本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在中使用联接提示 Spark SQL
With Spark 3.0,你可以指定你想要的联接算法类型 Spark 在运行时使用。联接策略提示、BROADCAST、MERGESHUFFLE_HASH、和SHUFFLE_REPLICATE_NL、指示 Spark 在将每个指定关系与另一个关系连接时,对它们使用提示策略。本节详细讨论联接策略提示。
广播
在 Bro adcast Hash 联接中,其中一个数据集比另一个数据集小得多。由于内存中可以容纳较小的数据集,因此会将其广播给集群中的所有执行者。广播数据后,将执行标准的哈希联接。广播哈希加入分为两个步骤:
-
广播-将较小的数据集广播给集群内的所有执行者。
-
哈希联接 — 较小的数据集在所有执行器上进行哈希处理,然后与较大的数据集联接。
没有 O sort R merge 操作。将大型事实表与用于执行星型架构联接的较小维度表连接时,Broadcast Hash 是最快的联接算法。以下示例演示广播哈希联接的工作原理。无论属性中指定的大小限制如何,都会广播带有提示的联接面。spark.sql.autoBroadcastJoinThreshold如果联接的两边都有广播提示,则会广播大小较小的那个(基于统计数据)。该spark.sql.autoBroadcastJoinThreshold属性的默认值为 10 MB。这将配置在执行联接时广播到所有工作节点的表的最大大小(以字节为单位)。
以下示例提供了查询、物理EXPLAIN计划和查询运行所花费的时间。如果您使用BROADCASTJOIN提示强制广播联接,则查询所需的处理时间会更短,如第二个示例EXPLAIN计划所示。
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
当两个数据集都很大且无法容纳内存时,首选 Shuffle Sort Merge 联接。顾名思义,此联接涉及以下三个阶段:
-
Shuffle 阶段-联接查询中的两个数据集都被洗牌。
-
排序阶段-记录按两边的联接键排序。
-
合并阶段-根据联接键迭代连接条件的两边。
下图显示了随机排序合并联接的有向无环图 (DAG) 可视化。这两个表都是在前两个阶段读取的。在下一阶段(第 17 阶段)中,对它们进行洗牌、排序,然后在最后合并在一起。
