本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
浏览在 Profiler 用户界面中可视化的 SageMaker 配置文件输出数据
本节 SageMaker 介绍了 Profiler 用户界面,并提供了有关如何使用它并从中获得见解的提示。
加载配置文件
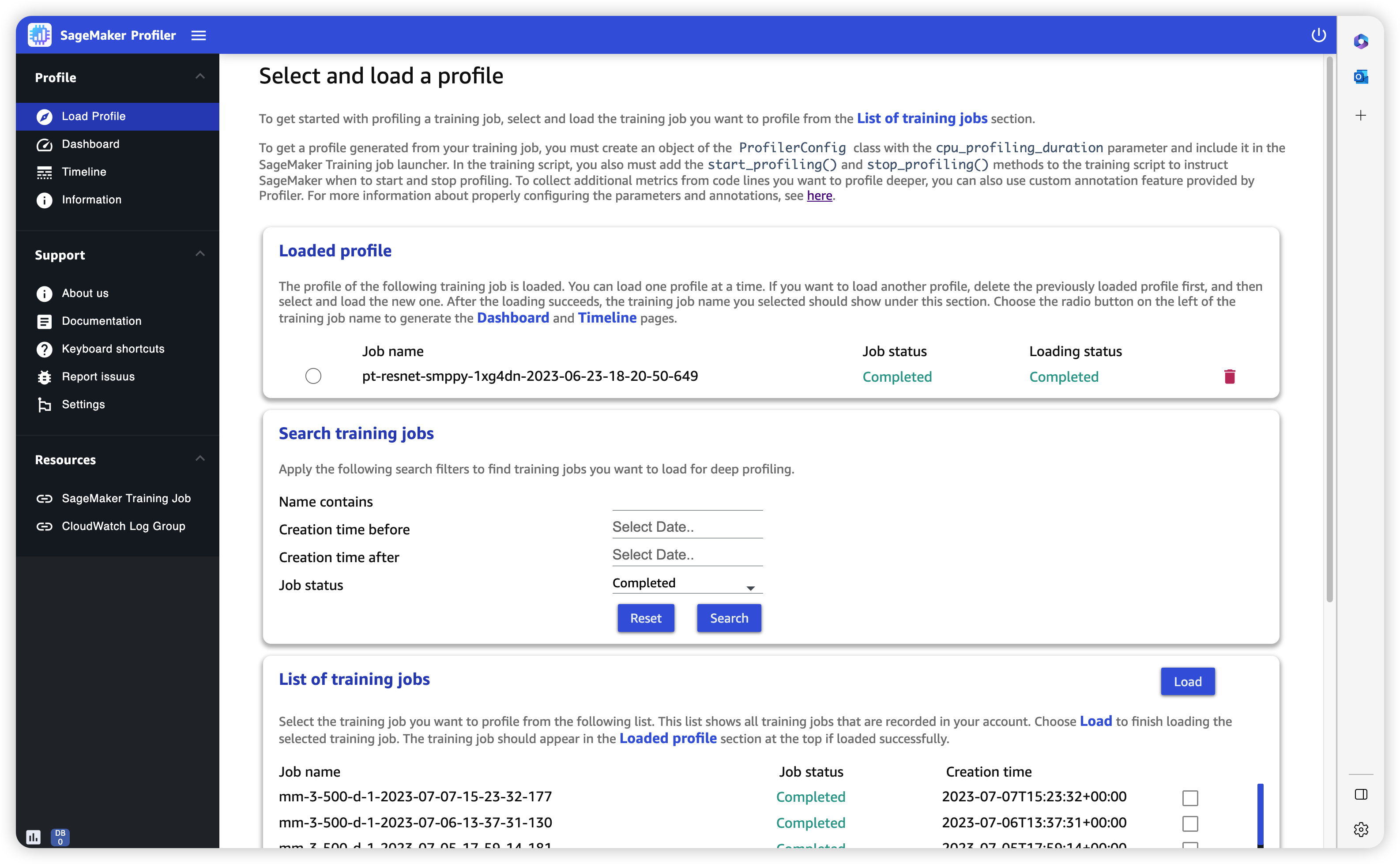
打开 SageMaker Profiler 用户界面时,将打开 “加载配置文件” 页面。要加载和生成控制面板和时间线,请执行以下过程。
加载训练作业的配置文件
-
在训练作业列表部分中,使用复选框选择要为其加载配置文件的训练作业。
-
选择 Load(加载)。作业名称应显示在顶部的已加载配置文件部分中。
-
选择作业名称左侧的单选按钮以生成控制面板和时间线。请注意,当您选择单选按钮时,UI 会自动打开控制面板。另请注意,如果您在作业状态和加载状态似乎仍在进行时生成可视化效果, SageMaker Profiler UI 会生成仪表板图和时间表,直到从正在进行的训练作业或部分加载的配置文件数据中收集的最新配置文件数据。
提示
您一次可以加载和可视化一个配置文件。要加载其他配置文件,必须先卸载之前加载的配置文件。要卸载配置文件,请使用已加载配置文件部分中配置文件右端的垃圾桶图标。
