本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Aurora 状态机和 Step Functions 状态机
本节介绍特定于故障转移和故障恢复 Amazon Aurora 集群的过程和状态机。集群被配置为全局数据库。
注意
出于演示目的,此示例使用与 Aurora MySQL 兼容的版本。你可以对兼容 Aurora PostgreSQL 的版本使用类似的步骤。
稳定状态
在稳定状态下,已创建了一个兼容 Amazon Aurora MySQL 的全球数据库 (dr-globaldb-cluster-mysql),其中包含两个数据库集群。第一个数据库集群 (db-cluster-01) 已在主集群 AWS 区域
(us-east-1) 中创建,用于处理读/写工作负载。第二个数据库集群 (db-cluster-02) 已在辅助区域 (us-west-2) 中创建,用于处理只读工作负载。
除了提供灾难恢复解决方案外,您还可以通过将应用程序中的读取查询路由到辅助数据库集群来减轻主数据库集群的负载。每个集群都分别包含一个名为dbcluster-01-use1-instance-1和dbcluster-02-usw2-instance-2的数据库实例。
事件状态
通过使用 Amazon Aurora 全球数据库,您可以相当快地规划灾难并从灾难中恢复。灾难恢复通常使用恢复时间目标 (RTO) 和恢复点目标 (RPO) 的值来衡量。有关更多信息,请参阅在 Amazon Aurora 全球数据库中使用切换或故障转移。
