本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
温度缩放
在分类问题中,假设预测概率(softmax 输出)代表预测类别的真实正确性概率。但是,尽管这种假设对于十年前的模型来说可能是合理的,但对于当今的现代神经网络模型来说却并非如此(Guo 等人,2017 年)。模型预测概率与模型预测的可信度之间失去联系将阻碍现代神经网络模型应用于现实世界的问题,例如在决策系统中。精确了解模型预测的置信度分数是构建强大且值得信赖的机器学习应用程序所需的最关键的风险控制设置之一。
现代神经网络模型往往具有数百万个学习参数的大型架构。此类模型中预测概率的分布通常高度偏向于 1 或 0,这意味着模型过于自信,这些概率的绝对值可能毫无意义。(此问题与数据集中是否存在类别不平衡无关。) 在过去十年中,通过后处理步骤重新校准模型的朴素概率,开发了各种用于创建预测置信度得分的校准方法。本部分介绍了一种称为温度缩放的校准方法,这是一种简单而有效的重新校准预测概率的技术(Guo 等人,2017年)。温度缩放是 Platt Logistic Scaling(Platt 1999)的单参数版本。
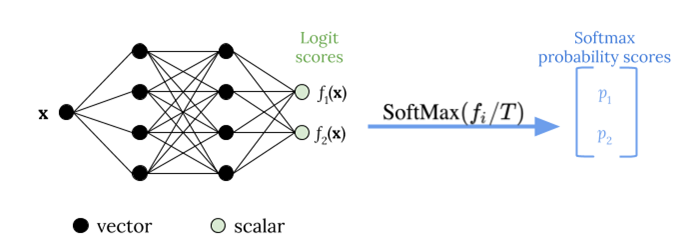
在应用 softmax 函数之前,温度缩放使用单个标量参数 T > 0(其中 T 是温度)来重新调整对数分数,如下图所示。由于所有类别都使用相同的 T,因此带缩放的 softmax 输出与未缩放的输出具有单调关系。当 T = 1 时,您可以使用默认的 softmax 函数恢复原始概率。在 T > 1 的过于自信模型中,重新校准的概率的值低于原始概率,并且它们在 0 和 1 之间的分布更加均匀。
为训练好的模型获得最佳温度 T 的方法是最小化被搁置的验证数据集的负对数似然。
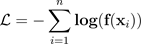
我们建议您将温度缩放方法作为模型训练过程的一部分:模型训练完成后,使用验证数据集提取温度值 T,然后在 softmax 函数中使用 T 重新缩放对数值。根据使用基于 BERT 的模型在文本分类任务中进行的实验,温度 T 通常介于 1.5 和 3 之间。
下图说明了温度缩放方法,该方法在将对数分数传递给 softmax 函数之前应用温度值 T。
通过温度缩放校准的概率可以近似代表模型预测的置信度得分。这可以通过创建可靠性图进行定量评估(Guo 等人,2017年),该图表示预期精度的分布与预测概率的分布之间的一致性。
温度缩放也被评估为量化校准概率中总预测不确定性的有效方法,但在数据漂移等场景中,它在捕捉认知不确定性方面并不可靠(Ovadia 等人,2019 年)。考虑到实现的便捷性,我们建议您将温度缩放应用于深度学习模型输出,以构建用于量化预测不确定性的可靠解决方案。
