本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
分布式可用性组
分布式可用性组跨越两个独立的可用性组。您可以将其视为可用性组的可用性组。底层可用性组是在两个不同的 WSFC 集群上配置的。参与分布式可用性组的可用性组无需共享同一位置。它们可以是物理的或虚拟的,可以是本地的或在公共云中。分布式可用性组中的可用性组不必运行相同版本的 SQL Server。目标数据库实例可以运行比源数据库实例更高版本的 SQL Server。
分布式可用性组架构为您提供了一种灵活的方式,可以在上重新托管任务关键型 SQL Server 实例或数据库。 AWS它提供了一种混合解决方案,用于在 AWS上直接迁移(或提升和改造)您的关键 SQL Server 数据库。
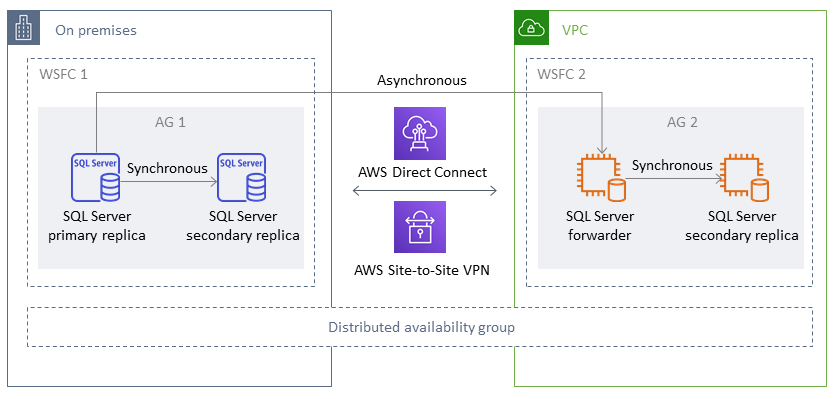
使用分布式可用性组架构比将现有本地 WFSC 集群扩展到更高效。 AWS数据只能从本地主服务器传输到其中一个 AWS 副本(转发器)。转发器负责向中的其他辅助只读副本发送数据。 AWS
在下图中,第一个 WSFC 集群 (WSFC 1) 托管在本地并具有本地可用性组 (AG 1)。第二个 WSFC 集群 (WSFC 2) 托管在上 AWS 并有一个 AWS 可用性组 (AG 2)。 AWS Direct Connect
注意
在任何给定时间点,只有一个数据库可用于写入操作。您可以使用剩余的辅助副本进行读取操作。要扩展您的读取工作负载,您可以在 AWS上的多个可用区中添加更多只读副本。
有关分布式可用性组的更多信息,请参阅:
