_REPORT Restore Duration: 1236.04 ms Status: error Error Type: Runtime.ExitError
有关 RESTORE_REPORT 日志的更多信息,请参阅 监控 Lambda SnapStart。
调用阶段
当调用 Lambda 函数以响应 Next API 请求时,Lambda 向运行时和每个扩展发送一个 Invoke 事件。
函数的超时设置限制了整个 Invoke 阶段的持续时间。例如,如果将函数超时设置为 360 秒,则该函数和所有扩展都需要在 360 秒内完成。请注意,没有独立的调用后阶段。持续时间是所有调用时间(运行时 + 扩展)的总和,直到函数和所有扩展完成执行之后才计算。
调用阶段在运行时之后结束,所有扩展都通过发送 Next API 表示它们已完成。
在调用阶段失败
如果 Lambda 函数在 Invoke 阶段崩溃或超时,Lambda 会重置执行环境。下图演示了调用失败时的 Lambda 执行环境行为:

在上图中:
-
第一个阶段是 INIT 阶段,运行没有错误。
-
第二个阶段是 INVOKE 阶段,运行没有错误。
-
假设您的函数在某个时点遇到调用失败的问题(例如函数超时或运行时错误)。标签为 INVOKE WITH ERROR 的第三个阶段演示了这种情况。出现这种情况时,Lambda 服务会执行重置。重置的行为类似于
Shutdown事件。首先,Lambda 会关闭运行时,然后向每个注册的外部扩展发送一个Shutdown事件。该事件包括关闭的原因。如果此环境用于新调用,则 Lambda 会将扩展和运行时与下一次调用一起重新初始化。注意
Lambda 重置未在下一个初始化阶段之前清除
/tmp目录内容。这种行为与常规关闭阶段一致。 -
第四个阶段是调用失败后立即进入的 INVOKE 阶段。在这里,Lambda 通过重新运行 INIT 阶段重新初始化环境。此情况称为隐藏初始化。当出现被抑制的初始化时,Lambda 不会在日志中明确报告额外的初始化阶段。 CloudWatch 相反,您可能会注意到 REPORT 行中的持续时间包括一个额外的 INIT 持续时间 + INVOKE 持续时间。例如,假设您在中看到以下日志 CloudWatch:
2022-12-20T01:00:00.000-08:00 START RequestId: XXX Version: $LATEST 2022-12-20T01:00:02.500-08:00 END RequestId: XXX 2022-12-20T01:00:02.500-08:00 REPORT RequestId: XXX Duration: 3022.91 ms Billed Duration: 3000 ms Memory Size: 512 MB Max Memory Used: 157 MB在此例中,REPORT 和 START 时间戳的间隔为 2.5 秒。这与报告的持续时间(3022.91 毫秒)不一致,因为它没有考虑 Lambda 执行的额外 INIT(隐藏初始化)。在此例中,您可以推断出实际的 INVOKE 阶段用时 2.5 秒。
要更深入地了解这种行为,您可以使用 Lambda 遥测 API。每当在调用阶段之间出现隐藏初始化时,Telemetry API 都会发出
INIT_START、INIT_RUNTIME_DONE、INIT_REPORT事件以及phase=invoke。 -
第五个阶段是 SHUTDOWN 阶段,该阶段运行没有错误。
关闭阶段
若 Lambda 即将关闭运行时,它会向每个已注册的外部扩展发送一个 Shutdown 事件。扩展可以使用此时间执行最终清理任务。Shutdown 事件是对 Next API 请求的响应。
持续时间:整个 Shutdown 阶段的上限为 2 秒。如果运行时或任何扩展没有响应,则 Lambda 会通过一个信号 (SIGKILL) 终止它。
在函数和所有扩展完成后,Lambda 维护执行环境一段时间,以预期另一个函数调用。实际上,Lambda 会冻结执行环境。当再次调用该函数时,Lambda 会解冻环境以便重复使用。重复使用执行环境会产生以下影响:
-
在该函数的处理程序方法的外部声明的对象保持已初始化的状态,再次调用函数时提供额外的优化功能。例如,如果您的 Lambda 函数建立数据库连接,而不是重新建立连接,则在后续调用中使用原始连接。建议您在代码中添加逻辑,以便在创建新连接之前检查是否存在连接。
-
每个执行环境都在
/tmp目录中提供 512MB 到 10240MB 之间的磁盘空间(以 1MB 递增)。冻结执行环境时,目录内容会保留,同时提供可用于多次调用的暂时性缓存。您可以添加额外的代码来检查缓存中是否有您存储的数据。有关部署大小限制的更多信息,请参阅Lambda 配额: -
如果 Lambda 重复使用执行环境,则由 Lambda 函数启动但在函数结束时未完成的后台进程或回调将继续执行。确保代码中的任何后台进程或回调在代码退出前已完成。
在编写函数代码时,不会假定 Lambda 自动为后续函数调用重复使用执行环境。其他因素可能指示需要 Lambda 创建新的执行环境,这可能导致意外结果(例如,数据库连接失败)。
