本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
参考架构
下图显示了将本指南的自动解决方案应用于每日运营报告后的工作流程。将新文件导入亚马逊简单存储服务 (Amazon S3) Simple S3 时,处理完毕后,可以在控制面板中 QuickSight 立即对其进行可视化。
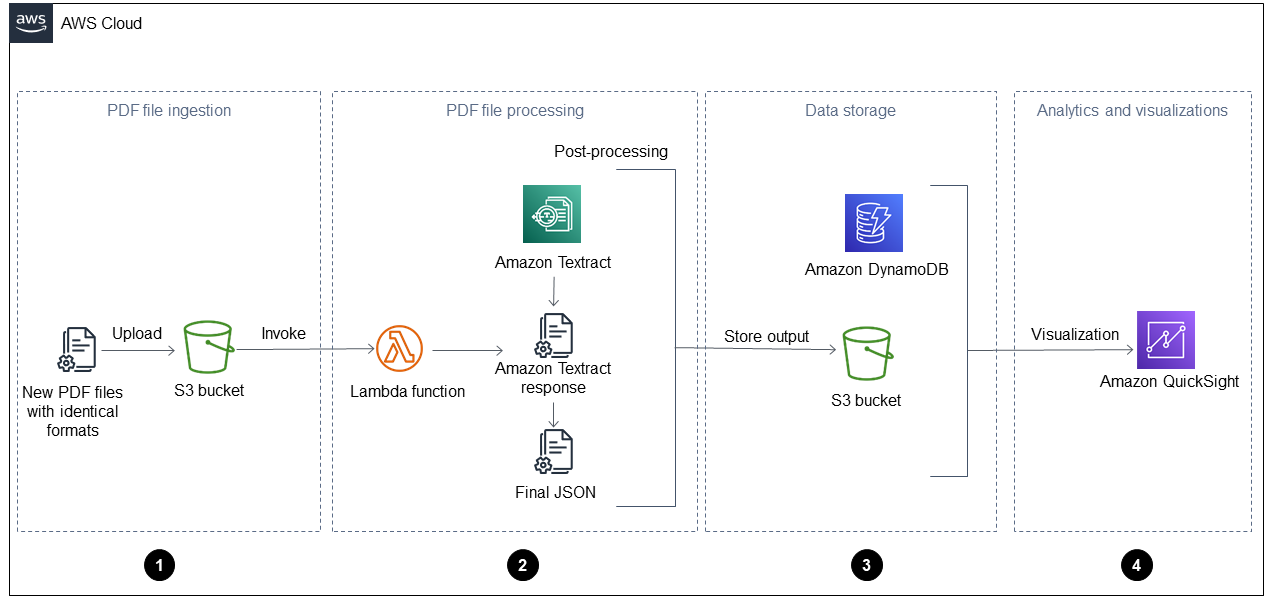
该图显示了以下四个阶段:
-
PDF 文件提取 — 您的应用程序会自动将格式相同的新 PDF 文件(例如每日操作报告)提取到亚马逊简单存储服务 (Amazon S3) Simple S3 Service 存储桶中。当向存储桶添加新的 PDF 文件时,Amazon S3 会启动一个
ObjectCreated事件,这会调用一个函数。 AWS Lambda 有关这方面的更多信息,请参阅 Amazon S3 文档中的使用 Amazon S3 触发器调用 Lambda 函数。 -
PDF 文件处理 — Lambda 函数将一个 PDF 文件发送到亚马逊 Textract,由后者提取内容。后处理脚本运行并解析 Amazon Textract 的响应,并使用预定义的模板处理此类 PDF 文件。此模板包含正确的属性,有助于正确提取所有键值对、表格和其他原始文本。有关这方面的更多信息,请参阅 “ AWS 规范性指南” 网站上的 “使用 Amazon Textract 自动从 PDF 文件中提取内容” 模式。
-
数据存储-提取和更正的数据存储在亚马逊 DynamoDB 表中,此外还有每个 PDF 文件的 JSON 文件。JSON 文件存储在 S3 存储桶中,可供下游处理和分析服务(例如 Amazon Athena 或 Amazon A QuickSightI)使用。 SageMaker
-
分析和可视化- QuickSight 分析数据并创建可视化效果,帮助生成所有已处理的 PDF 文件的见解。在中创建仪表板后 QuickSight,您可以与最终用户和业务团队共享。
注意事项
本指南的解决方案适用于处理格式相同且表单和表格布局一致的 PDF 文件。但是,您必须定义模板并提前对其进行编辑,以使该过程完全自动化,并使提取的数据可供分析。然后,该模板将在处理 Lambda 函数的过程中使用。
尽管此解决方案可以同时应用于不同的 PDF 文件类型,但您必须为每种 PDF 文件类型创建和定义单独的模板,并将它们存储在可访问的位置(例如 Amazon S3)。我们建议您为每种 PDF 文件类型使用唯一标识符,例如 PDF 文件名或 S3 存储桶中的不同文件夹。然后,Lambda 函数可以在处理 PDF 文件类型时调用相应的模板。
