本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
亚马逊 Redshift 中的 SQL 查询处理
Amazon Redshift 通过分析程序和优化程序路由提交的 SQL 查询,以制订查询计划。然后,执行引擎将查询计划转换为代码并将代码发送到计算节点执行。在设计查询计划之前,了解查询处理的工作原理至关重要。
查询计划和执行工作流程
下图提供了查询计划和执行工作流程的高级视图。
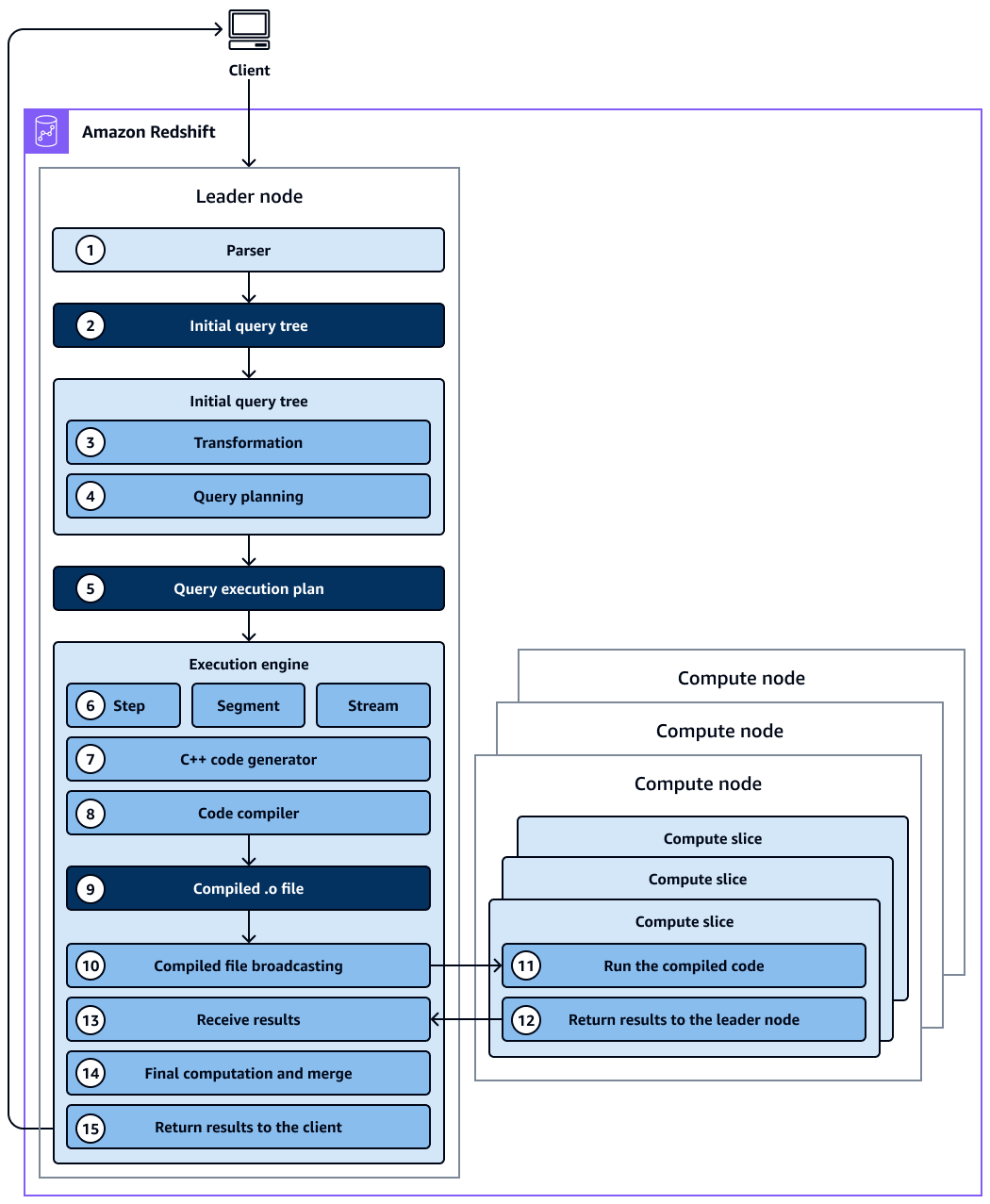
图表显示了以下工作流:
-
Amazon Redshift 集群中的领导节点接收查询并解析 SQL 语句。
-
解析器生成初始查询树,该树是原始查询的逻辑表示形式。
-
查询优化器获取初始查询树并对其进行评估,分析表统计信息以确定联接顺序和谓词选择性,并在必要时重写查询以最大限度地提高其效率。有时,单个查询可以在后台写成多个依赖语句。
-
优化程序会生成一个查询计划以最佳性能进行执行(如果上一步导致多个查询,则生成多个查询计划)。查询计划指定执行选项,例如执行顺序、网络操作、联接类型、联接顺序、聚合选项和数据分布。
-
查询计划包含有关运行查询所需的各个操作的信息。您可以使用
EXPLAIN命令查看查询计划。查询计划是分析和优化复杂查询的基本工具。 -
查询优化器将查询计划发送到执行引擎。执行引擎检查已编译的计划缓存中是否存在查询计划匹配项,并使用已编译的缓存(如果找到)。否则,执行引擎会将查询计划转换为步骤、段和流:
-
步骤是在查询执行期间发生的单个操作。步骤由标签标识(例如、
scan、disthjoin、或merge)。步长是最小的单位。您可以组合步骤,以便计算节点可以执行查询、联接或其他数据库操作。 -
区段是指查询中的一段,它结合了单个流程可以完成的几个步骤。分段是计算节点切片可执行的最小编译单元。切片是 Amazon Redshift 中并行处理的单元。
-
流是要在可用的计算节点切片上分割出来的分段的集合。流中的片段在节点切片之间并行运行。因此,同一分段中的相同步骤也会在多个切片中并行执行。
-
-
代码生成器接收翻译后的计划,并为每个片段生成一个 C++ 函数。
-
生成的 C++ 函数由 GNU 编译器集合编译并转换为 O (
.o) 文件。 -
编译后的代码(O 文件)将运行。编译的代码运行速度比解释的代码快,并且使用的计算容量更少。
-
然后将编译后的 O 文件广播到计算节点。
-
每个计算节点由多个计算切片组成。计算切片并行运行查询段。Amazon Redshift 利用优化的网络通信、内存和磁盘管理,将中间结果从一个查询计划步骤传递到下一个查询计划步骤。这还有助于加快查询执行速度。请考虑以下事项:
-
步骤 6、7、8、9、10 和 11 对每个直播执行一次。
-
引擎为一个流创建可执行分段,并将这些分段发送到计算节点。
-