控制面板
加载并选择训练作业后,UI 会打开控制面板页面,此页面默认包含以下面板。
-
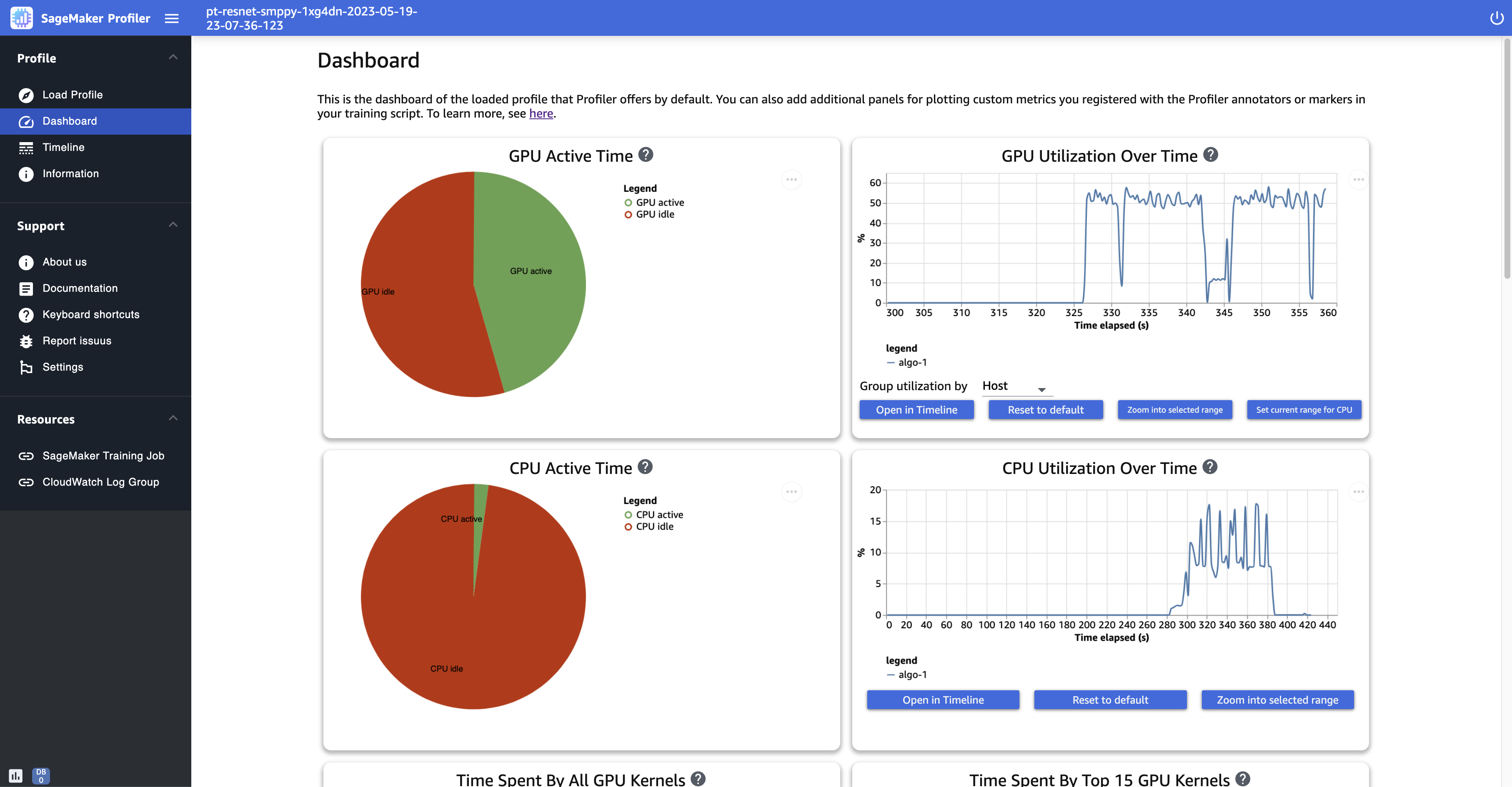
GPU 活动时间 – 此饼图显示了 GPU 活动时间与 GPU 空闲时间的百分比。在整个训练作业 GPUs 中,您可以检查自己的活动程度是否高于闲置状态。GPU 活动时间基于利用率大于 0% 的配置文件数据点,而 GPU 闲置时间是利用率为 0% 的已分析数据点。
-
一段时间内的 GPU 利用率 – 此时间线图显示每个节点一段时间内的平均 GPU 利用率,并将所有节点聚合到一个图表中。您可以检查在特定时间间 GPUs隔内是否存在工作负载不平衡、利用率不足问题、瓶颈或空闲问题。要跟踪单个 GPU 级别的利用率和相关的内核运行,请使用时间线界面。请注意,GPU 活动集合从您在训练脚本中添加探查器 starter 函数
SMProf.start_profiling()的位置开始,并在SMProf.stop_profiling()停止。 -
CPU 活动时间 – 此饼图显示了 CPU 活动时间与 CPU 空闲时间的百分比。在整个训练作业 CPUs 中,您可以检查自己的活动程度是否高于闲置状态。CPU 活动时间基于利用率大于 0% 的配置文件数据点,而 CPU 闲置时间是利用率为 0% 的已分析数据点。