使用 Aurora 全局数据库,有两种不同的故障转移方法:
-
切换(托管计划内故障转移)
-
故障转移(手动计划外故障切换,或分离并升级)
切换
切换适用于受控环境,例如操作维护和其他计划中的操作程序。通过使用托管计划内故障转移,您可以将 Aurora 全球数据库的主数据库集群重新定位到一个辅助区域。由于切换会等到辅助数据库集群与主数据库同步,因此 RPO 为 0(无数据丢失)。要了解更多信息,请参阅对 Amazon Aurora 全球数据库执行切换。
dr-orchestrator-stepfunction-FAILOVER状态机在事件状态期间被调用,以将您的主集群切换到您选择的辅助区域(us-west-2)。
要执行切换,请执行以下操作:
-
登录到 AWS Management Console。
-
将区域更改为 DR 区域 (
us-west-2)。 -
导航到服务,然后选择 Step Functions。
-
导航到
dr-orchestrator-stepfunction-FAILOVER状态机。 -
选择 “开始执行”,然后在该
Input - optional部分中输入以下 JSON 代码:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
dr-orchestrator-stepfunction-FAILOVER状态机以PlannedFailoverAuroraMySQL 的形式读取资源类型,然后调用dr-orchestrator-stepfunction-planned-Aurora-failover状态机对 Aurora 全局数据库进行故障转移。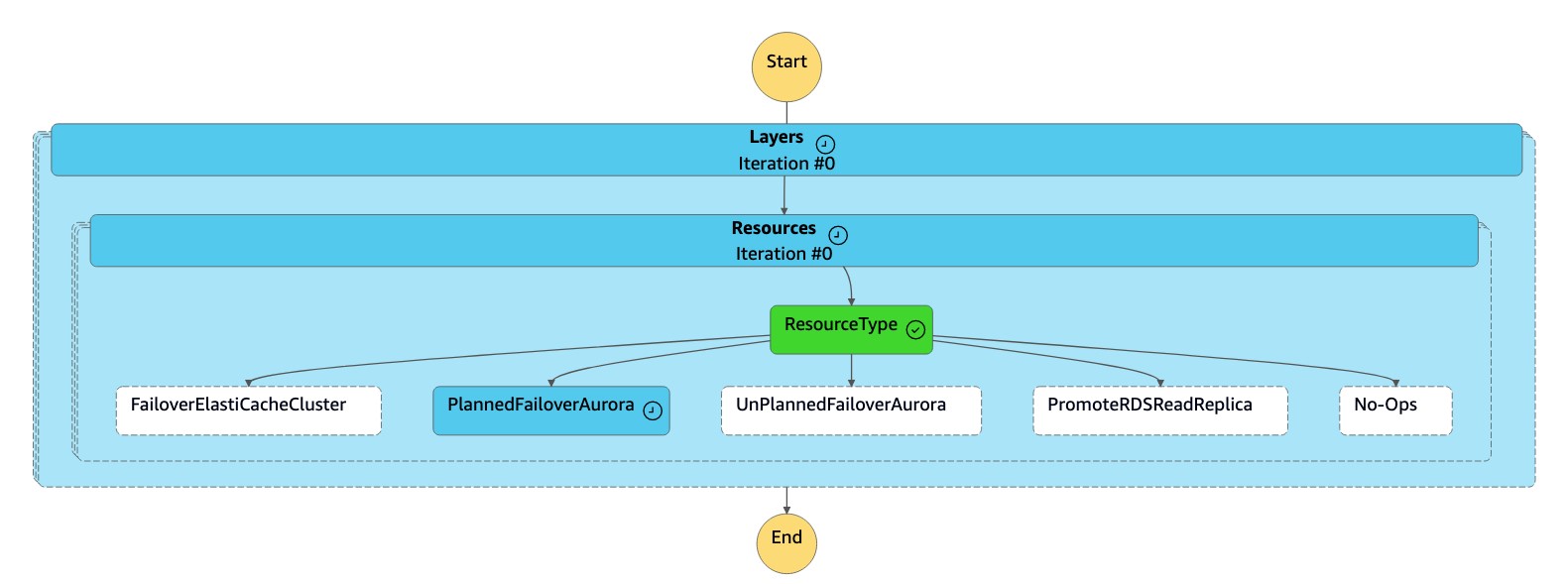
