本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
局部可解释性
最流行的复杂模型局部可解释性方法基于 Shapley 加性解释 (SHAP) [8] 或积分梯度 [11]。每种方法都有许多专属于某个模型类型的变体。
对于树集成模型,请使用树形 SHAP
在基于树的模型情况下,动态编程允许快速、精确地计算每个特征的 Shapley值
对于神经网络和可微分模型,请使用积分梯度和传导
积分梯度提供了一种计算神经网络中特征归因的简明方法。传导建立在积分梯度之上,以帮助您解释来自神经网络某些部分(例如层和单个神经元)的归因。(参见 [3,11],实现过程见于 https://captum.ai/
对于所有其他情况,请使用 Kernel SHAP
您可以使用 Kernel SHAP 计算任何模型的特征归因,但它是计算完整 Shapley 值的近似值,而且仍然在计算上代价高昂(参见 [8])。Kernel SHAP 必备的计算资源随着特征的数目迅速增长。这需要可能降低解释过程保真度、可重复性和稳健性的近似方法。Amazon SageMaker Clarify 提供诸多便捷方法,这些方法可以部署用于计算单独实例中 Kernel SHAP 值的预制容器。(对于示例,请参阅 GitHub 存储库 SageMaker Clarify 的公平性和可解释性
对于单一树模型,分裂变量和叶值提供了一个立即可解释的模型,而前面讨论的方法并未提供额外见解。类似地,对于线性模型,系数清楚地解释了模型行为。(SHAP 和积分梯度方法都返回由系数决定的贡献。)
SHAP 和基于积分梯度的方法都有弱点。SHAP 要求归因从所有特征组合的加权平均值中导出。若诸特征之间存在强互作,则估计特征重要性时,以这种方式获得的归因可能有误导性。基于积分梯度的方法可能难以解释,因为大型神经网络中存在的维度数庞大,并且这些方法对基点的选择敏感。更广义地,模型可以按意外方式使用特征实现某个水平的性能,并且这些特征可能因模型而异,特征重要性始终依赖模型。
推荐的可视化过程
下图展示了几种推荐的方法来可视化前面几部分中讨论的局部解释。对于表格数据,我们建议使用显示归因的简单条形图,从而可以轻松比较这些归因并将它们用于推断模型正如何做出预测。

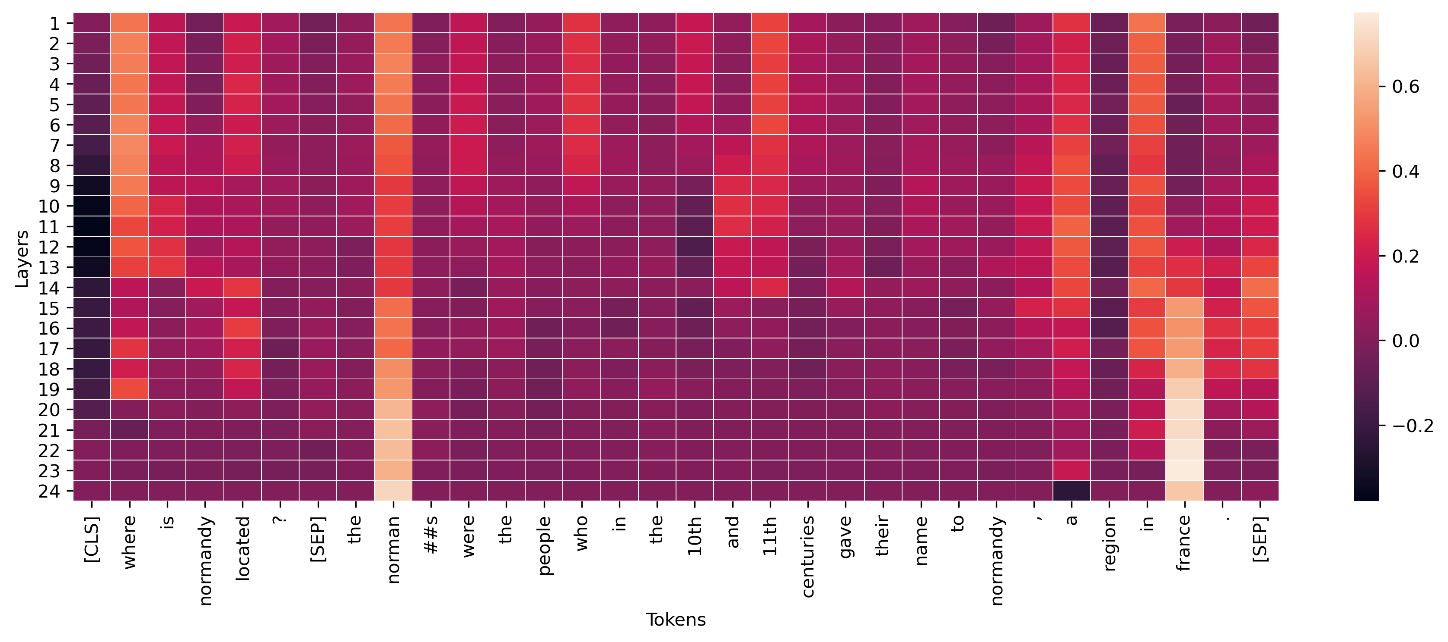
对于文本数据,嵌入令牌导致庞大数目的标量输入。前几部分中推荐的方法为嵌入的每个维度和每个输出生成一个归因。为了将这个信息提炼成可视化过程,给定令牌的归因可以求和。以下示例显示在 SQUAD 数据集上训练的基于 BERT 的问答模型的归因总和。在这种情况下,已预测且真实的标签是词汇“法国”的令牌。

否则,可以将令牌归因的向量范数指定为总归因值,如以下示例中所示。

对于深度学习模型的中间层,类似的聚合可以应用于可视化过程传导,如以下示例中所示。用于转换器层的令牌传导的这个向量范数显示了最终令牌预测的最终激活情况(“法国”)。
概念激活向量提供了一种更详细地研究深度神经网络的方法 [6]。这种方法从已受训网络的某层中提取特征,并根据这些特征训练线性分类器以推断该层中的信息。例如,您可能想要确定一个基于 BERT 的语言模型的哪一层包含最多词性信息。在这种情况下,您可以在每层输出上训练线性词性部分模型,然后粗略估计性能最好的分类器与包含最多部分语音信息的层相关联。尽管我们不建议这种方法作为解释神经网络的主要方法,但它可能是用于更详细研究的一个选项和设计网络架构的辅助。