-
一段时间内的 CPU 利用率 – 此时间线图显示每个节点一段时间内的平均 CPU 利用率,并将所有节点聚合到一个图表中。您可以检查在特定的时间间隔内 CPUs是否存在瓶颈或未得到充分利用。要跟踪与各个 GPU 利用率和内核运行情况 CPUs 对齐的利用率,请使用时间线界面。请注意,利用率指标从作业初始化开始。
-
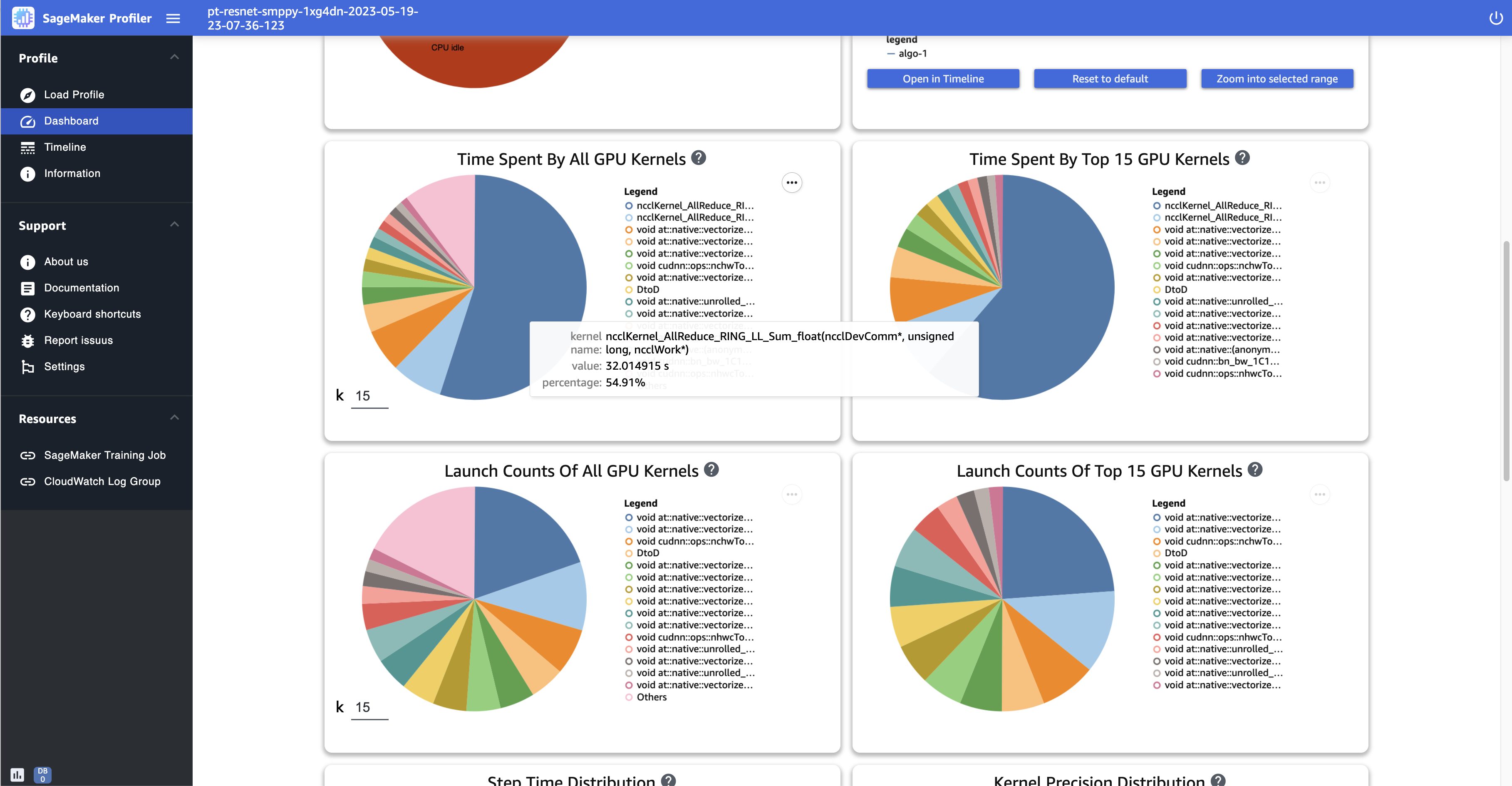
所有 GPU 内核花费的时间 – 此饼图显示了在整个训练作业中运行的所有 GPU 内核。默认情况下,它将前 15 个 GPU 内核显示为单个扇区,并在一个扇区内显示所有其他内核。将鼠标悬停在扇区上方可查看更多详细信息。该值显示 GPU 内核的总运行时间(以秒为单位),而百分比基于配置文件的整个时间。
-
前 15 个 GPU 内核花费的时间 – 此饼图显示了在整个训练作业中运行的所有 GPU 内核。它将前 15 个 GPU 内核显示为单个扇区。将鼠标悬停在扇区上方可查看更多详细信息。该值显示 GPU 内核的总运行时间(以秒为单位),而百分比基于配置文件的整个时间。
-
所有 GPU 内核的启动次数 – 此饼图显示了整个训练作业中每个 GPU 内核的启动次数。它将前 15 个 GPU 内核显示为单个扇区,并在一个扇区内显示所有其他内核。将鼠标悬停在扇区上方可查看更多详细信息。该值显示已启动的 GPU 内核的总数,而百分比基于所有内核的总数。