-
dr-orchestrator-stepfunction-planned-Aurora-failover状态机执行以下步骤来切换与 Aurora MySQL 兼容的全局数据库角色。
步骤 描述 期望值 解决导入问题 Lambda 函数用实际 !Import <variable name>名称替换值。"!Import dr-globaldb-cluster-mysql-global-identifier"被替换为"dr-globaldb-cluster-mysql"。故障转移 Aurora 全球集群 Lambda 函数调用 failo ver_global_cluster Boto3 API 来对 Aurora 全局数据库进行故障 转移。 { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }检查故障转移状态 Lambda 函数调用 d escribe_db_clusters Boto3 API 来检查故障转移的状态。 正在修改,可用 发送成功代币 Lambda 函数调用 send_task_success Boto3 API 并将成功 令牌发送回状态机。 DR Orchestrator Failoverh7x /83p1e0 k9mbvkzsp7d9yrt1W RiCdLtd dMccoxlzFhglsdkzp -
导航至 Amazon RDS 控制台。在 “状态” 下,Aurora 全局数据库的值将从 “可用” 更改为 “切换” 或 “正在修改”。
-
dr-orchestrator-stepfunction-planned-Aurora-failover状态机完成后,它会将成功令牌发送回dr-orchestrator-stepfunction-FAILOVER状态机。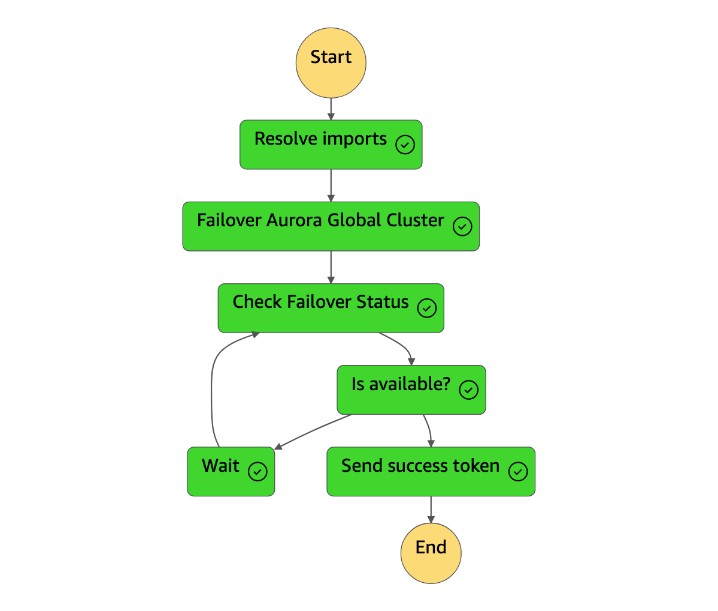
-
dr-orchestrator-stepfunction-FAILOVER状态机已完成。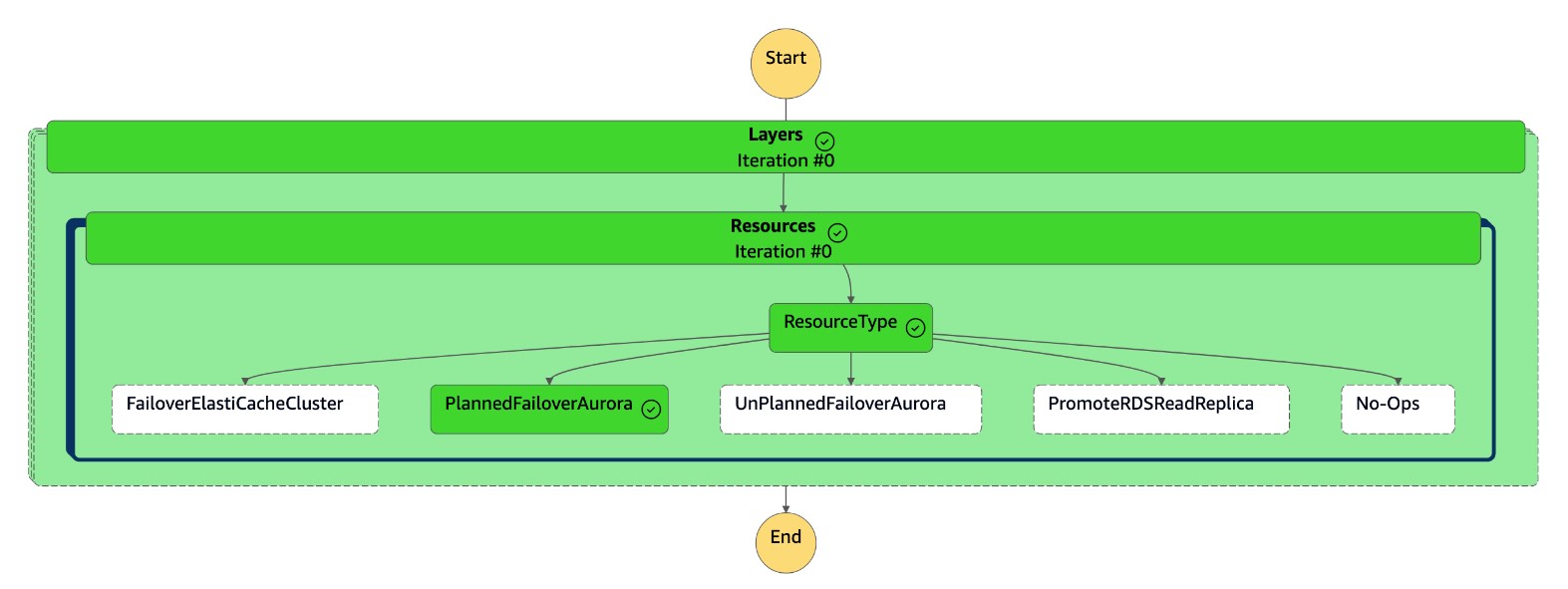
在控制台上,辅助群集 (dbcluster-02) 的角色现在是主群集,并且该群集已准备好为读/写工作负载提供服务。原始主群集 (dbcluster-01) 的角色现在列为辅助群集。
手动计划外故障转移
在极少数情况下,Aurora 全球数据库的主数据库可能会出现意外中断 AWS 区域。如果发生这种情况,主 Aurora 数据库集群及其写入器节点将不可用,主集群和辅助集群之间的复制过程将停止。为了最大限度地减少停机时间 (RTO) 和数据丢失 (RPO),请快速执行跨区域故障转移并重建 Aurora 全球数据库。有关更多信息,请参阅从计划外中断中恢复 Amazon Aurora 全球数据库。
