本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据准备和清理
数据准备和清理是数据生命周期中最重要但最耗时的阶段之一。下图显示了数据准备和清理阶段如何融入数据工程自动化和访问控制生命周期。
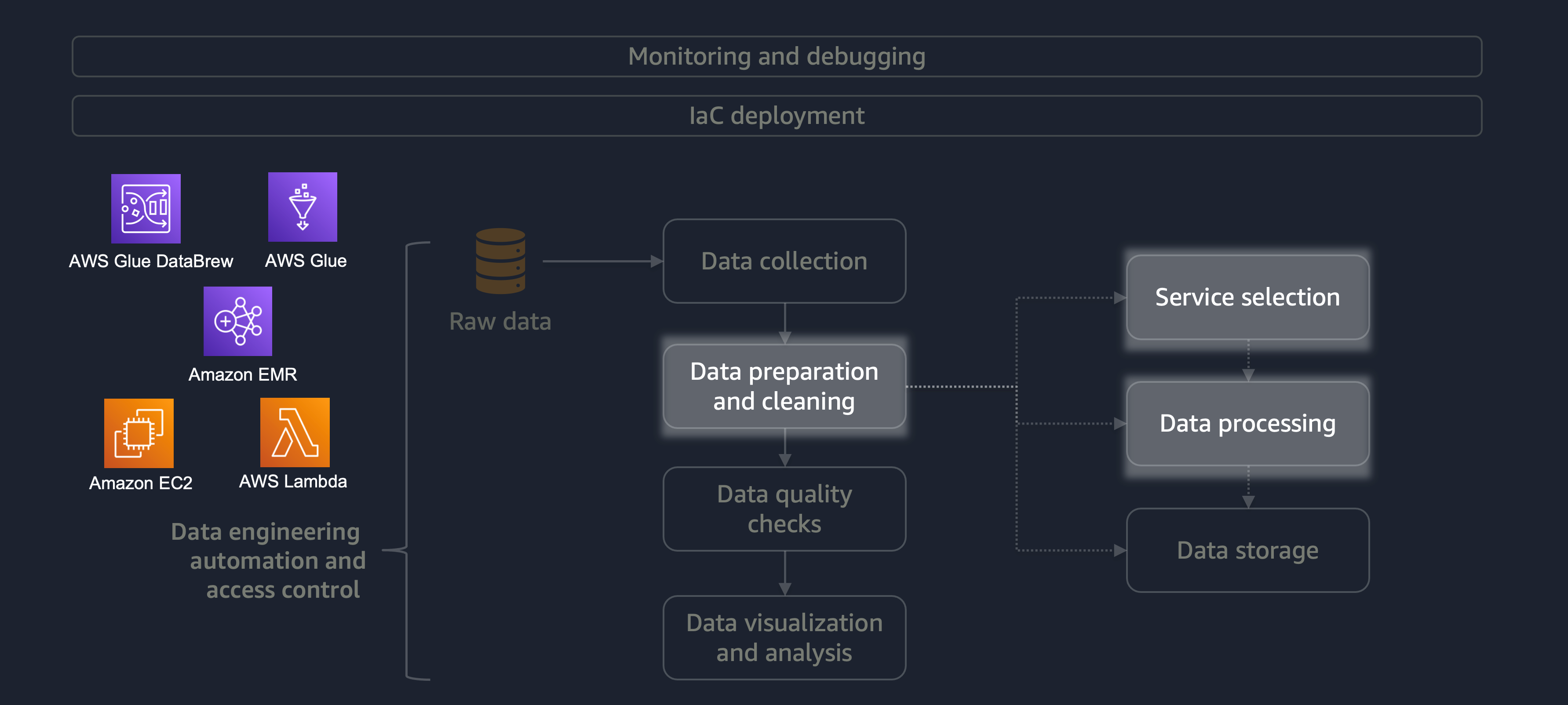
以下是一些数据准备或清理的示例:
-
将文本列映射到代码
-
忽略空列
-
用
0、None或填充空数据字段'' -
匿名化或屏蔽个人身份信息 (PII)
如果您的工作负载很大,包含各种数据,那么我们建议您使用 A mazon EMRDataFrame或使用横DynamicFrame向处理。此外,您可以使用 AWS Glu DataBrew
对于不需要分布式处理且可在 15 分钟内完成的小型工作负载,我们建议您使用 AWS Lambda
必须选择合适的 AWS 服务进行数据准备和清理,并了解您的选择所涉及的权衡。例如,假设你从 AWS Glue 和 Amazon EMR DataBrew 中进行选择的场景。如果 ETL 任务不频繁,AWS Glue 是理想的选择。不经常的工作每天进行一次、每周一次或每月一次。您可以进一步假设您的数据工程师精通编写 Spark 代码(适用于大数据用例)或一般脚本编写。如果工作更频繁,那么经常运行 AWS Glue 可能会变得昂贵。