-
前 15 个 GPU 内核的启动次数 – 此饼图显示了整个训练作业中每个 GPU 内核的启动次数。它显示了前 15 个 GPU 内核。将鼠标悬停在扇区上方可查看更多详细信息。该值显示已启动的 GPU 内核的总数,而百分比基于所有内核的总数。
-
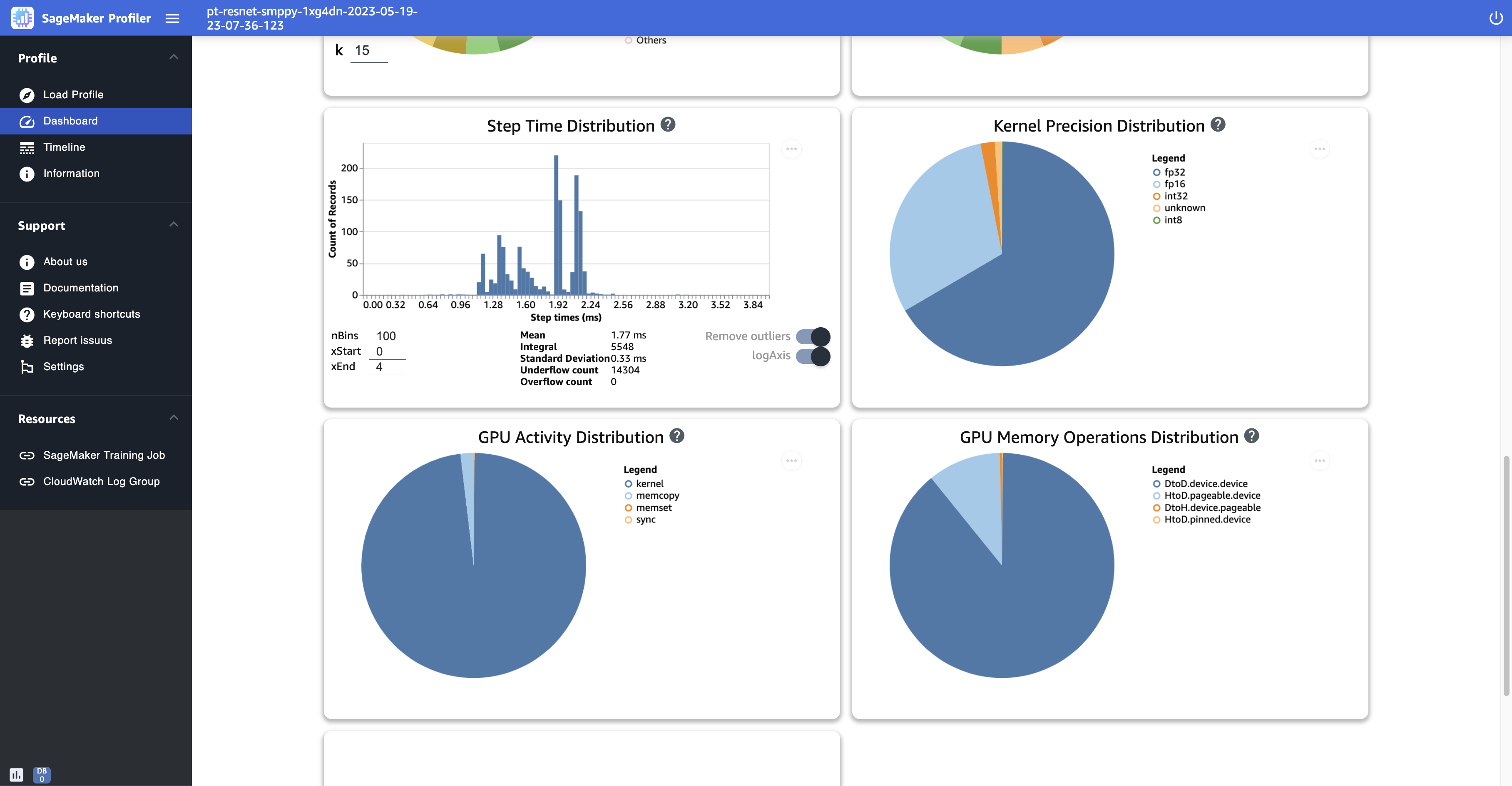
步长分布-此直方图显示步长持续时间的分布。 GPUs仅在训练脚本中添加步长注释器后才会生成此图。
-
内核精度分布-此饼图显示了在不同数据类型(例如 FP32、 FP16 INT32、和 INT8)中运行内核所花费的时间百分比。
-
GPU 活动分布 – 此饼图显示了在 GPU 活动上花费的时间的百分比,例如运行内核、内存(
memcpy和memset)和同步 (sync)。 -
GPU 内存操作分布 – 此饼图显示了在 GPU 内存操作上花费的时间的百分比。这将可视化
memcopy活动,并有助于确定您的训练作业是否在某些内存操作上花费了过多的时间。 -
创建新的直方图 – 为在 第 1 步:使用 P SageMaker rofiler Python 模块调整训练脚本 期间手动注释的自定义指标创建新的直方图。在向新的直方图添加自定义注释时,请选择或键入您在训练脚本中添加的注释的名称。例如,在步骤 1 的演示训练脚本中,