前一个直播的片段完成后,引擎会为下一个直播生成片段。通过这种方式,引擎可以分析先前流中发生的情况(例如,操作是否基于磁盘),以影响下一个流中分段的生成。
-
-
计算节点完成后,它们会将查询结果返回到领导节点进行最终处理。领导节点将数据合并到单个结果集中,并解决任何必需的排序或聚合问题。
-
领导节点将结果返回给客户端。
下图显示了流、分段、步骤和计算节点切片的执行工作流程。记住以下内容:
-
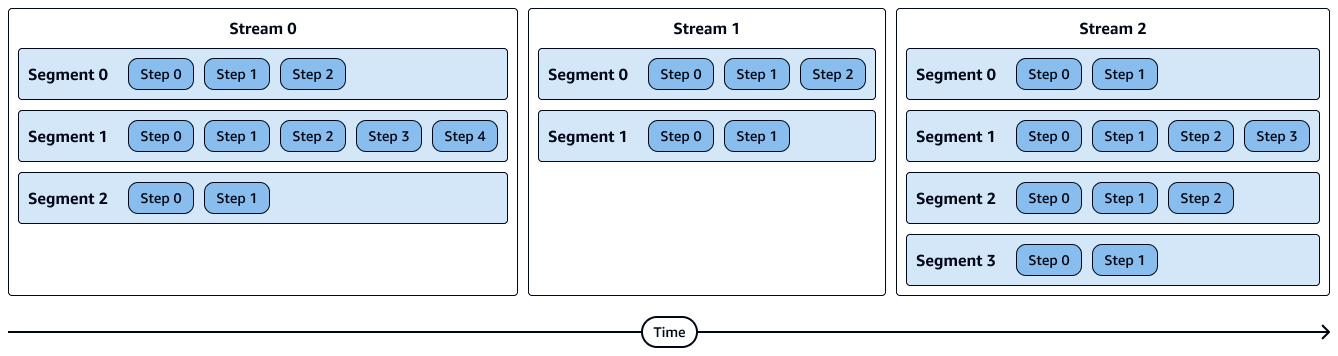
区段中的步骤按顺序运行。
-
直播中的片段并行运行。
-
直播按顺序播放。
-
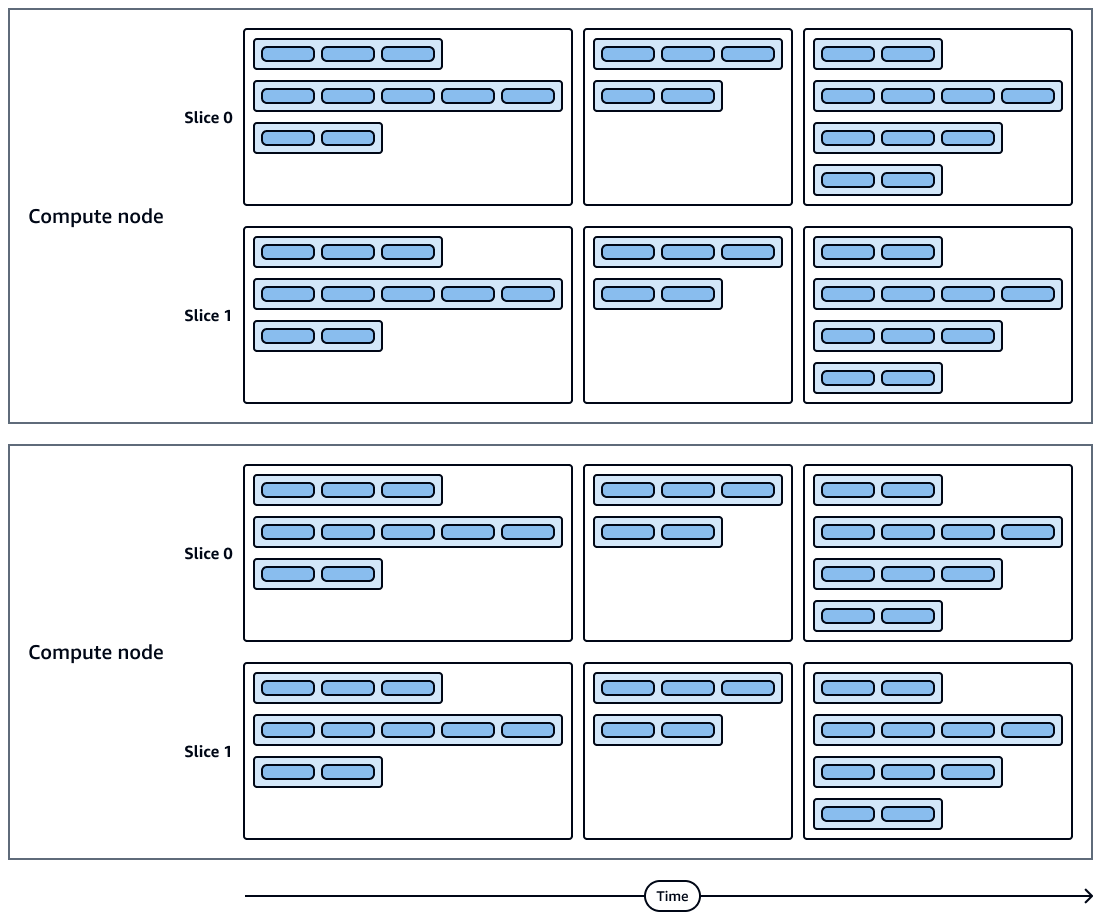
计算节点切片并行运行。
下图显示了流、分段和步骤的直观表示。每个片段包含多个步骤,每个流包含多个片段。
下图显示了查询执行和计算节点切片的可视化表示。每个计算节点都包含多个切片、流、分段和步骤。
额外注意事项
我们建议您在处理查询时考虑以下几点:
-
缓存的编译代码在同一集群上的会话之间共享,因此即使使用不同的参数,后续执行同一查询也会更快。
-
在对查询进行基准测试时,我们建议您始终比较第二次执行查询的时间,因为第一次执行时间包括编译代码的开销。有关更多信息,请参阅 Amazon Redshift 查询最佳实践指南中的查询性能因素。
-
如有必要,计算节点可以在查询执行期间向领导节点返回一些数据。例如,如果您有一个带有子
LIMIT句的子查询,则在集群中重新分配数据以进行进一步处理之前,将限制应用于领导节点。