执行计划外故障转移需要将辅助集群与 Aurora 全局数据库分离。在执行计划外故障转移之前,请停止在主 Aurora 数据库集群上写入应用程序。成功完成故障转移后,重新配置应用程序以写入新的主数据库群集。这种方法有助于防止数据丢失。如果主写入节点在故障转移过程中恢复联机,它还有助于避免数据不一致。
要执行计划外故障转移,请调用dr-orchestrator-stepfunction-FAILOVER状态机。在本示例中,辅助群集 (db-cluster-02) 在灾难恢复区域 (us-west-2) 中处于稳定状态。
要执行故障转移,请执行以下操作:
-
登录 控制台。
-
将区域更改为 DR 区域 (
us-west-2)。 -
导航到服务,然后选择 Step Functions。
-
导航到
dr-orchestrator-stepfunction-FAILOVER状态机。 -
选择 “开始执行”,然后在该
Input - optional部分中输入以下 JSON 代码,使用UnPlannedFailoverAurora作为resourceType:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
dr-orchestrator-stepfunction-FAILOVER状态机将资源类型读取为UnPlannedFailoverAuroraMySQL并Detach Cluster from Global Database从dr-orchestrator-stepfunction-unplanned-Aurora-failover状态机调用任务。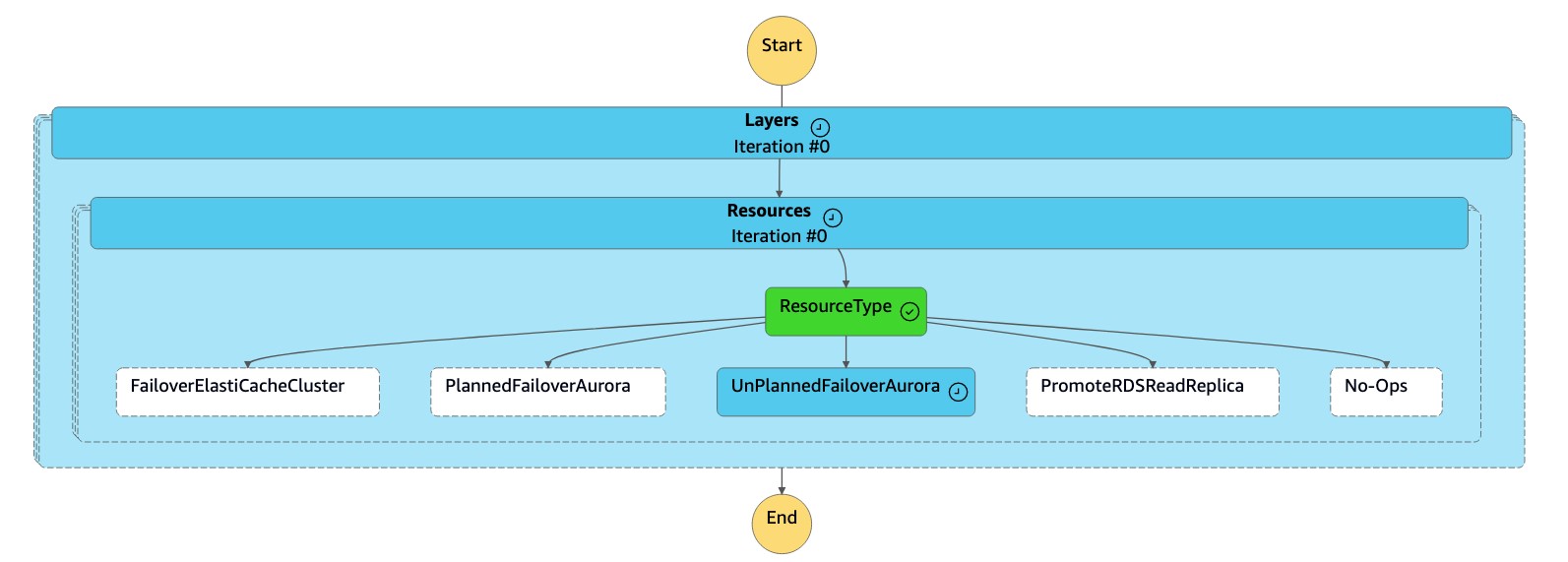
-
该
Detach Cluster from Global Database任务将辅助群集与全局数据库分离(删除)。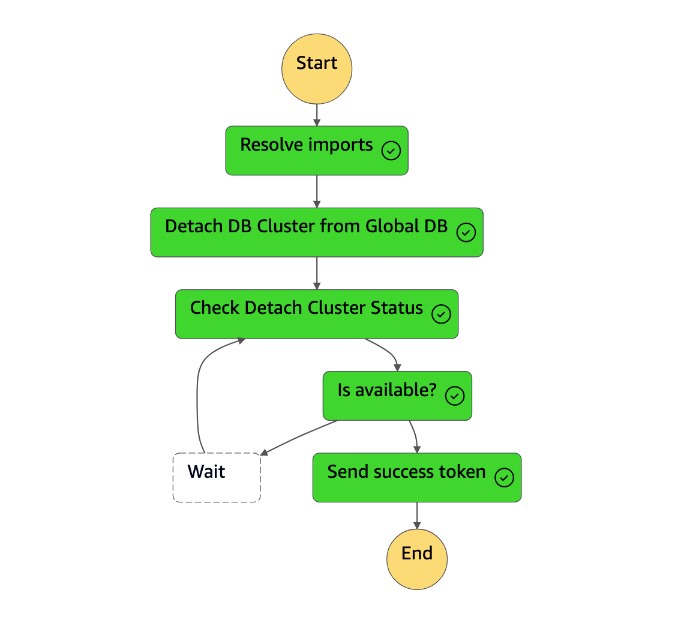
-
辅助群集 (
dbcluster-02) 升级为独立群集,它可以为读/写工作负载提供服务。 -
dr-orchestrator-stepfunction-FAILOVER状态机已完成。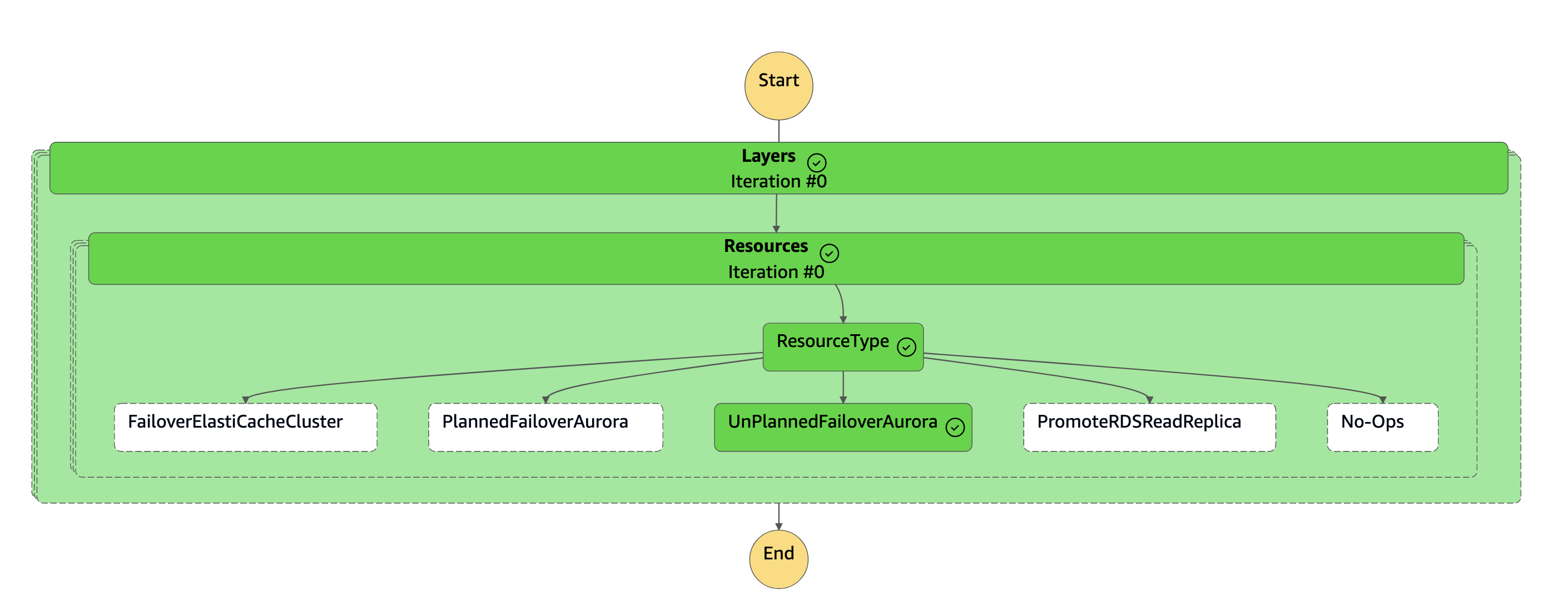
-
辅助集群 (
dbcluster-02) 已与 Aurora 全局数据库分离,它将成为一个独立集群来处理读/写工作负载。 -
重新配置应用程序,使用新的集群终端节点将所有写入操作发送到这个新的独立 Aurora 数据库集群。
故障恢复
灾难(或计划事件)解决后,故障恢复会将您的数据库返回到原始(或新的)主位置。计划外中断得到解决后,您可能需要将以前的主要区域添加回 Aurora 全球数据库。您必须先从以前的主区域中删除现有数据库集群,从新的主区域创建新的数据库集群,然后使用托管计划内故障转移流程切换新集群的角色。
这可以被视为一项有计划的活动,你可以在非高峰时段或周末进行。
您必须手动修改 Amazon Aurora 数据库集群并禁用,然后才能从DeletionProtection以前的主区域 (us-east-1) 运行DR Orchestrator FAILBACK状态机,因为它是用创建的DeletionProtection。
