本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
常见的扩展挑战
数据湖在初始部署后数据增长时会经历几个阶段。如果您没有使用可扩展架构来设计数据湖,您的组织可能会遇到挑战,并可能因数据湖的增长而处于不利地位。
以下各节说明了典型的数据湖的增长如何导致扩展挑战。
初始数据湖部署
下图显示了业务线 A 对数据湖进行初始部署后的架构。
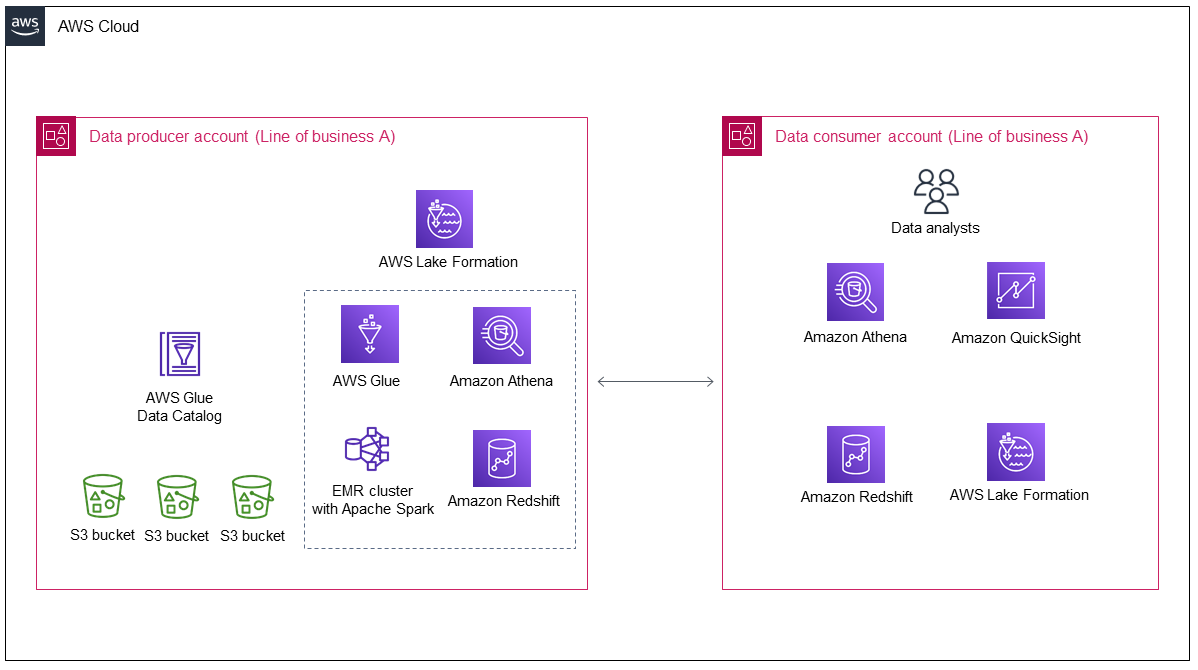
该图显示了以下组件:
-
数据生产者账户收集和处理数据,存储处理后的数据,并为其做好使用准备。
-
数据创建者账户中的数据存储在亚马逊简单存储服务 (Amazon S3) S imple S3 存储桶中,该存储桶可以有多个数据层。
-
您可以使用 AWS 服务进行数据处理(例如,AWS Glue和 Amazon EMR)。
-
数据创建者不仅在数据湖中生成和存储数据,还需要决定与数据使用者共享哪些数据以及如何共享这些数据。 AWS Lake Formation 管理数据生产者账户中的数据湖,此外还管理从数据创建者到数据使用者的跨账户数据共享。
-
数据使用者账户使用来自数据生产者账户的共享数据,用于特定的业务用例。
数据使用者增加
下图显示,当业务线 A 的数据增长时,会有更多的数据被带入数据湖。然后,数据湖吸引了更多的数据使用者来利用数据并从中获得价值。
