我们不再更新 Amazon Machine Learning 服务,也不再接受新用户使用该服务。本文档可供现有用户使用,但我们不会再对其进行更新。有关更多信息,请参阅什么是 Amazon Machine Learning。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
拆分数据
ML 模型的基本目标是在用于训练模型的数据实例之外,准确预测未来的数据实例。使用 ML 模型进行决策时,我们需要评估模型的预测性能。要使用 ML 模型未读取的数据评估其预测的质量,可以保留或拆分一部分我们已知答案的数据,用作未来数据,评估 ML 模型预测该数据的正确答案的质量如何。您可以将数据源拆分一部分作为训练数据源,一部分作为评估数据源。
Amazon ML 提供了三个选项用于拆分数据:
-
预拆分数据 - 在将数据上传到 Amazon Simple Storage Service (Amazon S3) 之前,您可以将数据拆分为两个数据输入位置,使用它们创建两个单独的数据源。
-
Amazon ML 顺序拆分 - 您可以让 Amazon ML 在创建训练数据源和评估数据源时按顺序拆分数据。
-
Amazon ML 随机拆分 - 您可以让 Amazon ML 在创建训练数据源和评估数据源时使用做种随机方法拆分数据。
预拆分数据
如果您希望明确控制训练数据源和评估数据源中的数据,请将数据拆分到单独的数据位置,并为输入位置和评估位置创建单独的数据源。
按顺序拆分数据
为训练和评估拆分输入数据的一种简单方法是选择数据中未重叠的子集,同时保留数据记录的顺序。如果您希望针对特定日期或特定时间范围内的数据评估 ML 模型,这种方法非常有用。例如,假设您有过去五个月的客户参与数据,并希望使用此历史数据来预测下个月的客户参与情况。使用时间范围的开头进行训练并使用时间范围的结尾进行评估,相比从整个数据范围中提取记录数据,这种方法可以更准确地估算模型质量。
下图显示了您什么时候应使用顺序拆分策略,什么时候应使用随机策略。
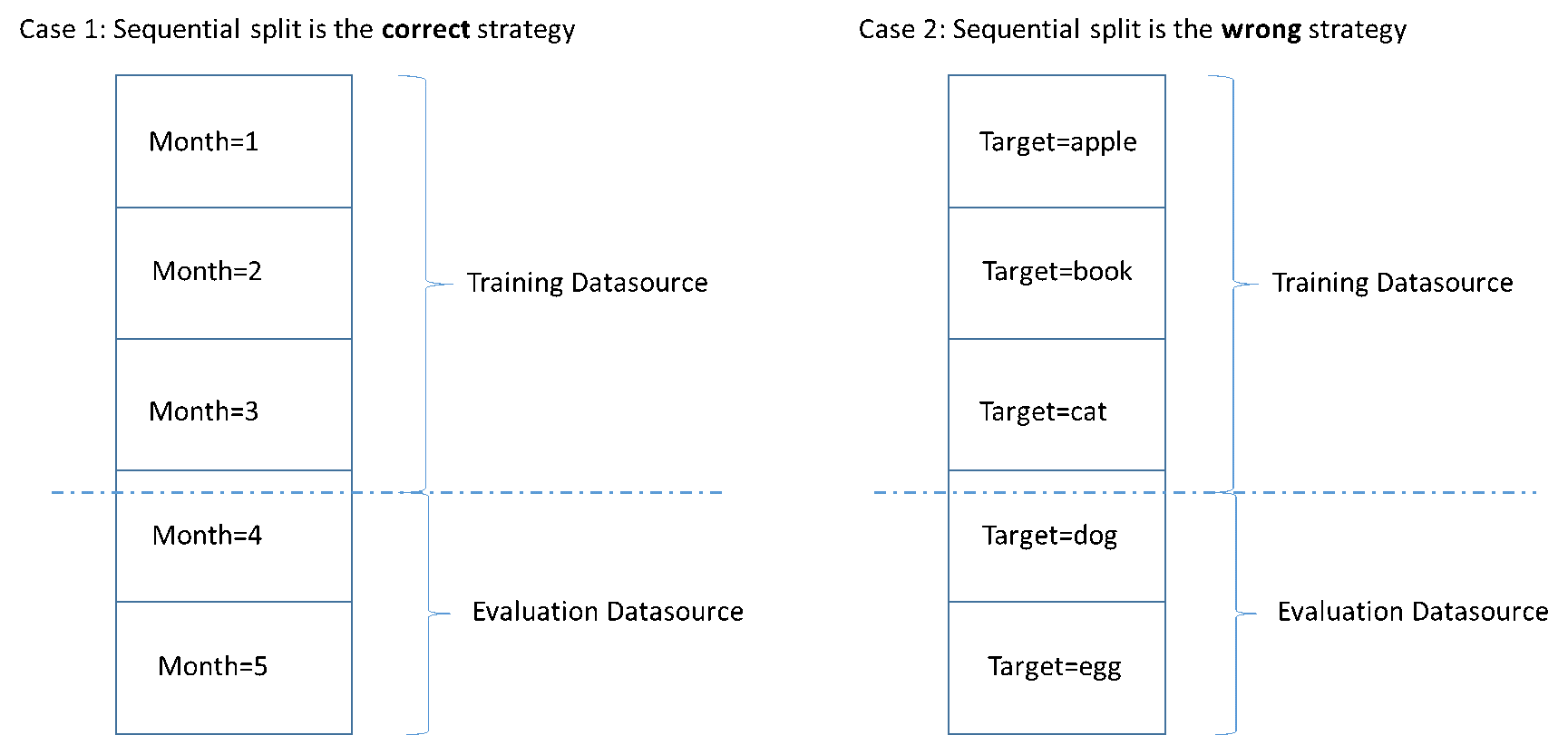
创建数据源时,您可以选择顺序拆分数据源,Amazon ML 使用前 70% 的数据进行训练,使用剩余的 30% 数据进行评估。这是使用 Amazon ML 控制台拆分数据时的默认方法。