step、Forward、Backward、Optimize和Loss是自定义注释。在创建新的直方图时,这些注释名称将出现在指标选择的下拉菜单中。如果您选择Backward,UI 会将整个分析时间内向后传递所花费时间的直方图添加到控制面板中。这种类型的直方图有助于检查是否有异常值占用了异常长的时间,从而导致瓶颈问题。
以下屏幕截图显示了 GPU 和 CPU 的活动时间比率以及相对于每个计算节点的时间的平均 GPU 和 CPU 利用率。
以下屏幕截图显示了一个饼图示例,用于比较 GPU 内核的启动次数并测量运行它们所花费的时间。在所有 GPU 内核花费的时间面板和所有 GPU 内核的启动次数面板中,您还可以在输入字段中为 k 指定一个整数,调整要在图中显示的图例数。例如,如果您指定 10,则图将分别显示运行次数和启动次数排名前 10 的内核。
以下屏幕截图显示了步长持续时间直方图的示例,以及内核精度分布、GPU 活动分布和 GPU 内存操作分布的饼图。
时间线界面
要详细了解在上调度并在上运行的操作级别和内核级别的 CPUs 计算资源 GPUs,请使用时间轴界面。
您可以使用鼠标、[w, a, s, d] 键或键盘上的四个箭头键在时间线界面中进行放大和缩小以及向左或向右平移。