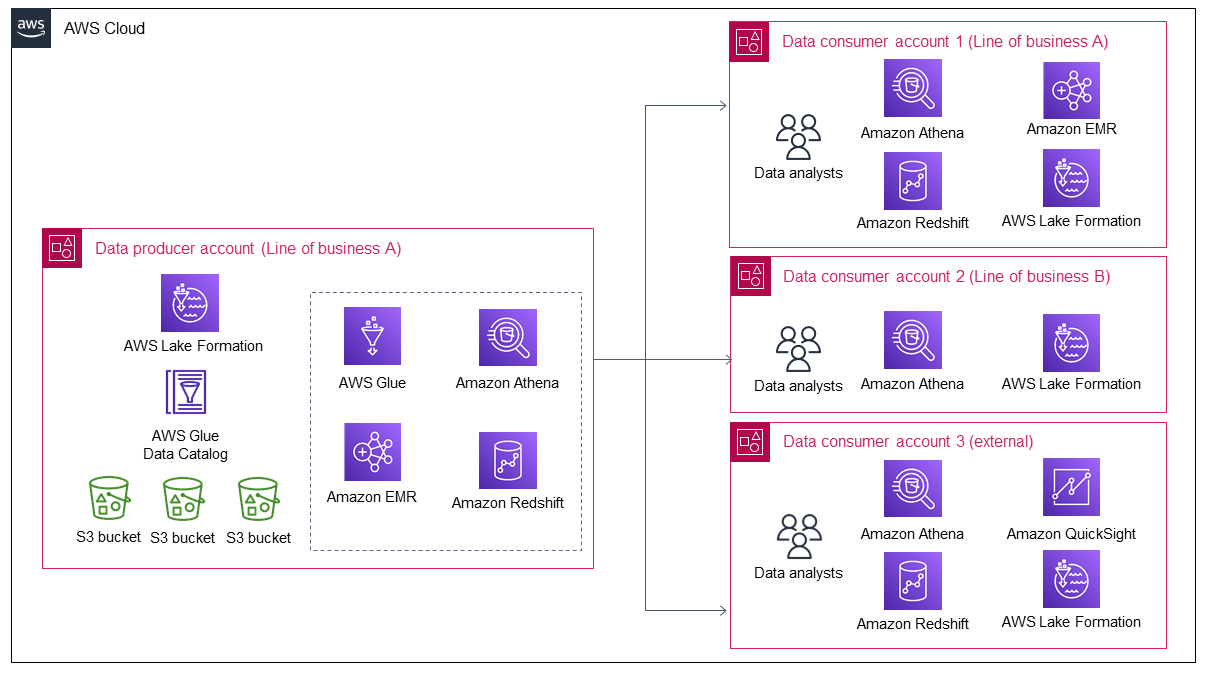
该图显示了组织如何从现有数据资产中产生近乎持续的价值,以及如何吸引更多的数据使用者。但是,当数据使用者增加时,数据生产者只有以下两个选择来适应这种增长:
-
手动管理个人数据使用者的数据共享和访问,这不是一种可扩展的方法。
-
开发用于数据共享和管理数据访问的自动化或半自动流程。尽管这可能是一个可扩展的选项,但由于内部和外部数据使用者的安全控制要求不同,因此需要大量的时间和精力来设计和构建。将来,任何解决方案改进都需要额外的时间和精力。
数据生产者增加
下图显示了多条业务线作为数据生产者加入时的数据湖架构。
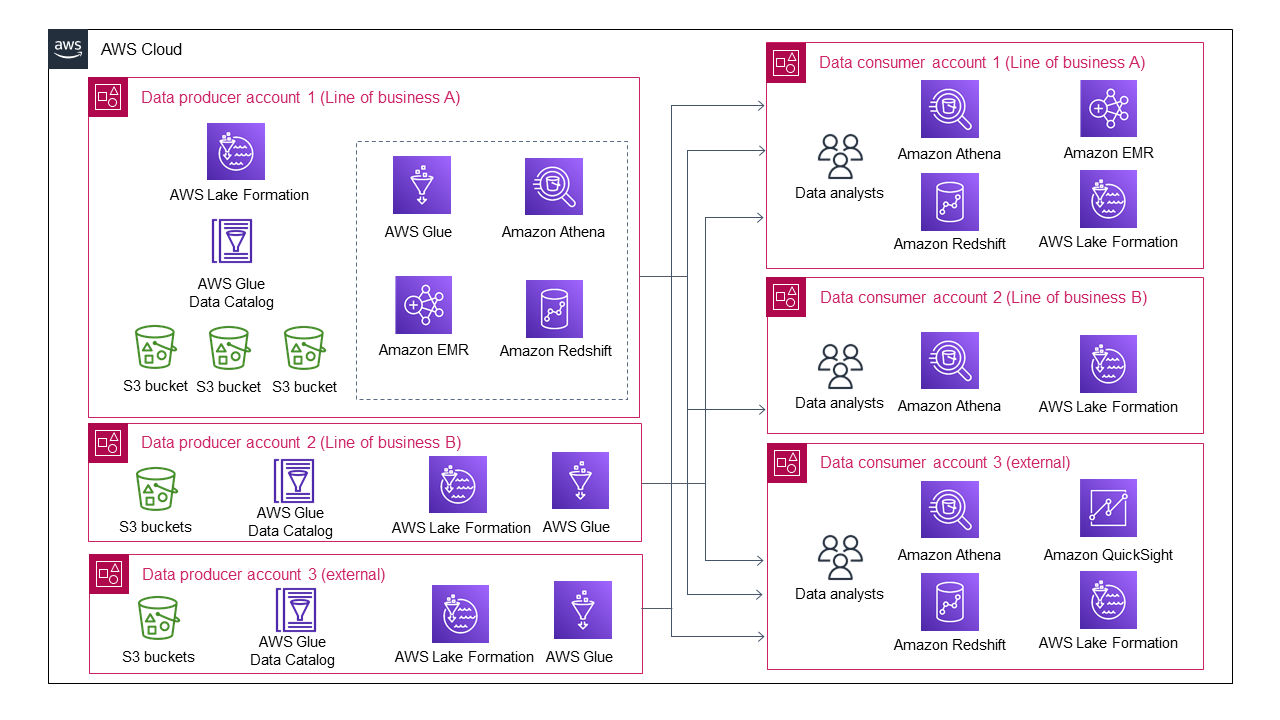
即使只有三个数据生成器和三个数据使用者,数据湖的架构也变得越来越复杂。
每个数据创建者都需要为多个数据使用者处理数据共享和数据访问管理。期望所有数据生产者都开发一种用于数据共享和数据访问管理的自动化或半自动流程是不现实的。一些数据生产者可能会选择不共享数据,从而避免负担不起的管理开销。同样,每个数据使用者都需要与多个数据生产者进行交互,以了解他们不同的数据消费流程。这意味着个人数据使用者在处理不同的数据共享模式时面临着不断增加的管理开销。
在许多组织中,这种数据湖会导致瓶颈,无法增长或扩展。这可能意味着您的组织必须重新设计和重建其数据湖以消除瓶颈,这可能会花费大量时间、资源和金钱。
