本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
用例:使用增强的患者数据构建医疗智能应用程序
生成式人工智能可以通过增强临床和管理功能来帮助提高患者护理和工作人员的工作效率。人工智能驱动的图像分析(例如解释超声图)可加快诊断过程并提高准确性。它可以提供关键见解,为及时的医疗干预提供支持。
当您将生成式 AI 模型与知识图相结合时,您可以自动按时间顺序组织电子患者记录。这可以帮助您整合来自医患互动、症状、诊断、实验室结果和图像分析的实时数据。这为医生提供了全面的患者数据。这些数据可以帮助医生做出更准确、更及时的医疗决策,从而提高患者疗效和医疗保健提供者的工作效率。
解决方案概述
人工智能可以通过综合患者数据和医学知识来提供有价值的见解,从而增强医生和临床医生的能力。该检索增强生成 (RAG) 解决方案是一个医疗智能引擎,它使用来自数百万次临床互动的一整套患者数据和知识。它利用生成式人工智能的力量来创建基于证据的见解,以改善患者护理。它旨在增强临床工作流程,减少错误并改善患者预后。
该解决方案包括由提供支持的自动图像处理功能。 LLMs此功能减少了医务人员必须花费在手动搜索相似诊断图像和分析诊断结果上的时间。
下图显示了此解决方案 end-to-end-workflow的。它使用亚马逊 Neptune、亚马逊 SageMaker AI、亚马逊 OpenSearch 服务,以及亚马逊 Bedrock 中的基础模型。对于与 Neptune 中的医学知识图谱交互的上下文检索代理,您可以在 Amazon Bedrock 代理和 Amazon Bedrock 代理之间进行选择 LangChain 代理人。
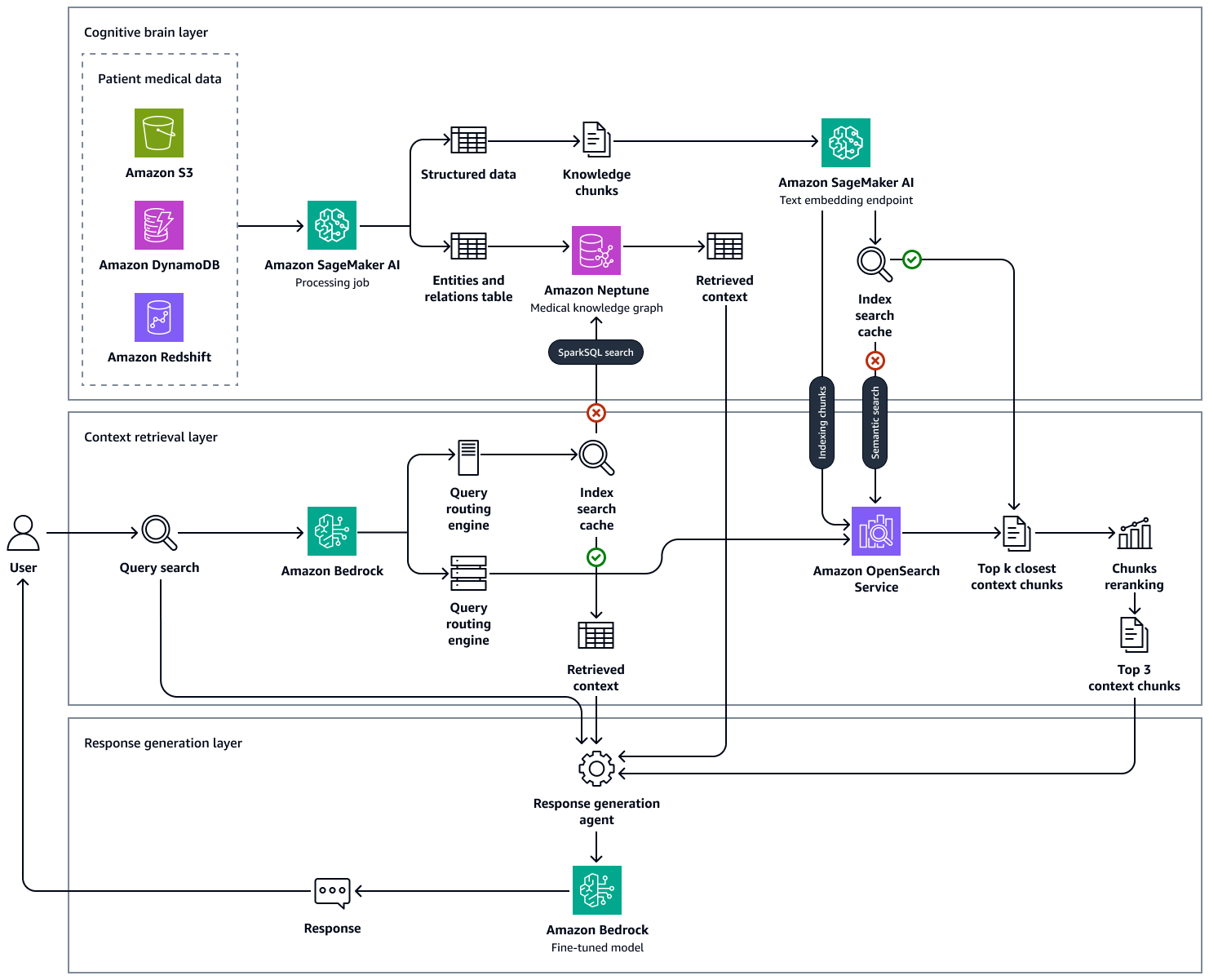
在我们对医学问题样本的实验中,我们观察到,我们使用Neptune中维护的知识图谱、存放临床知识库的 OpenSearch矢量数据库和Amazon Bedrock中的方法 LLMs 得出的最终答案以事实为基础,通过减少误报和提高真阳性,准确得多。该解决方案可以生成有关患者健康状况的循证见解,旨在改善临床工作流程,减少错误并改善患者预后。
构建此解决方案包括以下步骤:
步骤 1:发现数据
您可以使用许多开源医疗数据集来支持医疗保健人工智能驱动解决方案的开发。其中一个数据集是 MIMIC-IV 数据集
