本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
现代健康数据策略的实施示例
AWS 提供了参考架构,医疗保健组织可以使用这些架构来理解和构建支持敏捷数据方法的数据平台。以下参考架构说明了用于医疗保健的数据网格架构
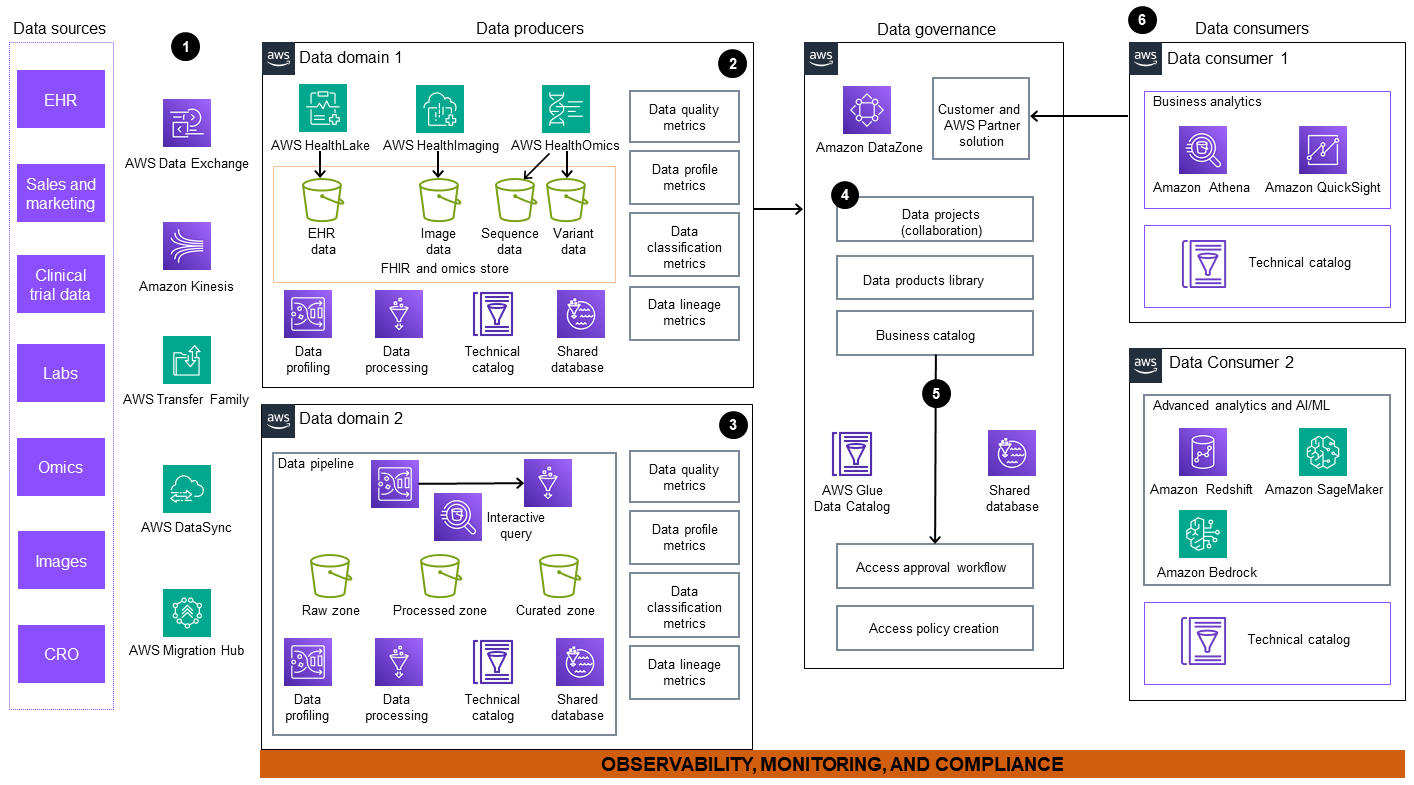
架构图包括以下组件:
-
数据是从外部和内部数据源提取的。这些来源包括但不限于电子健康记录 (EHR) 系统、实验室、测序设施和成像中心。 AWS 提供了一系列服务 AWS Data Exchange
,例如 Amazon Kinesis 、AWS Transfer Family 、、AWS DataSyncAWS Migration HubAWS HealthLake 、和 AWS Glue (ETL)。您可以使用这些服务来帮助迁移内部数据集并订阅内部和外部数据集。 -
Data domain 1 包含一个全面的工作流程,用于处理面向患者的多模式数据,包括临床、组学和成像数据。EHR 临床数据被摄取并存储在 HealthLake 数据存储中,这是一种专门为临床数据构建的托管服务。 AWS HealthOmics
是一项专门为组学数据构建的服务,用于处理序列和变体存储以及工作流程。影像数据被摄取并存储在中。AWS HealthImaging 然后,这些数据被转换为消费就绪型产品,并发布在企业数据市场中,以供广泛访问和使用。 -
在 data domain 2 中,Amazon Kinesis AWS Glue,然后将原始数据 AWS Data Exchange 摄取到数据管道中。数据来源可能包括公共登记处、远程患者监测和企业资源规划 (ERP) 计划。该管道将原始数据加载到亚马逊简单存储服务 (Amazon S3)
存储桶中。这些数据经过清理、整理、转换和存储,以便作为数据产品发布。Amazon A thena 提供了一个交互式查询引擎,数据生产者可以使用该引擎使用 SQL 转换数据。 AWS Glue DataBrew 提供可视化数据转换、标准化和分析功能。 -
Amazon DataZone
