本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
性能效率支柱
Well-Architect AWS ed Framework 的性能效率支柱侧重于如何在摄取或查询数据时优化性能。性能优化是一个循序渐进的持续过程,包括以下内容:
-
确认业务需求
-
衡量工作负载性能
-
识别性能不佳的组件
-
调整组件以满足您的业务需求
性能效率支柱提供了特定于用例的指南,可以帮助您确定要使用的正确图表数据模型和查询语言。它还包括在向 Neptune Analytics(海王星分析)摄取数据和使用数据时应遵循的最佳实践。
绩效效率支柱侧重于以下关键领域:
-
图形建模
-
查询优化
-
调整图表大小
-
写入优化
了解用于分析的图形建模
《在 Amazon Neptune 上应用 AWS Well-Architected Framework》指南讨论了如何提高性能效率的图形建模。影响性能的建模决策包括选择需要哪些节点和边 IDs、它们的标签和属性、边的方向、标签应该是通用标签还是特定标签,以及查询引擎在图表中导航以处理常见查询的效率。
这些注意事项也适用于Neptune Analytics;但是,区分交易和分析使用模式很重要。在事务数据库(例如 Neptune 数据库)中高效查询的图形模型可能需要重塑才能进行分析。
例如,假设Neptune数据库中的欺诈图表,其目的是检查信用卡付款中的欺诈模式。此图表可能包含代表账户和付款的账户、付款和功能(例如电子邮件地址、IP 地址、电话号码)的节点。此关联图支持诸如遍历可变长度路径之类的查询,该路径从给定付款开始,需要几跳才能找到相关的功能和账户。下图显示了这样的图表。
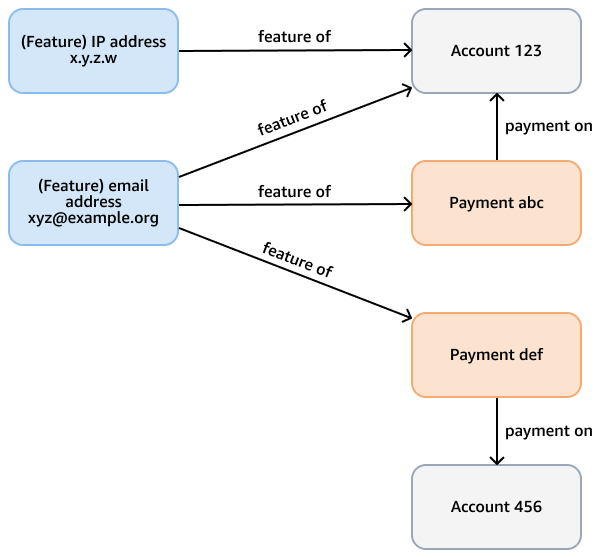
分析要求可能更具体,例如查找通过功能关联的账户社区。为此,您可以使用弱连接组件 (WCC) 算法。在前面的示例中,针对模型运行它效率低下,因为它需要遍历几种不同类型的节点和边。下图中的模型效率更高。如果账户本身(或来自账户的付款)共享一项功能,则它会将account节点与shares feature优势联系起来。例如,Account 123具有电子邮件功能xyz@example.org,并Account 456使用相同的电子邮件进行付款(Payment def)。

WCC 的计算复杂度为O(|E|logD),其中|E|是图中的边数,D是连接节点的直径(最长路径的长度)。由于事务模型省略了不必要的节点和边,因此它优化了边的数量和直径,并降低了 WCC 算法的复杂性。
使用 Neptune Analytics 时,请根据所需的算法和分析查询进行回溯。如有必要,请重塑模型以优化这些查询。在将数据加载到图表之前,您可以重塑模型,也可以编写修改图表中现有数据的查询。
优化查询
请按照以下建议优化 Neptune Analytics 查询:
-
使用参数化查询和查询计划缓存,默认情况下处于启用状态。使用计划缓存时,引擎会准备查询以供日后使用(前提是查询在 100 毫秒或更短的时间内完成),这样可以节省后续调用的时间。
-
对于慢速查询,请运行解释计划以发现瓶颈并相应地进行改进。
-
如果您使用向量相似度搜索,请确定较小的嵌入是否产生准确的相似度结果。您可以更高效地创建、存储和搜索较小的嵌入内容。
-
遵循记录在案的最佳实践,在 Neptune Analytics 中使用 OpenCyph er。例如,在 UNWIND 子句中使用扁平化地图,并尽可能指定边缘标签。
-
使用图形算法时,要了解算法的输入和输出、其计算复杂性以及它的工作原理。
-
在调用图形算法之前,请使用子
