本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
可扩展的 Web 爬网系统的架构 AWS
以下架构图显示了一个网络爬虫系统,该系统旨在以合乎道德的方式从网站提取环境、社会和治理 (ESG) 数据。你用 Python基于爬虫,针对 AWS 基础架构进行了优化。您 AWS Batch 用来编排大规模抓取任务,并使用亚马逊简单存储服务 (Amazon S3) 进行存储。下游应用程序可以从 Amazon S3 存储桶中提取和存储数据。
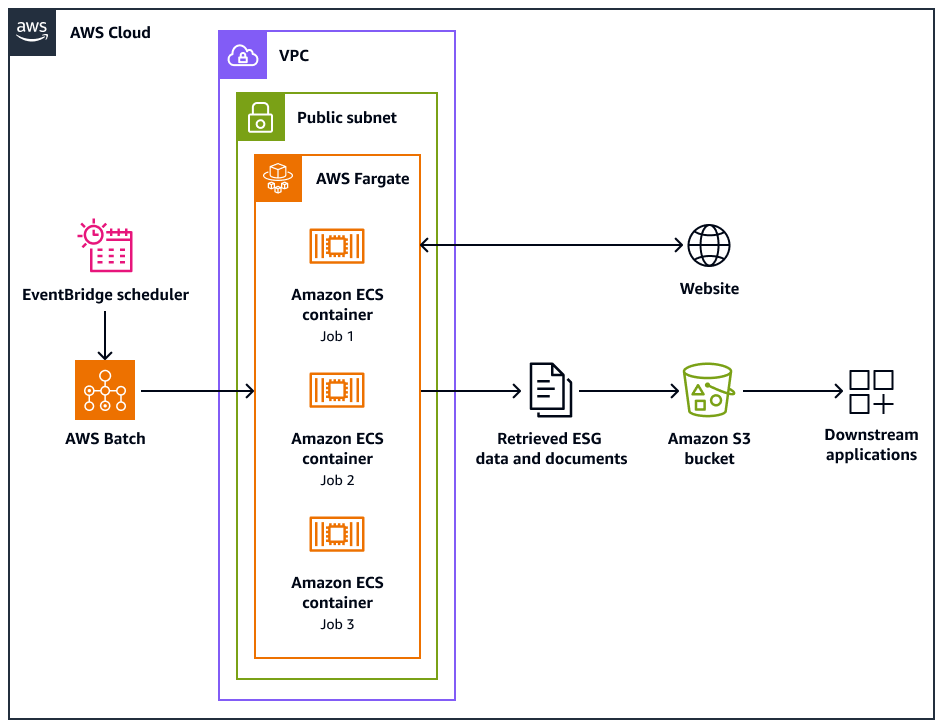
图表显示了以下工作流:
-
Amazon EventBridge Scheduler 按您安排的时间间隔启动抓取过程。
-
AWS Batch 管理网络爬虫作业的执行。 AWS Batch 作业队列保存并协调待处理的抓取作业。
-
网络抓取任务在亚马逊弹性容器服务 (Amazon ECS) 容器中运行。 AWS Fargate这些任务在虚拟私有云 (VPC) 的公有子网中运行。
-
网络爬虫抓取目标网站并检索 ESG 数据和文档,例如 PDF、CSV 或其他文档文件。
-
网络爬虫将检索到的数据和原始文件存储在 Amazon S3 存储桶中。
-
其他系统或应用程序接收或处理 Amazon S3 存储桶中存储的数据和文件。
网络爬虫的设计和操作
有些网站是专门为在台式机或移动设备上运行而设计的。Web Crawler 旨在支持使用桌面用户代理或移动用户代理。这些代理可以帮助您成功地向目标网站发出请求。
网络爬虫初始化后,它会执行以下操作:
-
网络爬虫调用该
setup()方法。此方法获取并解析 robots.txt 文件。注意
您也可以将网络爬虫配置为获取和解析站点地图。
-
网络爬虫会处理 robots.txt 文件。如果在 robots.txt 文件中指定了抓取延迟,则网络爬虫会提取桌面用户代理的抓取延迟。如果未在 robots.txt 文件中指定抓取延迟,则网络爬虫会使用随机延迟。
-
Web Crawler 调用该
crawl()方法,该方法启动搜索过程。如果队列中没 URLs 有,则会添加起始 URL。注意
爬虫会一直持续到达到最大页面数或用完 URLs 可以抓取为止。
-
爬虫会处理. URLs 对于队列中的每个 URL,爬虫都会检查该 URL 是否已被抓取。
-
如果网址尚未被抓取,则抓取器会按如下方式调用该
crawl_url()方法:-
爬虫会检查 robots.txt 文件以确定它是否可以使用桌面用户代理来抓取 URL。
-
如果允许,爬虫会尝试使用桌面用户代理抓取 URL。
-
如果不允许或者桌面用户代理无法抓取,则爬虫会检查 robots.txt 文件以确定它是否可以使用移动用户代理来抓取 URL。
-
如果允许,抓取工具会尝试使用移动用户代理来抓取 URL。
-
-
Crawler 调用该
attempt_crawl()方法,该方法检索和处理内容。抓取工具向 URL 发送带有相应标头的 GET 请求。如果请求失败,Crawler 将使用重试逻辑。 -
如果文件是 HTML 格式,则爬虫会调用该
extract_esg_data()方法。它使用 Beautiful Soup来解析 HTML 内容。它使用关键字匹配来提取环境、社会和治理 (ESG) 数据。 如果文件是 PDF,则爬虫会调用该
save_pdf()方法。爬虫会下载 PDF 文件并将其保存到 Amazon S3 存储桶中。 -
爬虫调用该
extract_news_links()方法。它可以查找并存储指向新闻文章、新闻稿和博客文章的链接。 -
爬虫调用该
extract_pdf_links()方法。它可以识别和存储指向 PDF 文档的链接。 -
爬虫调用该
is_relevant_to_sustainable_finance()方法。它使用预定义的关键字来检查新闻或文章是否与可持续金融有关。 -
每次尝试抓取后,爬虫都会使用该
delay()方法实现延迟。如果在 robots.txt 文件中指定了延迟,则会使用该值。否则,它将使用 1 到 3 秒之间的随机延迟。 -
爬虫调用该
save_esg_data()方法将 ESG 数据保存到 CSV 文件中。CSV 文件保存在亚马逊 S3 存储桶中。 -
Crawler 调用该
save_news_links()方法将新闻链接保存到 CSV 文件,包括相关性信息。CSV 文件保存在亚马逊 S3 存储桶中。 -
Crawler 调用该
save_pdf_links()方法将 PDF 链接保存到 CSV 文件。CSV 文件保存在亚马逊 S3 存储桶中。
批处理和数据处理
抓取过程是以结构化的方式组织和执行的。 AWS Batch 为每家公司分配任务,以便它们分批并行运行。每批都侧重于一家公司的域名和子域名,正如您在数据集中识别的那样。但是,同一批次中的作业会按顺序运行,这样它们就不会因为过多的请求而淹没网站。这有助于应用程序更有效地管理抓取工作负载,并确保捕获每家公司的所有相关数据。
通过将网络爬网组织成公司特定的批次,从而对收集的数据进行容器化。这有助于防止一家公司的数据与其他公司的数据混在一起。
批处理可帮助应用程序高效地从网络收集数据,同时根据目标公司及其各自的网络域保持清晰的结构和信息分离。这种方法有助于确保所收集数据的完整性和可用性,因为它组织得井井有条,并且与相应的公司和域名相关联。