负责将元数据、协作数据项目和数据产品库发布到中央业务目录。 -
统一的数据分析门户通过联合治理提供数据产品视图,从而实现围绕数据的协作。Amazon DataZone 支持由 AWS Glue Data Catalog 支持的自助式工作流程 AWS Lake Formation,因此用户可以共享、搜索、发现数据和请求使用许可。
-
数据使用者可以访问数据、创建下游视图,并使用专门构建的工具,例如亚马逊 Athena、Amazon、Amazon QuickSight Redshift 、
Amazon A SageMaker I 和 A mazon Bed rock 来执行以下操作: -
运营分析
-
临床信息学
-
研究
-
患者和临床参与
数据消费者还可以使用生成式人工智能开发创新应用程序,他们可以将数据产品发布到业务目录中。
-
有关数据网格架构的更多信息,请参阅什么是数据网格?
生成式人工智能
医疗保健组织正在将生成式人工智能用于各种应用,从自动解释医疗图像到根据图像和文本数据生成诊断建议和治疗计划。生成式人工智能的采用正在加速创新并提高整个护理过程的效率。对生成式人工智能的新关注迫使医疗保健将其数据重点扩展到包括更多形式的非结构化数据,从而扩大了适合人工智能的用例的数量和种类。一般而言,组织可以根据其用例从四种模式中进行选择,以实现生成式 AI 解决方案:
-
即时工程 — 在即时工程中,用户提供相关数据作为上下文,引导生成式 AI 模型创建他们想要的内容。采用现代健康数据策略的组织可以确保相关数据易于发现、共享和使用。
-
检索增强生成 (RAG) — RAG 模式建立在及时工程的基础上。程序不是用户提供相关数据,而是拦截用户的问题或输入。该程序在数据存储库中搜索以检索与问题或输入相关的内容。该程序将其找到的数据提供给生成式 AI 模型以生成内容。现代医疗保健数据策略支持企业数据的整理和索引。然后可以搜索这些数据并将其用作提示或问题的上下文,从而帮助大型语言模型 (LLM) 生成响应。
您的组织可以使用以下两种模式将生成式 AI 模型输出集中在生成适合其数据上下文的内容上。
-
