本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用压缩来维护表格
Iceberg 包含的功能使您能够在向表写入数据后执行表维护操作
冰山压实
在 Iceberg 中,您可以使用压实来执行四项任务:
-
将小文件合并成通常超过 100 MB 的大文件。这种技术被称为垃圾箱包装。
-
将删除文件与数据文件合并。删除文件是由使用该 merge-on-read方法的更新或删除生成的。
-
(重新)根据查询模式对数据进行排序。可以在没有任何排序顺序的情况下写入数据,也可以使用适合写入和更新的排序顺序写入数据。
-
使用空间填充曲线对数据进行聚类,以优化不同的查询模式,尤其是 z 顺序排序。
开启后 AWS,你可以通过 Amazon Athena 或者在亚马逊 EMR 中使用 Spark 或。 AWS Glue
使用 rewrite_data_files
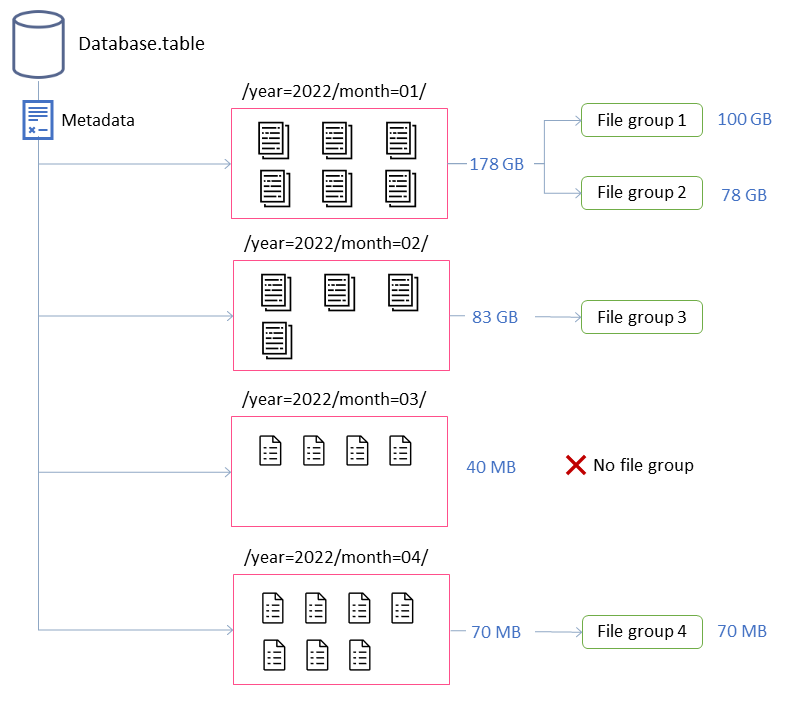
在此示例中,Iceberg 表由四个分区组成。每个分区的大小不同,文件数量也不同。如果您启动 Spark 应用程序来运行压缩,则该应用程序总共会创建四个要处理的文件组。文件组是 Iceberg 抽象,它表示将由单个 Spark 作业处理的一组文件。也就是说,运行压缩的 Spark 应用程序将创建四个 Spark 作业来处理数据。
调整压实行为
以下关键属性控制如何选择数据文件进行压缩:
-
默认情况下,MAX_FILE_GROUP_SIZE_BYTES 将单个文件组(Spark 作业)的数据限制设置为 100 GB
。对于没有分区的表或分区跨越数百 GB 的表,此属性尤其重要。通过设置此限制,您可以分解操作以计划工作并取得进展,同时防止群集上的资源耗尽。 注意:每个文件组都是单独排序的。因此,如果要执行分区级排序,则必须调整此限制以匹配分区大小。
-
MIN_FILE_SIZE_BYTES 或 MIN_
FILE_SIZE_DEFAULT_RATIO 默认为在表级别设置的目标文件大小的 7 5%。例如,如果表的目标大小为 512 MB,则任何小于 384 MB 的文件都将包含在要压缩的文件集中。 -
MAX_FILE_SIZE_BYTES 或 MAX_FILE_
SIZE_DEFAULT_RATIO 默认为目标文件大小的180% 。与设置最小文件大小的两个属性一样,这些属性用于识别压缩作业的候选文件。 -
MIN_INP
UT_FILES 指定表分区大小小于目标文件大小时要压缩的最小文件数。此属性的值用于确定是否值得根据文件数(默认为 5)压缩文件。 -
D@@ ELETE_FILE_TH
RESHOLD 指定文件在压缩中包含之前对其执行的最小删除操作次数。除非您另行指定,否则压缩不会将删除文件与数据文件合并。要启用此功能,必须使用此属性设置阈值。此阈值特定于单个数据文件,因此,如果将其设置为 3,则仅当有三个或更多引用数据文件的删除文件时,才会重写该数据文件。
这些属性可以深入了解上图中文件组的形成情况。
例如,标记为的分区month=01包括两个文件组,因为它超过了 100 GB 的最大大小限制。相比之下,该month=02分区包含单个文件组,因为它小于 100 GB。该month=03分区不满足默认的最低输入文件要求,即五个文件。因此,它不会被压实。最后,尽管该month=04分区包含的数据不足以形成所需大小的单个文件,但由于该分区包含五个以上的小文件,因此文件将被压缩。