您也可以使用一个数据集,该数据集提供带注释、去识别化的患者出院摘要,这些摘要是专门为研究目的精心策划的。出院摘要数据集可以帮助您尝试实体提取,从而使您能够从文本中识别出关键的医疗实体(例如病症、手术和药物)。 第 2 步:建立医学知识图谱本指南介绍了如何使用从 MIMIC-IV 和出院摘要数据集中提取的结构化数据来创建医学知识图表。该医学知识图谱是医疗保健专业人员高级查询和决策支持系统的支柱。
除了基于文本的数据集外,您还可以使用图像数据集。例如,肌肉骨骼 X 光片 (MURA) 数据集,这是一个包含骨骼多视角射线照相图像
第 2 步:建立医学知识图谱
对于任何想要建立基于庞大知识库的决策支持系统的医疗保健组织来说,关键的挑战是找到和提取临床记录、医学期刊、出院摘要和其他数据源中存在的医疗实体。您还需要从这些病历中获取时间关系、受试者和确定性评估,以便有效地使用提取的实体、属性和关系。
第一步是通过对基础模型(例如Amazon Bedrock中的Llama 3)使用少量提示从非结构化医学文本中提取医学概念。Few-shot 提示是指在让 LLM 执行类似任务之前,向其提供少量演示任务和所需输出的示例。使用基于 LLM 的医学实体提取器,您可以解析非结构化医学文本,然后生成医学知识实体的结构化数据表示形式。您还可以存储患者属性以进行下游分析和自动化。实体提取过程包括以下操作:
-
提取有关医学概念的信息,例如疾病、药物、医疗器械、剂量、用药频率、用药持续时间、症状、医疗程序及其临床相关属性。
-
捕获功能特征,例如提取的实体、受试者和确定性评估之间的时间关系。
-
扩展标准医学词汇,例如:
-
汇总出院记录并从笔录中得出医学见解。
下图显示了创建实体、属性和关系的有效配对组合的实体提取和架构验证步骤。您可以在亚马逊简单存储服务 (Amazon S3) Simple Storage Service 中存储非结构化数据,例如出院摘要或患者记录。您可以在 Amazon Redshift 和 Amazon DynamoDB 中存储结构化数据,例如企业资源规划 (ERP) 数据、电子患者记录和实验室信息系统。您可以构建 Amazon Bedrock 实体创建代理。该代理可以整合服务,例如亚马逊 SageMaker 人工智能数据提取管道、Amazon Textract和Amazon Comprehend Medical,从结构化和非结构化数据源中提取实体、关系和属性。最后,您可以使用 Amazon Bedrock 架构验证代理来确保提取的实体和关系符合预定义的图形架构,并保持节点边缘连接和关联属性的完整性。