DR Orchestrator Framework 使用dr-orchestrator-stepfunction-FAILBACK状态机自动执行删除现有集群并在以前的主区域中创建新集群的步骤。
要禁用DeletionProtection,请执行以下操作:
-
登录 控制台。
-
将区域更改为以前的主区域 (
us-east-1)。 -
导航到 Amazon RDS 控制台,选择集群名称 (
dbcluster-01),然后选择修改。 -
在 “删除保护” 下,清除 “启用删除保护” 复选框,然后选择 “继续”。
-
选择 “立即应用”,然后选择 “修改集群”。
DR Orchestrator FAILBACK状态机是在故障恢复过程中从以前的主区域 (us-east-1) 调用的。
要执行故障恢复,请执行以下操作:
-
登录 控制台。
-
将区域更改为以前的主区域 (
us-east-1)。 -
导航到 “服务”,然后选择 “Ste p Function s”。
-
导航到
DR Orchestrator FAILBACK状态机。 -
选择 “开始执行”,然后在该
Input - optional部分中输入以下 JSON 代码:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
DR Orchestrator FAILBACK状态机将资源类型读为CreateAuroraSecondaryDBCluster,然后调用dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster状态机。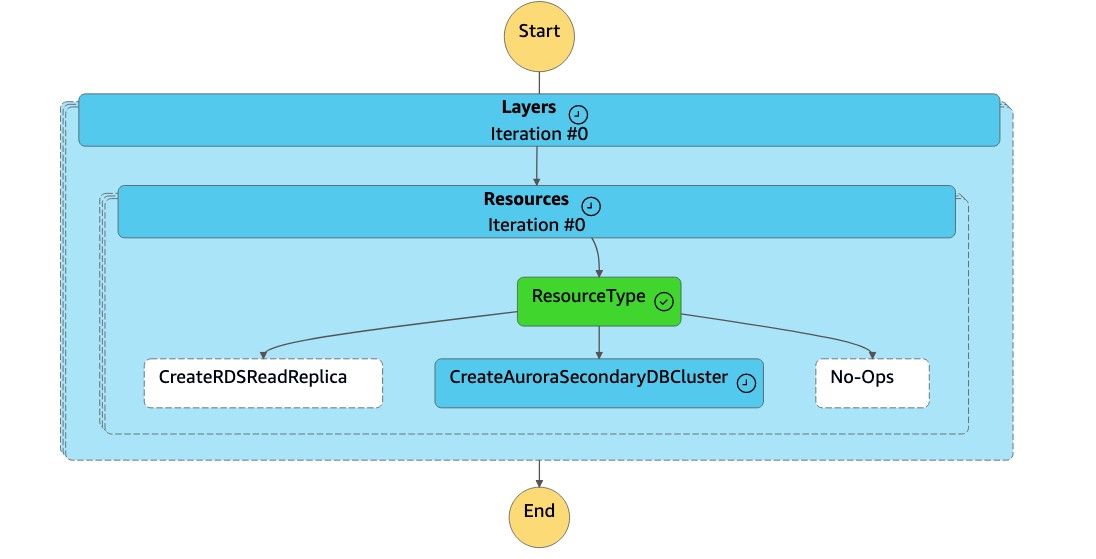