您可以为在亚马逊 EMR 上运行的 Spark 设置这些参数,或者。 AWS Glue对于 Amazon Athena,您可以使用以前缀开头的表属性来管理类似的属性)。optimize_
在亚马逊 EMR 上使用 Spark 运行压缩或 AWS Glue
本节介绍如何正确调整 Spark 集群的大小以运行 Iceberg 的压缩实用程序。以下示例使用 Amazon EMR Serverless,但你可以在亚马逊 EMR、亚马逊 EKS 上使用相同的方法,也可以 EC2 在 Amazon EKS 上使用相同的方法。 AWS Glue
您可以利用文件组和 Spark 作业之间的关联来规划群集资源。要按顺序处理文件组,考虑到每个文件组的最大大小为 100 GB,可以设置以下 Spark 属性:
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
如果要加快压缩速度,则可以通过增加并行压缩的文件组的数量来横向扩展。您还可以使用手动或动态扩展来扩展 Amazon EMR。
-
手动缩放(例如,按系数 4)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(我们的因素) -
spark.executor.instances=5(示例中使用的值)x4(我们的因子)=20 -
spark.dynamicAllocation.enabled=FALSE
-
-
动态缩放
-
spark.dynamicAllocation.enabled=TRUE(默认,无需执行任何操作) -
MAX_CONCURRENT_FILE_GROUP_RE
WRITES = N(将此值与spark.dynamicAllocation.maxExecutors,默认值为 100;根据示例中的执行器配置,您可以将其设置为 20)N
这些是帮助调整集群规模的指导方针。但是,您还应该监控 Spark 作业的性能,以找到最适合您的工作负载的设置。
-
使用亚马逊 Athena 进行压缩
Athena 通过 OPTIMIZE 语句提供了 Iceberg 压缩实用程序作为托管功能的实现。您可以使用此语句来运行压缩,而不必评估基础架构。
此语句使用垃圾箱打包算法将小文件分组为较大的文件,并将删除文件与现有数据文件合并。要使用分层排序或 z 顺序排序对数据进行聚类,请在 Amazon EM AWS Glue R 上使用 Spark 或。
可以在创建表时通过在OPTIMIZE语句中传递表属性来更改该语句的默认行为,也可以在创建表之后使用该CREATE TABLE语句来更改该ALTER TABLE语句的默认行为。有关默认值,请参阅 Athena 文档。
跑步压实的建议
使用案例 |
建议 |
|---|---|
按计划运行垃圾箱压实 |
|
根据事件对垃圾箱进行装箱压实 |
|
运行压缩来对数据进行排序 |
|
运行压缩以使用 z 顺序排序对数据进行聚类 |
|
在由于数据迟到而可能被其他应用程序更新的分区上运行压缩 |
|
在冷分区(不再接收活动写入的数据分区)上运行压缩 |
|