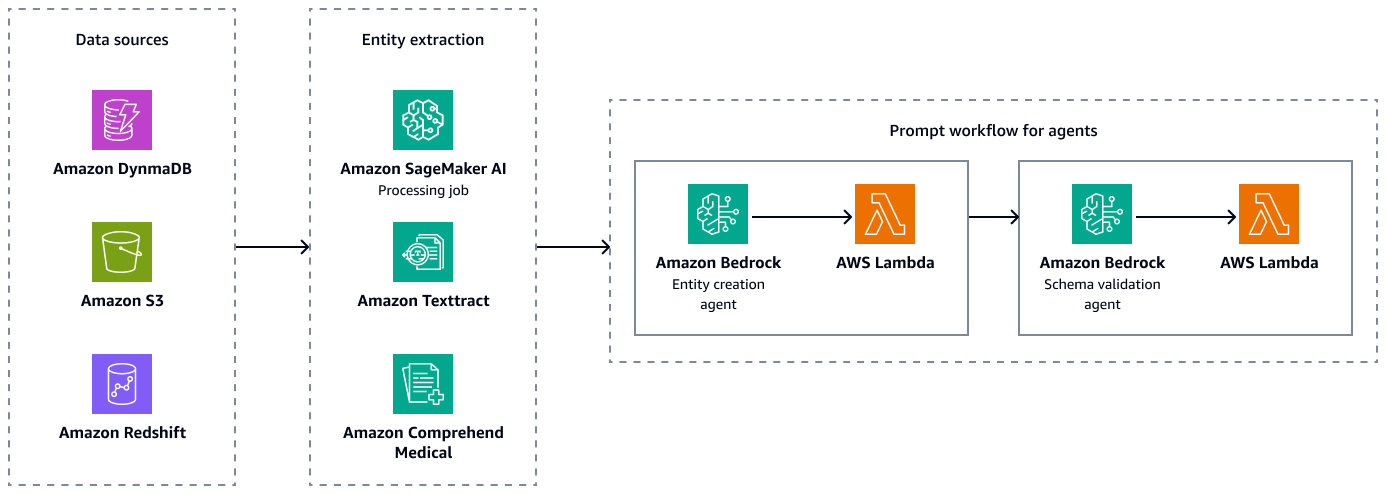
提取和验证实体、关系和属性后,可以将它们链接起来创建 subject-object-predicate三元组。您将这些数据提取到 Amazon Neptune 图表数据库中,如下图所示。图形数据库经过优化,可以存储和查询数据项之间的关系。
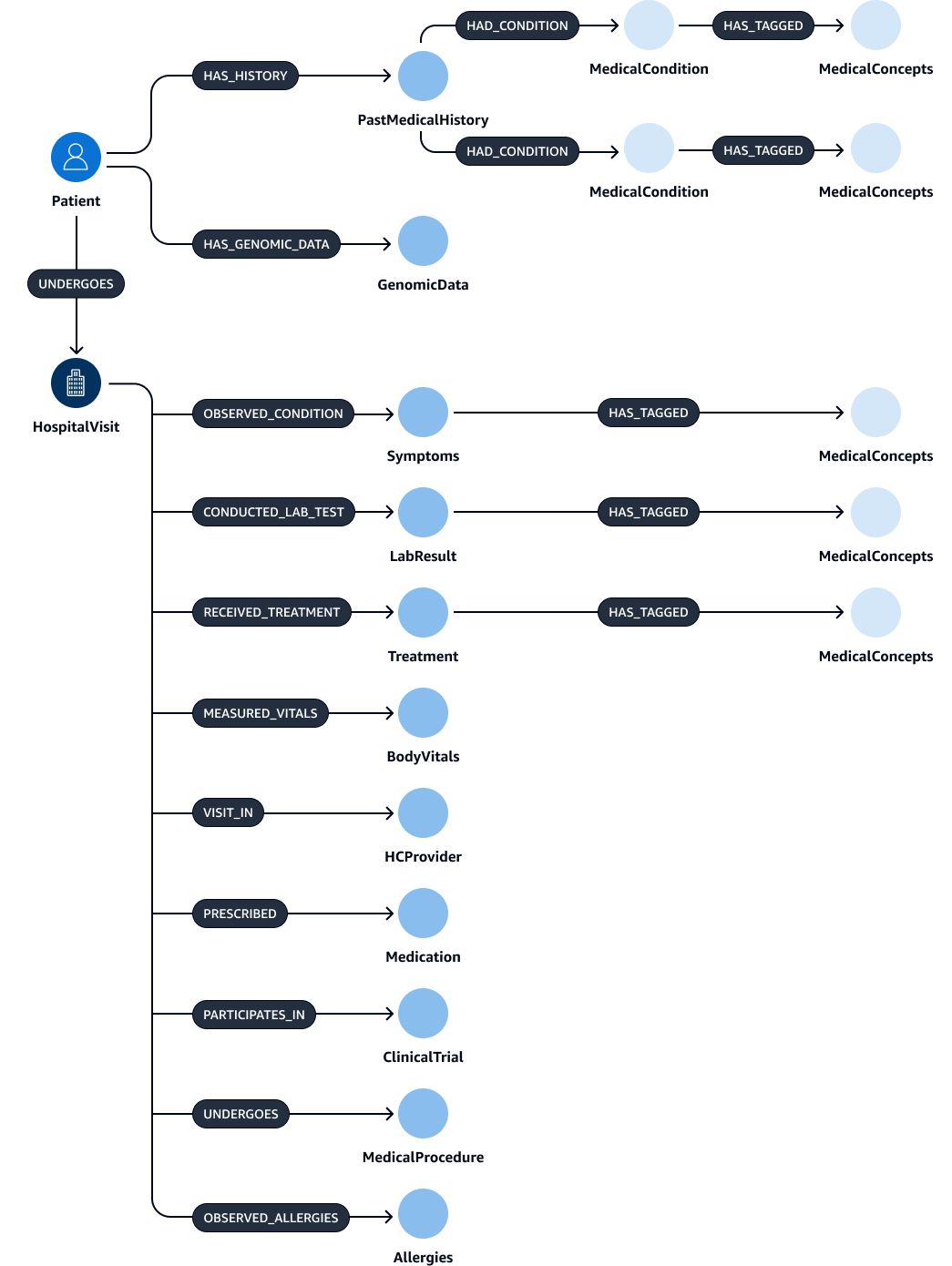
你可以用这些数据创建一个全面的知识图谱。知识图HospitalVisit、PastMedicalHistory、Symptoms、MedicationMedicalProcedures、和Treatment。
下表列出了您可以从出院通知中提取的实体及其属性。
| 实体 | Attributes |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
下表列出了实体可能具有的关系及其对应的属性。例如,该Patient实体可能通过该[UNDERGOES]关系连接到HospitalVisit实体。这种关系的属性是VisitDate。
| 主体实体 | 关系 | 对象实体 | Attributes |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
无 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
无 |
|
|
|
无 |
|
|
|
无 |
|
|
|
无 |
第 3 步:构建上下文检索代理以查询医学知识图谱
构建医学图形数据库后,下一步是构建用于图形交互的代理。这些代理会检索医生或临床医生输入的查询的正确和必需的上下文。配置这些从知识图谱中检索上下文的代理有多种选项:
用于图形交互的 Amazon Bedrock 代理
亚马逊 Bedrock 代理可与亚马逊 Neptune 图形数据库无缝协作。您可以通过 Amazon Bedrock 操作组进行高级互动。操作组通过调用一个运行 Neptune OpenCypher 查询的 AWS Lambda 函数来启动该进程。
要查询知识图谱,您可以使用两种不同的方法:直接执行查询或使用上下文嵌入进行查询。这些方法可以独立应用,也可以组合使用,具体取决于您的具体用例和排名标准。通过结合这两种方法,您可以为法学硕士提供更全面的背景信息,从而改善结果。以下是两种查询执行方法:
-
无需嵌入即可@@ 直接执行 Cypher 查询 — Lambda 函数无需任何基于嵌入的搜索即可直接针对 Neptune 执行查询。以下是这种方法的示例:
MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason = 'Acute Diabetes' AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation -
使用嵌入式搜索直接执行 Cypher 查询 — Lambda 函数使用嵌入式搜索来增强查询结果。这种方法通过合并嵌入来增强查询执行,嵌入是数据的密集向量表示形式。当查询需要语义相似性或超出精确匹配范围的更广泛理解时,嵌入式特别有用。您可以使用预先训练或自定义训练的模型为每种疾病生成嵌入数据。以下是这种方法的示例:
CALL { WITH "Acute Diabetes" AS query_term RETURN search_embedding(query_term) AS similar_reasons } MATCH (p:Patient)-[u:UNDERGOES]->(h:HospitalVisit) WHERE h.Reason IN similar reasons AND date(u.VisitDate) > date('2024-01-01') RETURN p.PatientID, p.Name, p.Age, p.Gender, p.Address, p.ContactInformation在此示例中,该
search_embedding("Acute Diabetes")函数检索语义上接近 “急性糖尿病” 的病症。这有助于查询还能找到患有糖尿病前期或代谢综合征等疾病的患者。
下图显示了亚马逊 Bedrock 代理如何与亚马逊 Neptune 交互以对医学知识图谱执行密码查询。
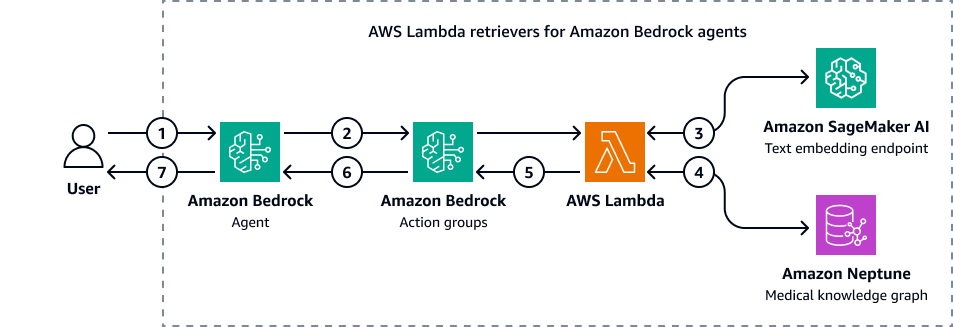
图表显示了以下工作流:
-
用户向 Amazon Bedrock 代理提交问题。
-
Amazon Bedrock 代理将问题和输入筛选变量传递给 Amazon Bedrock 行动小组。这些操作组包含一个与亚马逊 A SageMaker I 文本嵌入端点和亚马逊 Neptune 医学知识图谱交互的 AWS Lambda 函数。
-
Lambda 函数与 SageMaker AI 文本嵌入端点集成,可在 OpenCypher 查询中执行语义搜索。它使用底层语言将自然语言查询转换为 OpenCypher 查询 LangChain 代理人。
-
Lambda 函数在海王星医学知识图中查询正确的数据集,并接收来自海王星医学知识图的输出。
-
Lambda 函数将 Neptune 的结果返回给亚马逊 Bedrock 行动小组。
-
亚马逊 Bedrock 行动小组将检索到的上下文发送给亚马逊 Bedrock 代理。
-
Amazon Bedrock 代理使用原始用户查询和从知识图谱中检索到的上下文生成响应。
LangChain 用于图形交互的代理
你可以整合 LangChain 使用 Neptune 可以实现基于图形的查询和检索。这种方法可以通过使用 Neptune 中的图形数据库功能来增强 AI 驱动的工作流程。习俗 LangChain 寻回犬充当中介。Amazon Bedrock 中的基础模型可以通过使用直接的 Cypher 查询和更复杂的图形算法与 Neptune 进行交互。
你可以使用自定义的检索器来细化 LangChain 代理与 Neptune 图算法进行交互。例如,您可以使用少量提示,它可以帮助您根据特定的模式或示例定制基础模型的响应。您还可以应用 LLM 识别的过滤器来完善上下文并提高响应的精度。在与复杂的图形数据交互时,这可以提高整个检索过程的效率和准确性。
下图显示了如何自定义 LangChain 代理精心策划了亚马逊 Bedrock 基础模型和亚马逊 Neptune 医学知识图谱之间的互动。
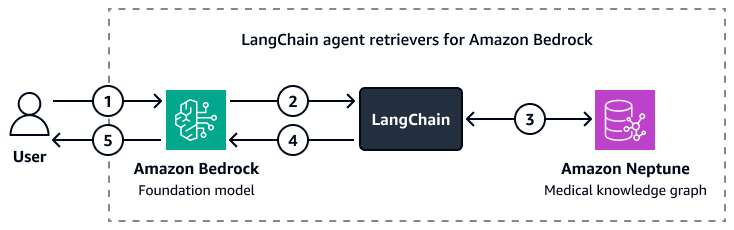
图表显示了以下工作流:
-
用户向 Amazon Bedrock 提交问题和 LangChain 代理人。
-
Amazon Bedrock 基础模型使用 Neptune 架构,该架构由 LangChain 代理,为用户的问题生成查询。
-
这些区域有:LangChain 代理对照 Amazon Neptune 医学知识图谱运行查询。
-
这些区域有:LangChain 代理将检索到的上下文发送到 Amazon Bedrock 基础模型。
-
Amazon Bedrock 基础模型使用检索到的上下文来生成用户问题的答案。
第 4 步:创建实时描述性数据的知识库
接下来,您将创建一个包含实时、描述性的医患互动笔记、诊断图像评估和实验室分析报告的知识库。该知识库是一个矢量数据库
使用 OpenSearch 服务医疗知识库
Amazon S OpenSearch ervic e 可以管理大量的高维医疗数据。它是一项托管服务,可促进高性能搜索和实时分析。它非常适合作为 RAG 应用程序的矢量数据库。 OpenSearch 服务充当后端工具,用于管理大量非结构化或半结构化数据,例如医疗记录、研究文章和临床记录。其高级语义搜索功能可帮助您检索与上下文相关的信息。这使得它在临床决策支持系统、患者查询解决工具和医疗保健知识管理系统等应用中特别有用。例如,临床医生可以快速找到与特定症状或治疗方案相匹配的相关患者数据或研究。这可以帮助临床医生根据最 up-to-date相关的信息做出决策。
OpenSearch 服务可以扩展和处理实时数据索引和查询。这使其成为动态医疗保健环境的理想之选,在这种环境中,及时访问准确的信息至关重要。此外,它还具有多模式搜索功能,最适合需要多个输入的搜索,例如医学图像和医生笔记。在为医疗保健应用程序实施 OpenSearch 服务时,必须定义精确的字段和映射,以优化数据索引和检索。字段表示各个数据,例如患者记录、病史和诊断代码。映射定义了如何存储这些字段(以嵌入形式或原始形式)和查询这些字段。对于医疗保健应用程序,必须建立适应各种数据类型的映射,包括结构化数据(例如数值测试结果)、半结构化数据(例如患者记录)和非结构化数据(例如医学图像)
在 S OpenSearch ervice 中,您可以通过精心策划的提示执行全文神经搜索
创建 RAG 架构
您可以部署自定义 RAG 解决方案,该解决方案使用 Amazon Bedrock 代理在服务中 OpenSearch 查询医学知识库。为此,您需要创建一个可以与 OpenSearch 服务进行交互和查询的 AWS Lambda 函数。Lambda 函数通过访问 A SageMaker I 文本嵌入端点来嵌入用户的输入问题。Amazon Bedrock 代理会将其他查询参数作为输入传递给 Lambda 函数。该函数在 Service 中查询 S OpenSearch ervice 中的医学知识库,返回相关的医学内容。设置 Lambda 函数后,将其作为操作组添加到 Amazon Bedrock 代理中。Amazon Bedrock 代理接收用户的输入,识别必要的变量,将变量和问题传递给 Lambda 函数,然后启动该函数。该函数返回一个上下文,该上下文可帮助基础模型为用户的问题提供更准确的答案。