-
dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster状态机将现有集群 (dbcluster-01) 从以前的主区域 (us-east-1) 中删除。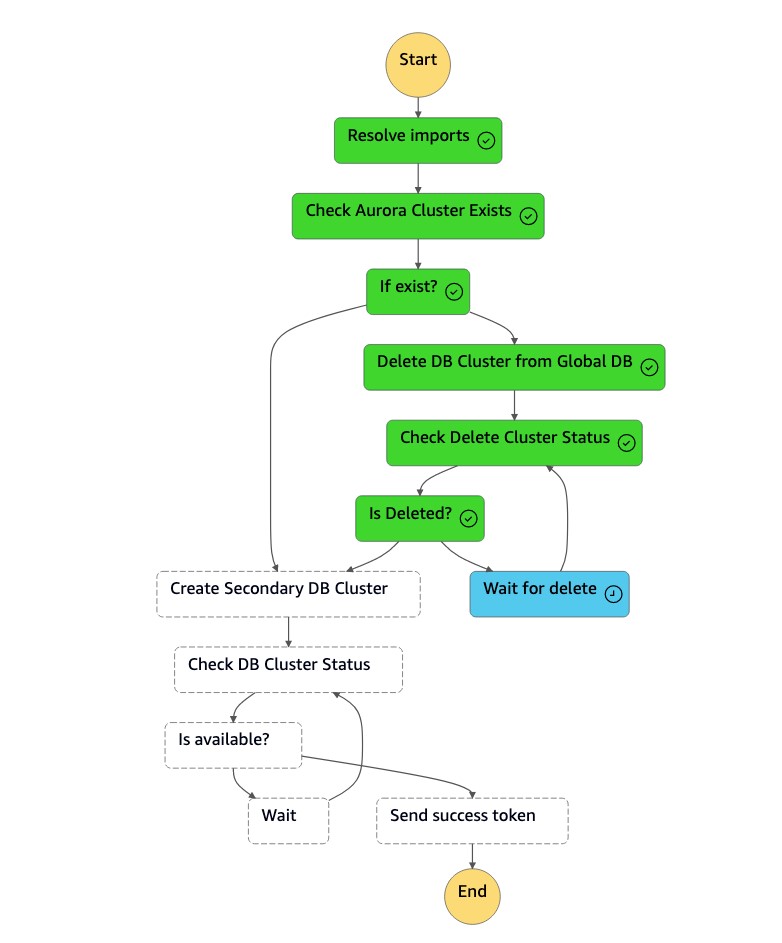
-
删除集群 (
dbcluster-01) 后,状态机将创建新的集群 (dbcluster-01) 和数据库实例,并作为辅助集群加入 Aurora 全局数据库,为只读工作负载提供服务。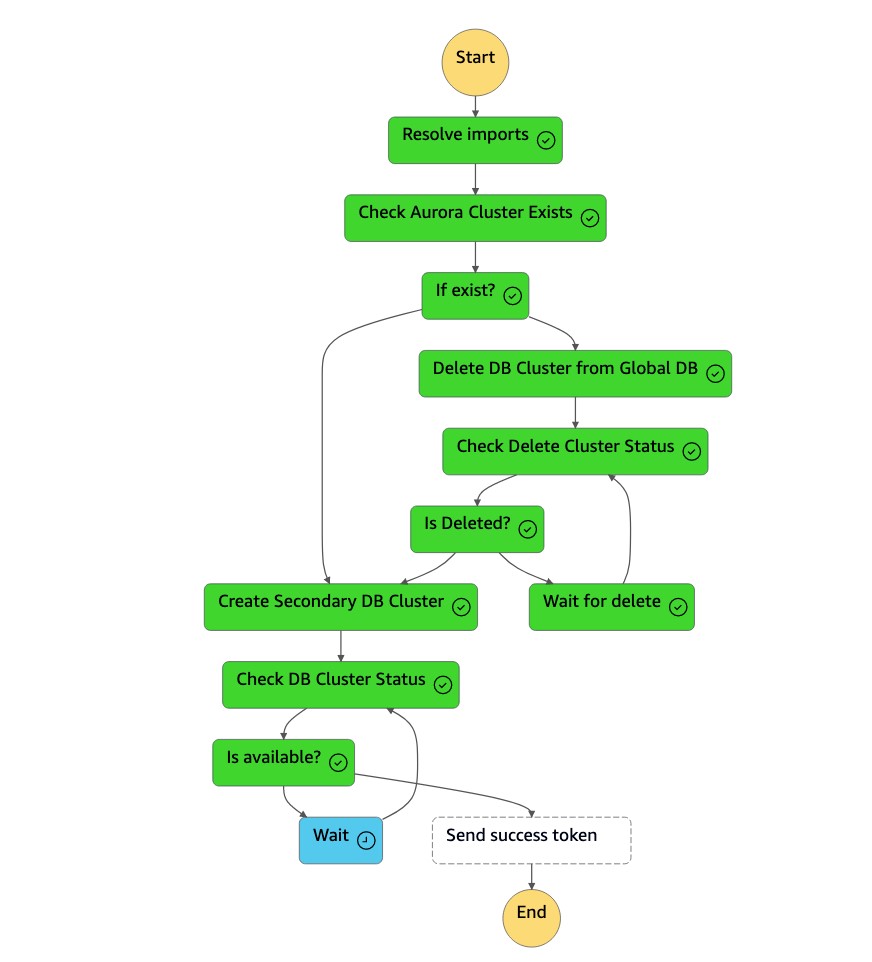
-
辅助群集可用后,
dr-orchestrator-stepfunction-create-Aurora-Secondary-cluster状态机就完成了,它会将成功令牌发送回DR Orchestrator Failback状态机。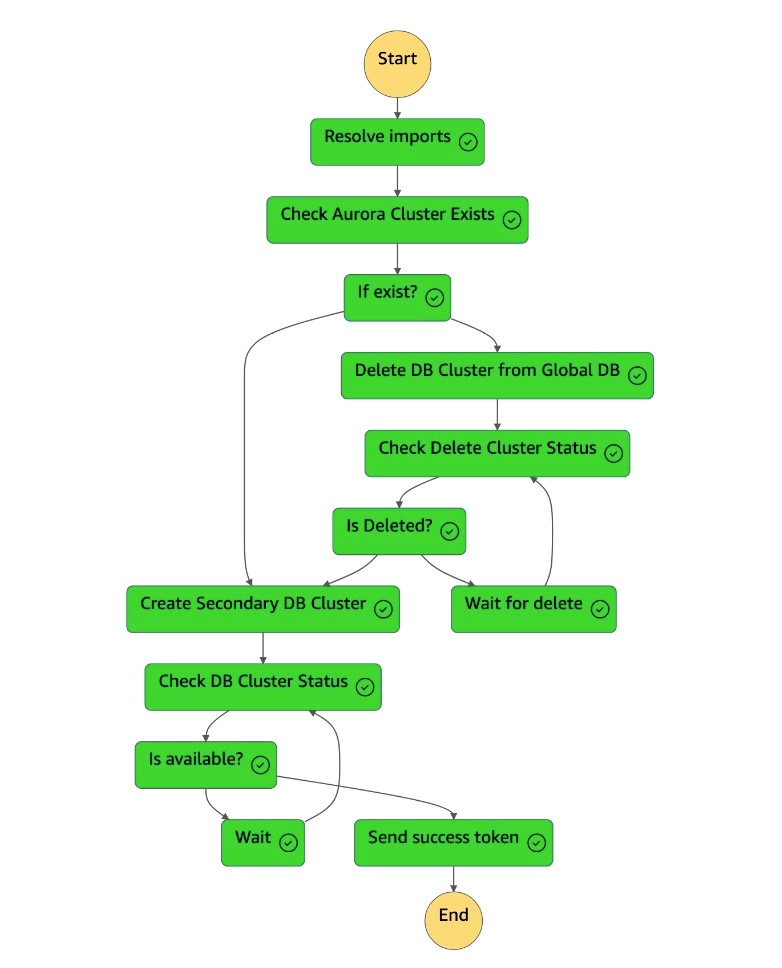
-
dr-orchestrator-stepfunction-FAILBACK状态机已完成。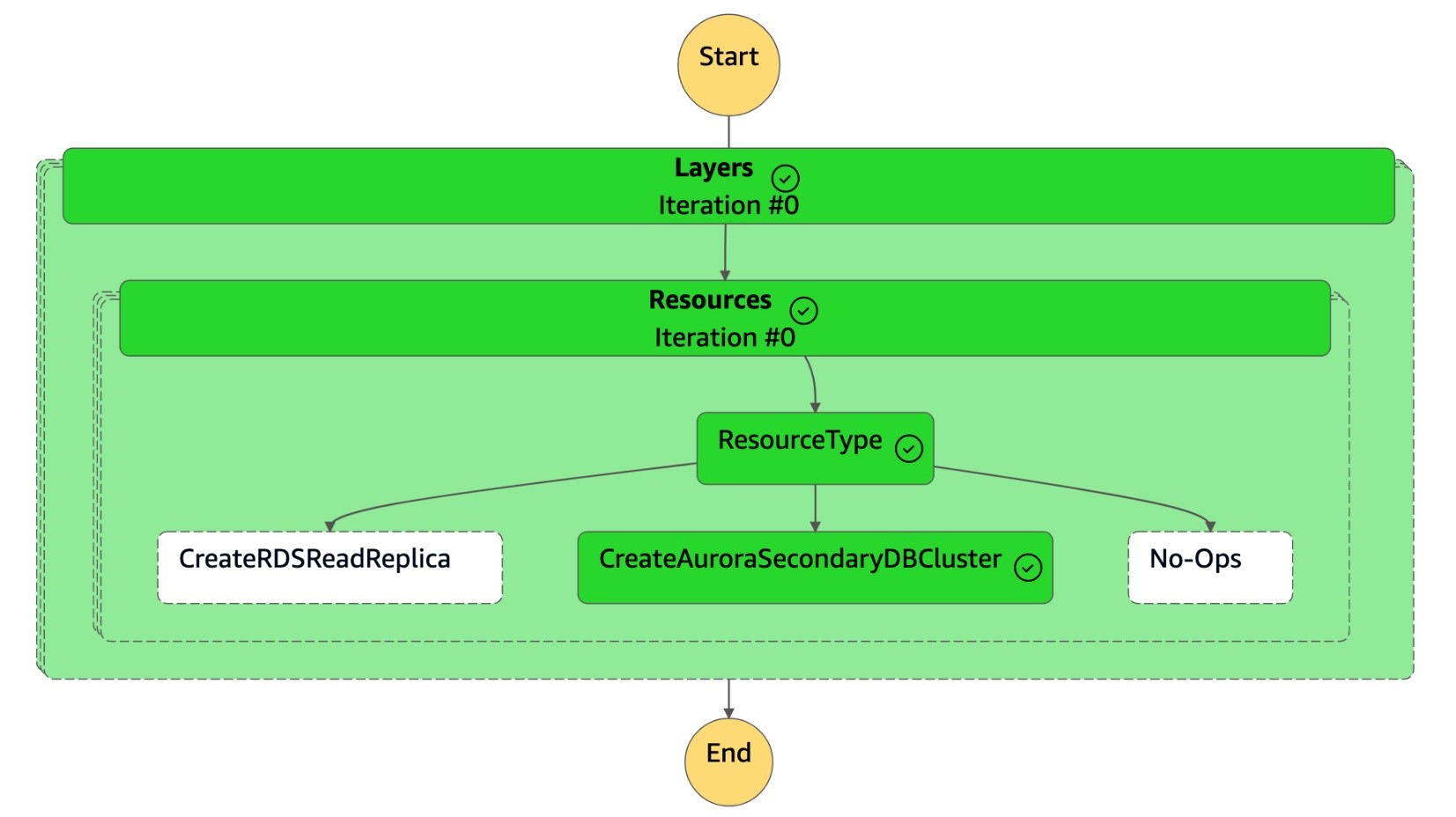
-
您可以在 Amazon RDS 控制台上验证 Aurora 全球数据库。
如果要将主数据库集群重新定位到 us-east-1,则可以按照切换部分中提到的步骤进行操作。
