本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
向量搜索功能和限制
向量搜索可用性
R6g、R7g 和 T4g 节点类型支持启用了向量搜索的 MemoryDB 配置,并且在所有提供 MemoryDB 的 AWS 区域中可用。
无法修改现有集群来启用搜索。但是,可以根据已禁用搜索的集群的快照来创建已启用搜索的集群。
参数限制
下表列出了各种向量搜索项目的限制:
| 项目 | 最大值 |
|---|---|
| 向量中的维数 | 32768 |
| 可以创建的索引数量 | 10 |
| 索引中的字段数量 | 50 |
| FT.SEARCH 和 FT.AGGREGATE TIMEOUT 子句(毫秒) | 10000 |
| FT.AGGREGATE 命令中的管道阶段数量 | 32 |
| FT.AGGREGATE LOAD 子句中的字段数量 | 1024 |
| FT.AGGREGATE GROUPBY 子句中的字段数量 | 16 |
| FT.AGGREGATE SORTBY 子句中的字段数量 | 16 |
| FT.AGGREGATE PARAM 子句中的参数数量 | 32 |
| HNSW M 参数 | 512 |
| HNSW EF_CONSTRUCTION 参数 | 4096 |
| HNSW EF_RUNTIME 参数 | 4096 |
扩展限制
MemoryDB 的向量搜索目前仅限于单个分片,不支持水平扩展。向量搜索支持垂直扩展和副本扩展。
操作限制
索引持久性和回填
向量搜索特征保留索引定义和索引内容。这意味着,在任何会导致节点启动或重新启动的操作请求或事件中,将从最新快照中恢复索引定义和内容,并从日志中重放任何待定事务。无需用户执行任何操作即可启动此操作。数据恢复后,重建过程将作为回填操作执行。这在功能上等同于系统自动为每个定义的索引执行 FT.CREATE 命令。请注意,数据恢复后,很可能在索引回填完成之前,节点便可用于应用程序操作,这意味着应用程序将再次看到回填,例如,使用回填索引的搜索命令可能会遭到拒绝。有关回填的更多信息,请参阅向量搜索概述。
索引回填的完成在主索引和副本之间不同步。应用程序可能会意外看到这种不同步的情况,因此建议应用程序在启动搜索操作之前,先在主副本和所有副本上验证回填完成情况。
快照导入/导出和实时迁移
搜索索引存在于 RDB 文件中,这会限制数据兼容传输。只有另一个启用了 MemoryDB 向量的集群才能理解由 MemoryDB 向量搜索功能定义的向量索引格式。此外,预览集群中的 RDB 文件可以由 GA 版本的 MemoryDB 集群导入,它将在加载 RDB 文件时重建索引内容。
但是,不包含索引的 RDB 文件不受这种限制。因此,只要在导出前删除索引,就可以将预览群集中的数据导出到非预览群集。
内存消耗
内存消耗基于向量数、维度数、M 值和非向量数据量,例如与向量关联的元数据或实例中存储的其他数据。
所需的总存储空间是实际向量数据所需空间和向量索引所需空间的组合。计算向量数据所需空间时,需要测量在 HASH 或 JSON 数据结构中存储向量所需的实际容量,以及为实现优化内存分配而需向最近的内存块增加的额外开销。每个向量索引都使用对存储在这些数据结构中的向量数据的引用,并使用有效的内存优化来删除索引中向量数据的任何重复副本。
向量的数量取决于您将数据表示为向量的方式。例如,您可以选择将单个文档表示成几个块,其中每个块表示一个向量。或者,您可以选择将整个文档表示为单个向量。
向量的维数取决于您选择的嵌入模型。例如,如果您选择使用 AWS Titan
M 参数表示在索引构造期间为每个新元素创建的双向链接数。MemoryDB 将此值默认为 16;但您可以重写此设置。较高的 M 参数更适合高维度和/或高查全率要求,而低 M 参数更适合低维度和/或低查全率要求。M 值会随着索引变大而增加内存消耗,从而使得总体内存消耗变得更高。
在控制台体验中,MemoryDB 提供了一种在集群设置下选中“启用向量搜索”后,根据向量工作负载的特性选择正确实例类型的简便方法。
示例工作负载
客户希望以其内部财务文件为基础构建一个语义搜索引擎。他们目前持有 100 万份财务文档,使用具有 1536 个维度的 Titan 嵌入模型将每个文档分成 10 个向量,并且没有非向量数据。客户决定使用默认值 16 作为 M 参数。
向量:100 万 * 10 个块 = 1000 万个向量
维度:1536
非向量数据(GB):0 GB
M 参数:16
有了这些数据,客户可以在控制台中单击使用向量计算器按钮,根据其参数获取推荐的实例类型:
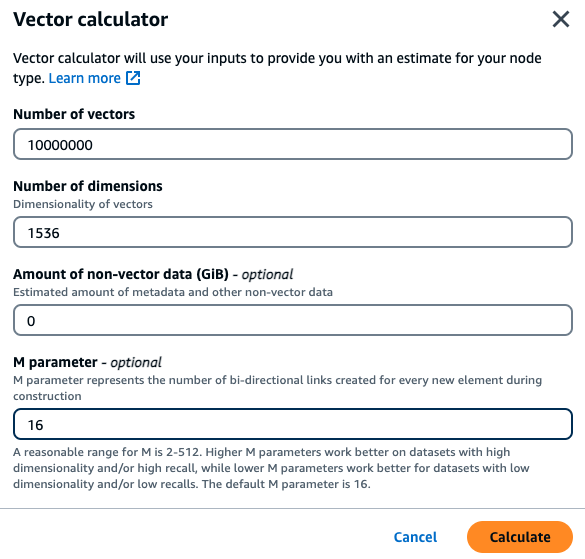

在此示例中,向量计算器将根据提供的参数寻找最小的 MemoryDB r7g 节点类型
根据上述计算方法和示例工作负载中的参数,此向量数据将需要 104.9 GB 来存储数据和单个索引。在这种情况下,因为 db.r7g.4xlarge 实例类型有 105.81 GB 的可用存储空间,所以建议使用这种实例类型。下一个更小的节点类型太小,无法承载向量工作负载。
由于每个向量索引都使用对所存储向量数据的引用,并且不会在向量索引中创建向量数据的额外副本,因此索引消耗的空间也相对较少。这在创建多个索引时以及部分向量数据已删除的情况下很有用,并且重建 HNSW 图将有助于建立适宜的节点连接,从而实现高质量的向量搜索结果。
在回填期间内存不足
与 Valkey 和 Redis OSS 写入操作类似,索引回填也受内存不足限制。如果引擎内存在回填过程中已满,则所有回填都将暂停。有可用内存后,回填过程会恢复。当由于内存不足导致回填暂停时,也可以删除内容和编制索引。
事务
命令 FT.CREATE、FT.DROPINDEX、FT.ALIASADD、FT.ALIASDEL和 FT.ALIASUPDATE 不能在事务上下文中执行,也就是说,不能在 MULTI/EXEC 块或 LUA 或 FUNCTION 脚本中执行。
