列式存储
本节介绍列式存储,这是 Amazon Redshift 用来高效存储表格数据的方法。
数据库表的列式存储大大降低了总体磁盘 I/O 要求,所以是优化分析查询性能的一个重要因素。它减少了您需要从磁盘加载的数据量。
以下一系列图示描述列式数据存储如何实现高效以及如何在将数据检索到内存中实现高效。
此第一个图示说明通常如何将数据库表中的记录(按行)存储到磁盘块中。
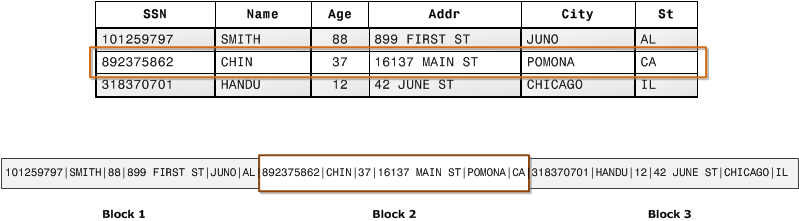
在典型的关系数据库表中,每个行均包含一条记录的字段值。在行式数据库存储中,数据块按顺序存储每个连续列(构成整个行)的值。如果数据块大小小于记录的大小,整个记录的存储可采用多个数据块。如果数据块大小大于记录的大小,整个记录的存储可能采用 1 个以下的数据块,从而导致磁盘空间的使用低效。在在线事务处理 (OLTP) 应用程序中,大多数事务涉及频繁读取和写入整个记录的所有值,通常一次读取和写入一条记录或几条记录。最终,行式存储已针对 OLTP 数据库进行优化。
下一个图示说明,借助列式存储,如何按顺序将每个列的值存储到磁盘块中。
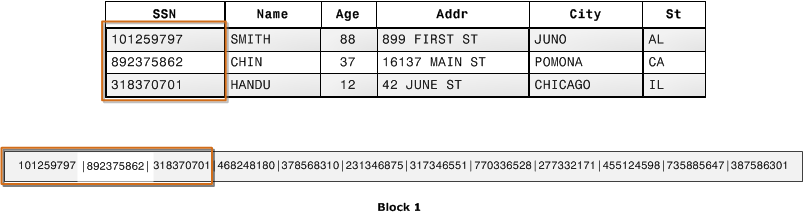
使用列式存储,每个数据块可为多个行存储一个列的值。在记录进入系统后,Amazon Redshift 以透明方式将数据转换为每个列的列式存储。
在此简化示例中,借助列式存储,每个数据块将三倍于记录数的列字段值保留为基于行的存储。这意味着,与行式存储相比,为相同数目的记录读取相同数目的列字段值需要三分之一的 I/O 操作数。实际上,使用具有大量列和大量行的表,存储效率甚至会更高。
增加的一个优势是,由于每个块可保留相同类型的数据,因此数据块数据可使用专为列数据类型选择的压缩方案,进一步减少磁盘空间和输入/输出。有关基于数据类型的压缩编码的更多信息,请参阅压缩编码。
磁盘上用于存储数据的空间节省将继续存在,以便检索数据并将其存储在内存中。由于许多数据库操作一次只需访问或操作一个或几个列,您可通过仅检索查询实际所需列的数据块来节省内存空间。其中,OLTP 事务通常涉及少量记录的一个行中的大多数列或所有列,数据仓库查询通常仅读取大量行的几个列。这意味着,为相同数量的行读取相同数量的列字段值只需要一小部分 I/O 操作。与处理行式块所需的内存相比,它只使用一小部分内存。实际上,通过使用具有大量列和行的表,可大幅提高效率。例如,假定一个表包含 100 个列。使用 5 个列的查询仅需读取表中 5% 的数据。对于大型数据库,可为数十亿或甚至数万亿记录实现此节省。相反,一个行式数据库将读取包含 95 个不需要的列的数据块。
典型的数据库数据块大小介于 2 KB 到 32 KB 之间。Amazon Redshift 使用 1 MB 的块大小,这将提高效率并进一步减少执行任何数据库加载或作为查询运行的一部分的其他操作所需的输入/输出请求数。