提示
有关与时间线界面交互的键盘快捷键的更多提示,请在左侧窗格中选择键盘快捷键。
时间线轨迹采用树形结构,为您提供从主机级别到设备级别的信息。例如,如果您运行每个N实例 GPUs 中包含八个实例,则每个实例的时间表结构将如下所示。
-
algo-i node — 这是为预配置实例分配任务的 SageMaker AI 标签。数字 inode 是随机分配的。例如,如果您使用 4 个实例,则此部分将从 algo-1 扩展为 algo- 4。
-
CPU – 在此部分中,您可以查看平均 CPU 利用率和性能计数器。
-
GPUs— 在本节中,您可以查看平均 GPU 利用率、单个 GPU 利用率和内核。
-
总利用率 – 每个实例的平均 GPU 利用率。
-
HOST-0 PID-123 – 为每个进程轨迹分配的唯一名称。首字母缩略词 PID 是进程 ID,其后面附加的数字是在从进程中捕获数据期间记录的进程 ID 号。此部分显示了进程中的以下信息。
-
GPU-inum_gpu 利用率 – 第 inum_gpu 个 GPU 在一段时间内的利用率。
-
GPU-inum_gpu 设备 – 第 inum_gpu 个 GPU 设备上的内核运行。
-
stream icuda_stream – 显示 GPU 设备上的内核运行的 CUDA 流。要了解有关 CUDA 流的更多信息,请参阅 NVIDIA 提供的 CUDA C/C++ 流和并发