微调 — 使用这种模式,您的组织可以通过自定义生成式 AI 模型来更进一步。这涉及根据组织特有的少量数据样本对模型进行微调。由于样本量很小,因此这种模式在成本和定制之间取得了平衡。为避免模型输出出现偏差,请使用尽可能多样化且能代表组织数据模式的小样本数据集。现代健康数据策略支持高效访问各种数据以准备样本数据集。
-
构建自己的模型 — 如果您的组织需要使用高度专业化的大量数据生成内容,而前三种模式还不够,则可以构建自己的模型。
现代数据策略通过帮助确保数据具有以下特征,在生成式人工智能解决方案中起着至关重要的作用:
-
支持准确性的高质量数据
-
实时或近乎实时的数据,有助于确保模型输出相关
-
跨各种数据源的多种数据模式,使模型能够访问丰富的数据集以生成内容
下图显示了现代健康数据策略的实现,该策略使用数据网格架构来支持生成式 AI 解决方案。
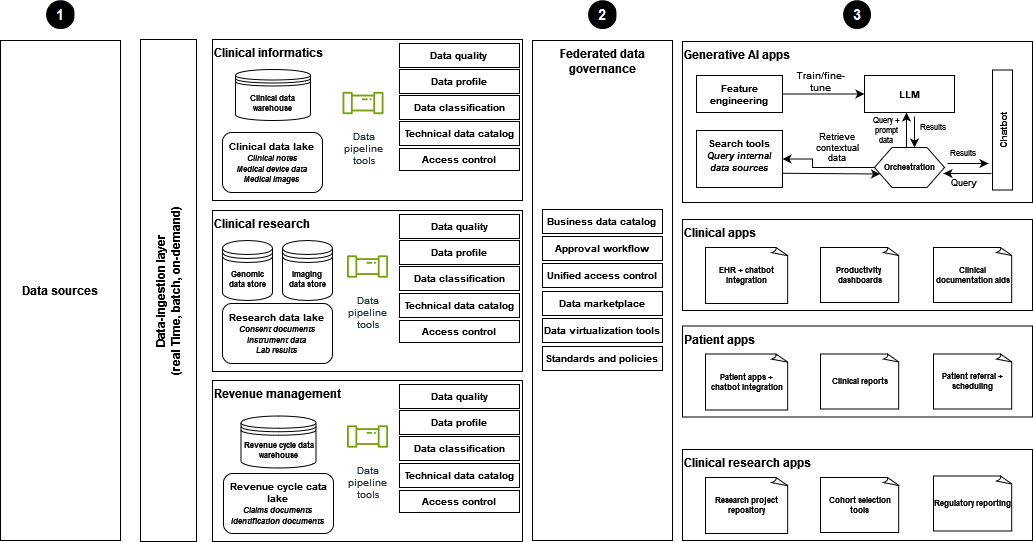
-
数据来自临床信息学、临床研究和收入管理领域的不同数据源,并将数据提供给医疗保健组织。
-
联合数据治理有助于确保对数据共享和统一访问进行严格的访问控制。
-
数据使用者包括以下内容:
-
生成式 AI 应用程序,尤其是那些使用数据进行训练和微调 LLMs的应用程序。这些应用程序使用企业数据进行问答聊天机器人,以提高运营效率以及患者和提供者的体验。
-
临床应用程序配备了诸如集成电子健康纪录的聊天机器人、生产力仪表板和文档辅助工具等工具。
-
以患者为中心的应用程序,用于改善患者体验。这些应用程序具有聊天机器人互动、临床报告以及高效的转诊和日程安排流程等功能。
-
临床研究,包括研究项目存储库和专为队列分析和监管报告而设计的应用程序。
-
借助这种架构,组织中的利益相关者可以专注于整理和管理他们从其他来源收集的数据,同时让组织中的其他成员可以访问自己的数据。他们可以使用联合数据治理层中提供的工具来定义元数据、管理访问批准工作流程以及定义和实施策略。此外,联合数据治理层还提供集中式访问控制。这为整理各种数据源和按指定频率刷新高质量数据资产以保持相关性创造了环境。 AWS 提供了一套全面的功能来满足您的生成式 AI 需求。Amazon Bedrock
