本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
文档覆盖范围和准确性 – 域内
我们将深度融合的预测性能与测试时应用的 dropout、MC dropout 和朴素 softmax 函数进行了比较,如下图所示。经过推断,不确定性最高的预测结果会在不同程度上被剔除,得出的剩余数据覆盖率从 10% 到 100% 不等。我们预计深度融合能够更有效地识别不确定的预测,因为它更能量化认知不确定性;换而言之,可以识别数据中模型经验较少的区域。对于不同的数据覆盖级别,应该反映出更高准确性。对于每个深度融合,我们使用了 5 个模型并应用了 20 次推理。对于 MC dropout,我们对每个模型应用了推理 100 次。我们为每种方法使用了相同的超参数集和模型架构。
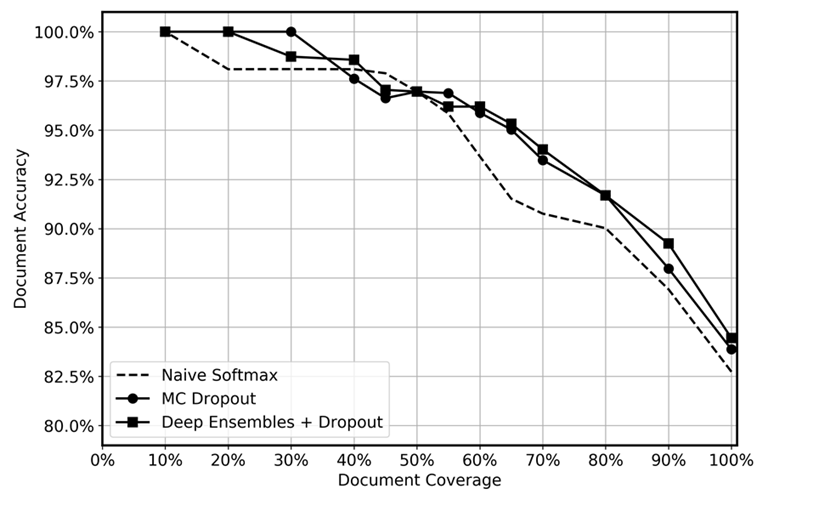
该图显示,与朴素 softmax 相比,使用深度融合和 MC dropout 似乎略胜一筹。这在 50-80% 的数据覆盖范围中最为明显。为什么不是更高呢? 正如深度融合部分所提到的那样,深度融合的力量来自于所采取的不同损失轨迹。在这种情况下,我们使用的是预训练模型。尽管我们对整个模型进行了微调,但绝大多数权重都是从预训练模型初始化的,只有少数隐藏层是随机初始化的。因此,我们推测,由于几乎没有多样化,对大型模型进行预训练可能会导致过度自信。据我们所知,以前从未在迁移学习场景中测试过深度融合的功效,我们认为这是未来研究的一个令人兴奋的领域。