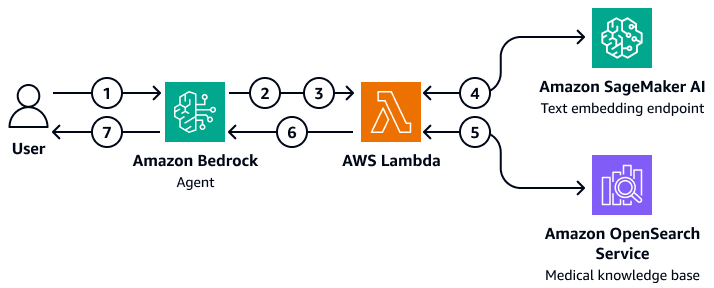
图表显示了以下工作流:
-
用户向 Amazon Bedrock 代理提交了一个问题。
-
Amazon Bedrock 代理选择要启动的操作组。
-
Amazon Bedrock 代理启动一个 AWS Lambda 函数并将参数传递给该函数。
-
Lambda 函数启动 Amazon A SageMaker I 文本嵌入模型以嵌入用户问题。
-
Lambda 函数将嵌入的文本以及其他参数和筛选条件传递给亚马逊 OpenSearch 服务。亚马逊 OpenSearch 服务查询医学知识库并将结果返回到 Lambda 函数。
-
Lambda 函数将结果传回给亚马逊 Bedrock 代理。
-
Amazon Bedrock 代理中的基础模型根据结果生成响应,并将响应返回给用户。
对于涉及更复杂筛选的情况,您可以使用自定义 LangChain 寻回犬。通过设置直接加载到的 OpenSearch 服务矢量搜索客户端来创建此检索器 LangChain。 这种架构允许您传递更多变量来创建过滤器参数。设置好寻回犬后,使用 Amazon Bedrock 模型和寻回器设置检索问答链。该链通过将用户输入和潜在的过滤器传递给检索器来协调模型和检索器之间的交互。检索器返回相关的上下文,帮助基础模型回答用户的问题。
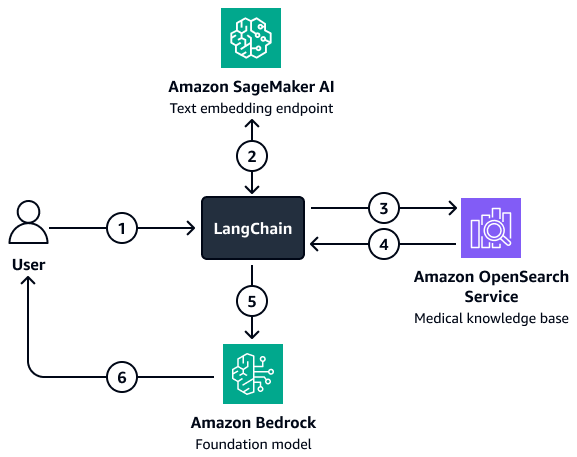
图表显示了以下工作流:
-
用户向 LangChain 寻回犬代理。
-
这些区域有:LangChain 检索器代理将问题发送到 Amazon A SageMaker I 文本嵌入端点以嵌入问题。
-
这些区域有:LangChain 检索器代理将嵌入的文本传递给 Amazon OpenSearch 服务。
-
Amazon OpenSearch 服务会将检索到的文档返回到 LangChain 寻回犬代理。
-
这些区域有:LangChain 检索器代理将用户问题和检索到的上下文传递给 Amazon Bedrock 基础模型。
-
基础模型生成响应并将其发送给用户。
第 5 步: LLMs 用于回答医疗问题
前面的步骤可帮助您构建医疗智能应用程序,该应用程序可以获取患者的病历并汇总相关药物和潜在诊断。现在,你构建生成层。该层使用 Amazon Bedrock 中的 LLM(例如 Llama 3)的生成功能来增强应用程序的输出。