MATCH句最小化输入节点集。例如,要限制节点进行广度优先搜索 (BFS),请按照 Neptune Analytics 文档中提供的示例进行操作。 -
如果可能,对节点和边缘标签进行筛选。例如,BFS 具有用于筛选对特定节点标签 (
vertexLabel) 或特定边缘标签 () 的遍历的输入参数。edgeLabels -
使用诸如之类的边界参数
maxDepth来限制结果。 -
用
concurrency参数进行实验。尝试使用值为 0,它使用所有可用的算法线程来并行化处理。将其与单线程执行进行比较,方法是将参数设置为 1。算法可以在单个线程中更快地完成,尤其是在较小的输入中,例如浅广度优先搜索,在这种情况下,并行性不会显著缩短执行时间,并且可能会带来开销。 -
在相似类型的算法之间进行选择。例如,Bellman-Ford 和 delta-steping 都是单源最短路径算法。使用自己的数据集进行测试时,请尝试两种算法并比较结果。增量步进通常比贝尔曼-福特快,因为它的计算复杂性较低。但是,性能取决于数据集和输入参数,尤其是
delta参数。
-
优化写入
请按照以下做法优化 Neptune Analytics 中的写入操作:
-
寻找最有效的方法将数据加载到图表中。从 Amazon S3 中的数据加载时,如果数据大小超过 50 GB,则使用批量导入。对于较小的数据,请使用批量加载。如果您在运行批量加载时遇到 out-of-memory错误,请考虑增加 m-ncu 值或将负载分成多个请求。实现此目的的一种方法是在 S3 存储桶中将文件拆分为多个前缀。在这种情况下,请分别为每个前缀调用 batch load。
-
使用批量导入或批处理加载器填充初始图表数据集。仅对较小的更改使用事务性 OpenCypher 创建、更新和删除操作。
-
使用批量导入或并发度为 1(单线程)的批处理加载器将嵌入数据提取到图表中。尝试使用以下方法之一预先加载嵌入内容。
-
评估矢量相似度搜索算法中精确相似度搜索所需的向量嵌入维度。如果可能,请使用较小的尺寸。这样可以加快嵌入的加载速度。
-
如果需要,使用变异算法来记住算法结果。例如,度突变中心性算法会找到每个输入节点的度数,并将该值作为节点的属性写入。如果这些节点周围的连接随后没有改变,则该属性将保持正确的结果。无需再次运行该算法。
-
如果需要重新开始,请使用图表重置管理操作来清除所有节点、边和嵌入内容。如果图形很大,则使用 OpenCypher 查询删除所有节点、边和嵌入是不可行的。对大型数据集进行一次删除查询可能会超时。随着大小的增加,数据集需要更长的时间才能移除,交易规模也会增加。相比之下,完成图表重置的时间大致保持不变,并且该操作提供了在运行快照之前创建快照的选项。
大小合适的图表
总体性能取决于 Neptune Analytics 图表的预配置容量。容量以称为内存优化的 Neptune 容量单位 (m-) 的单位来衡量。NCUs确保您的图表大小足以支持您的图表大小和查询。请注意,增加容量并不一定能提高单个查询的性能。
如果可能,请通过从现有来源(例如 Amazon S3 或现有 Neptune 集群或快照)导入数据来创建图表。您可以对最小容量和最大容量设置界限。您也可以更改现有图表上的预配置容量。
监控诸如NumQueuedRequestsPerSec、、NumOpenCypherRequestsPerSecGraphStorageUsagePercentGraphSizeBytes、和之类的 CloudWatch 指标,CPUUtilization以评估图表的大小是否合适。确定是否需要更多容量来支持您的图表大小和负载。有关如何解释其中一些指标的更多信息,请参阅卓越运营支柱部分。