随机拆分数据
将输入数据随机拆分为训练数据源和评估数据源,可确保这两种数据源中的数据分布相似。在您不需要保留输入数据的顺序时,选择此选项。
Amazon ML 使用做种的伪随机数字生成方法拆分数据。种子一部分基于输入字符串值,一部分基于数据本身的内容。默认情况下,Amazon ML 控制台使用输入数据的 S3 位置作为字符串。API 用户可以提供自定义字符串。这意味着只要 S3 存储桶和数据不变,Amazon ML 每次都使用相同的方法拆分数据。要更改 Amazon ML 拆分数据的方法,可以使用 CreateDatasourceFromS3、CreateDatasourceFromRedshift 或 CreateDatasourceFromRDS API 并为种子字符串提供值。使用它们 APIs 为训练和评估创建单独的数据源时,必须为两个数据源使用相同的种子字符串值,为一个数据源使用相同的补码标志,以确保训练和评估数据之间没有重叠。
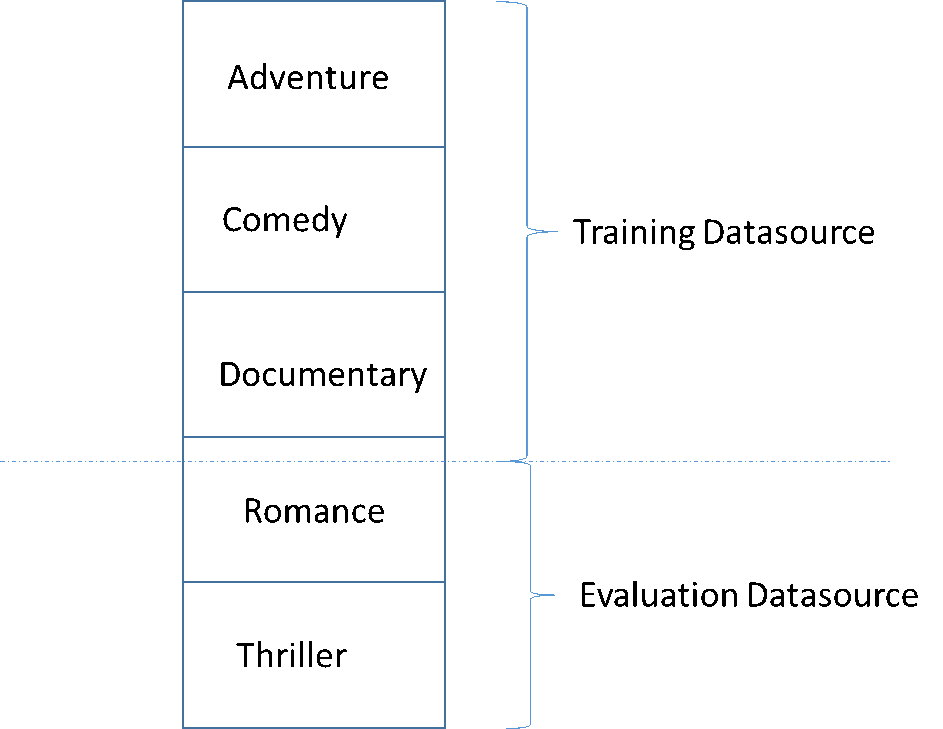
开发高质量 ML 模型中的一个常见陷阱是,评估 ML 模型所用数据与训练所用数据不相似。例如,假设您使用 ML 预测电影的类型,并且您的训练数据包含冒险片、喜剧片和纪录片类型的电影。但是,您的评估数据只包含来自爱情片和惊悚片类型的数据。这种情况下,ML 模型未学习任何关于爱情片和惊悚片类型的信息,评估过程未评估模型的冒险片、喜剧片和纪录片模式学习模式效果如何。因此,类型信息无用,ML 模型的所有类型预测质量受损。模型和评估太过不同(描述性统计信息具有极大的差别)而无用。当输入数据按数据集中的一列排序然后按顺序拆分时,会出现这种情况。
如果您的训练数据源和评估数据源具有不同的数据分布,您可在模型评估中看到评估警报。有关评估警报的更多信息,请参阅评估警报。
如果您已将输入数据随机化(例如使用以下方法:在 Amazon S3 中随机乱序输入数据,或者在创建数据源时使用 Amazon Redshift SQL 查询的 random() 函数或 MySQL SQL 查询的 rand() 函数),则无需在 Amazon ML 中使用随机拆分。在这些情况下,您可以依靠顺序拆分选项,使用类似的分布创建训练数据源和评估数据源。