注意:此图像中的某些阶段显示为已跳过,因为这些步骤是在之前的阶段中完成的。这些数据已被缓存或保存,以便在这些阶段使用。 |
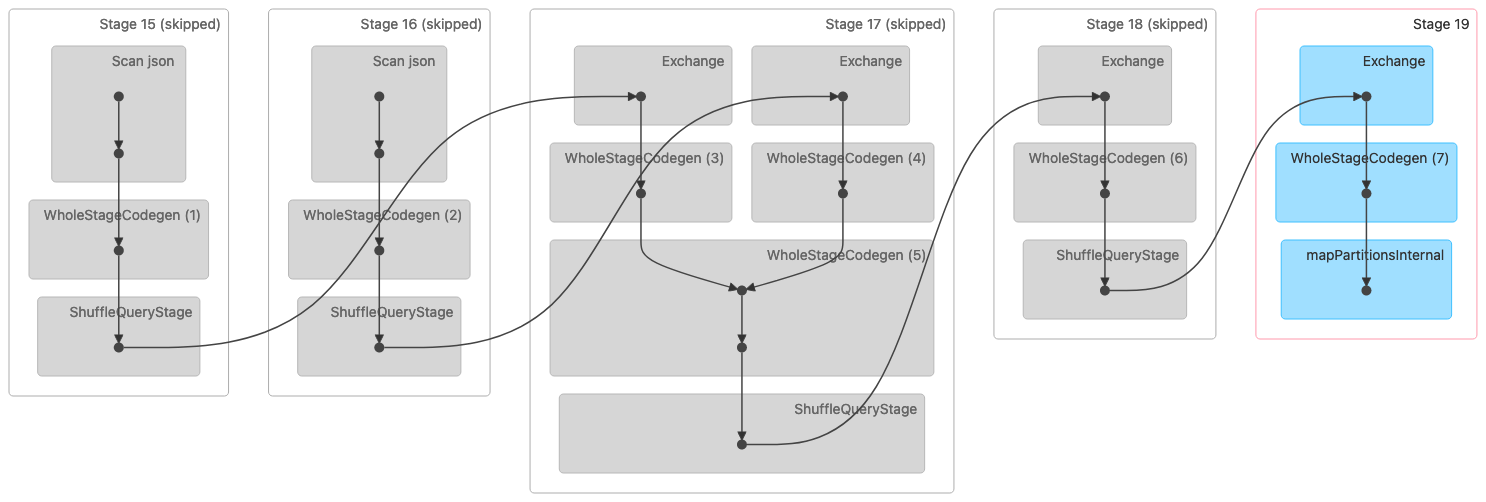
以下是表示排序合并联接的物理计划。
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFF_HASH
顾名思义,Shuffle Hash 连接的工作原理是对两个数据集进行洗牌。来自两边的相同密钥最终会出现在同一个分区或任务中。对数据进行洗牌后,将两个数据集中最小的数据集哈希到存储桶中,然后在分区内执行哈希联接。Shuffle Hash 联接不同于广播哈希联接,因为不会广播整个数据集。Shuffle Hash 连接分为两个阶段:
-
洗牌阶段-两个数据集都被洗牌。
-
哈希联接阶段 — 对数据中较小的一面进行哈希处理、分桶,然后在所有分区中与较大的一侧进行哈希连接。
分区内的 Shuffle Hash 联接不需要排序。下图显示了 Shuffle Hash 联接的各个阶段。首先读取数据,然后对其进行洗牌,然后创建哈希值并将其用于联接。
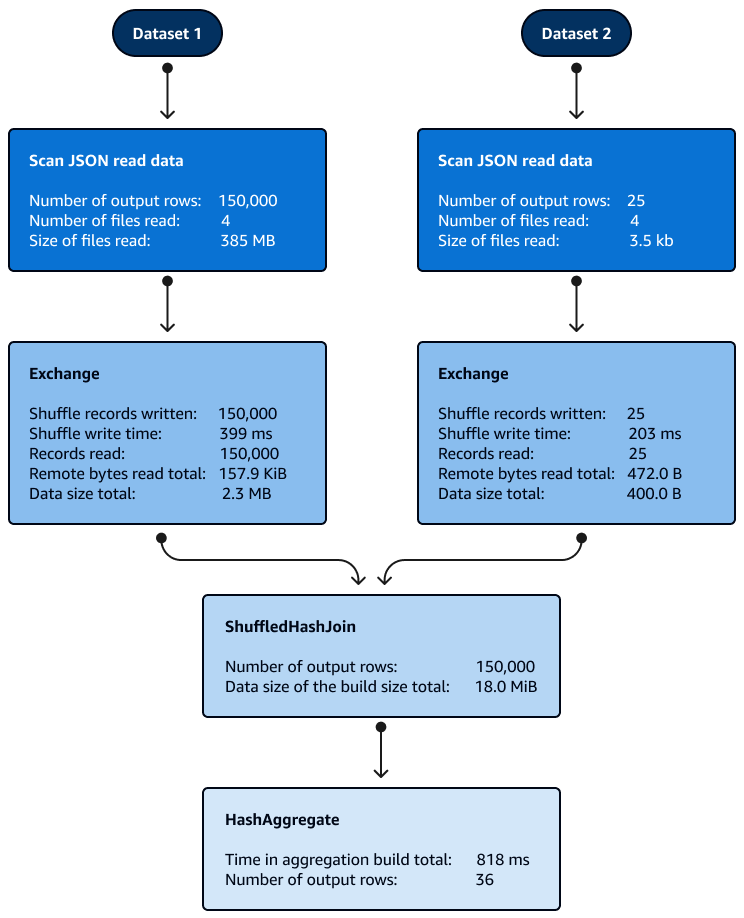
默认情况下,当无法使用 Broadcast Hash 联接时,优化器会选择 Shuffle Hash 联接。根据广播哈希联接阈值大小 (spark.sql.autoBroadcastJoinThreshold) 和所选的洗牌分区数 (spark.sql.shuffle.partitions),当逻辑 SQL 的单个分区足够小,足以构建本地哈希表时,它会使用 Shuffle Hash 联接。
SHUFFLE_REPLICATE_NL
Ne Shuffle-and-Replicate sted Loop 联接(也称为笛卡尔积分连接)的工作原理与广播哈希联接非常相似,只是数据集不被广播。
在这种联接算法中,shuffle 不是指真正的随机播放,因为具有相同键的记录不会发送到同一个分区。取而代之的是,两个数据集的整个分区都通过网络进行复制。当数据集中的分区可用时,将执行嵌套循环联接。如果每个分区中第一个数据集中有X记录Y数,第二个数据集中有记录数,则第二个数据集中的每条记录都将与第一个数据集中的每条记录联接。在每个分区中,这种X × Y情况以循环时间继续。