在本例中,Amazon EMR 提供分布式处理功能,并提供无服务器版本和基于服务器的版本。如果您的数据工程师不具备合适的技能,或者您必须快速交付结果,那么 DataBrew 这是一个不错的选择。 DataBrew 可以减少开发代码的工作量并加快数据准备和清理过程。
处理完成后,ETL 流程中的数据将存储在 AWS 上。存储的选择取决于您要处理的数据类型。例如,您可能正在处理非关系数据,例如图形数据、键值对数据、图像、文本文件或关系结构化数据。
如下图所示,您可以使用以下 AWS 服务进行数据存储:
-
Amazon S3
存储非结构化数据或半结构化数据(例如 Apache Parquet 文件、图像和视频)。 -
Amazon Neptune
存储您可以使用 SPARQL 或 GREMLIN 查询的图形数据集。 -
Amazon Keyspaces(适用于 Apache Cassandra)
存储与 Apache Cassandra 兼容的数据集。 -
亚马逊 Aurora
存储关系数据集。 -
Amazon Dy
namoDB 将键值或文档数据存储在 NoSQL 数据库中。 -
Amazon Redshift 将
结构化数据的工作负载存储在数据仓库中。
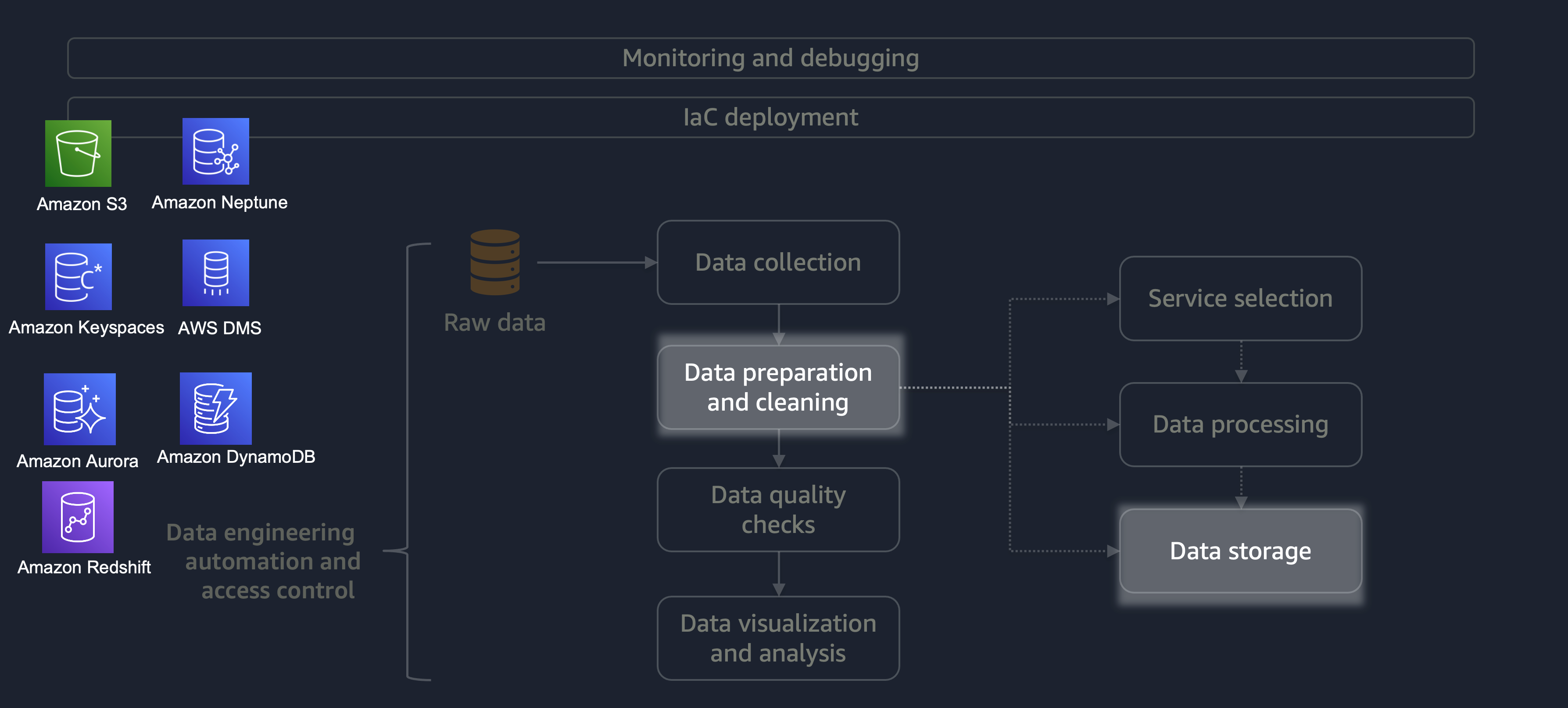
通过使用具有正确配置的正确服务,您可以以最高效、最有效的方式存储数据。这样可以最大限度地减少数据检索所涉及的工作量。