当临床医生输入查询时,应用程序的上下文检索层会从知识图中执行检索过程,并返回与患者病史、人口统计、症状、诊断和结果相关的热门记录。它还从矢量数据库中检索实时、描述性的医患互动笔记、诊断图像评估见解、实验室分析报告摘要以及来自大量医学研究和学术书籍的见解。然后,这些检索率最高的结果、临床医生的查询和提示(根据查询的性质量身定制答案)将传递给 Amazon Bedrock 中的基础模型。这是响应生成层。LLM 使用检索到的上下文生成对临床医生查询的响应。下图显示了此解决方案中各步骤 end-to-end的工作流程。
您可以在 Amazon Bedrock 中使用预先训练的基础模型(例如 Llama 3)来处理医疗智能应用程序必须处理的一系列用例。对于给定任务,最有效的法学硕士学位因用例而异。例如,预先训练的模型可能足以总结患者与医生的对话,搜索药物和患者病史,并从内部医疗数据集和科学知识中检索见解。但是,对于其他复杂的用例,例如实时实验室评估、医疗程序建议和患者预后预测,可能需要进行微调的法学硕士。您可以通过在医学领域数据集上训练法学硕士来对其进行微调。特定或复杂的医疗保健和生命科学要求推动了这些微调模型的开发。
有关微调法学硕士学位或选择已接受过医学领域数据培训的现有法学硕士学位的更多信息,请参阅在医疗保健和生命科学用例中使用大型语言模型。
与 Well-Architect AWS ed 框架保持一致
该解决方案与 Well-Ar AWS chitected Framework 的所有六大支柱保持一致,如下所示
-
卓越运营 — 该架构已分离,可实现高效的监控和更新。Amazon Bedrock 代理并 AWS Lambda 帮助您快速部署和回滚工具。
-
安全 — 此解决方案旨在遵守医疗保健法规,例如 HIPAA。您还可以实施加密、精细访问控制和 Amazon Bedrock 护栏,以帮助保护患者数据。
-
可靠性 — AWS 托管服务,例如亚马逊 OpenSearch 服务和 Amazon Bedrock,为持续的模型交互提供了基础设施。
-
性能效率 — RAG 解决方案使用优化的语义搜索和 Cypher 查询快速检索相关数据,而代理路由器则为用户查询确定最佳路由。
-
成本优化 — Amazon Bedrock 和 RAG 架构中的 pay-per-token模型降低了推理和预训练成本。
-
可持续性-使用无服务器基础设施和 pay-per-token计算可以最大限度地减少资源使用并增强可持续性。