上的 PDF 中的幻灯片。
-
-
GPU-inum_gpu 主机 – 内核在第 inum_gpu 个 GPU 主机上启动。
-
-
-
以下几张屏幕截图显示了在ml.p4d.24xlarge实例上运行的训练作业配置文件的时间表,每个实例 GPUs 中都配有 8 个 NVIDIA A100 Tensor Core。
以下是配置文件的缩小视图,其中列明了十几个步骤,包括 step_232 和 step_233 之间的间歇性数据加载器,用于获取下一个数据批处理。
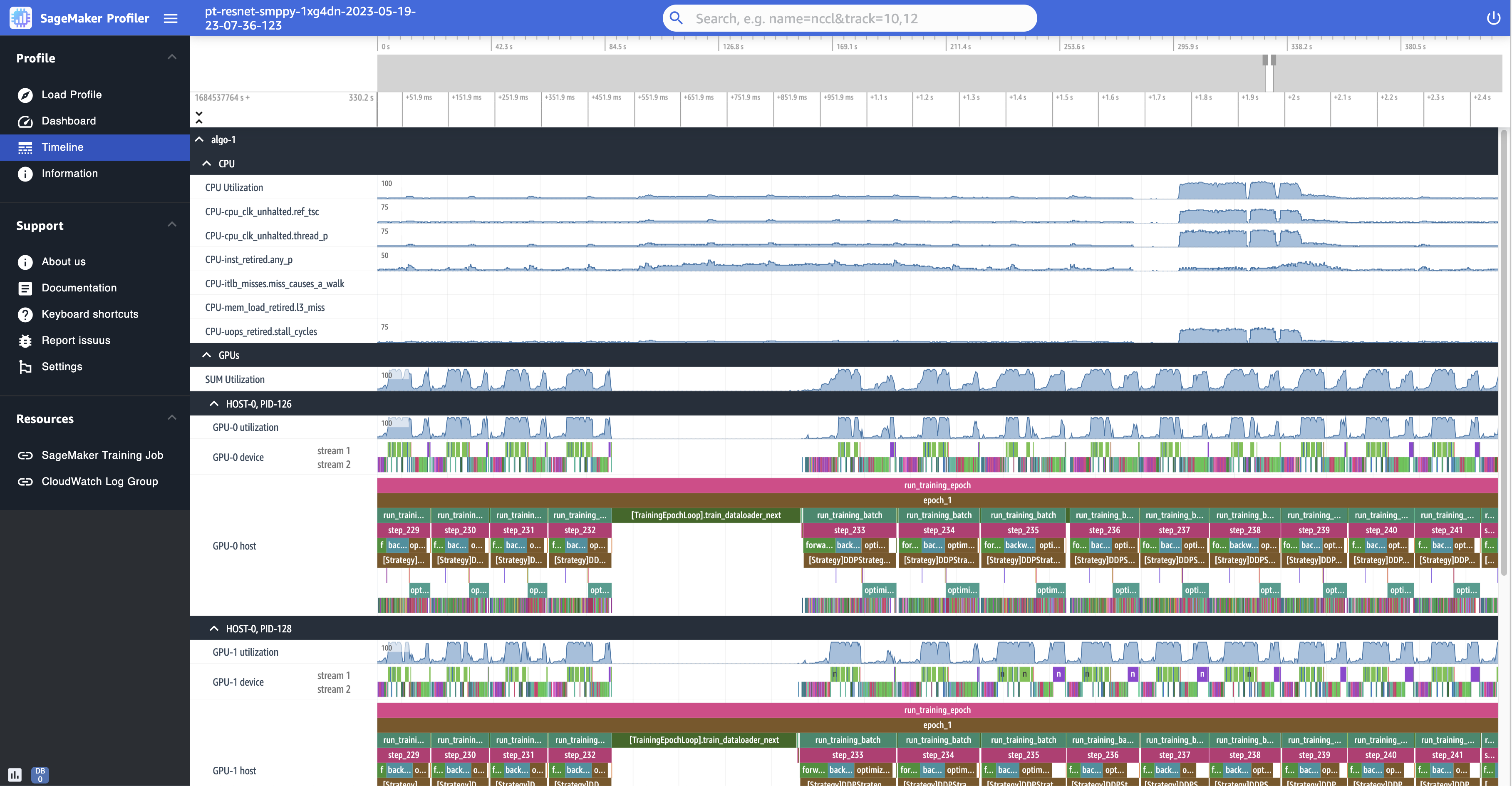
对于每个 CPU,您可以跟踪 CPU 利用率和性能计数器,例如 "clk_unhalted_ref.tsc" 和 "itlb_misses.miss_causes_a_walk",它们表示 CPU 上的指令运行。
对于每个 GPU,您可以查看主机时间线和设备时间线。内核启动位于主机时间线上,内核运行位于设备时间线上。如果您已在 GPU 主机时间线的训练脚本中添加了注释(例如向前、向后和优化),则也将看到这些注释。
在时间轴视图中,您还可以跟踪内核 launch-and-run对。这有助于您了解主机 (CPU) 上计划的内核启动如何在相应的 GPU 设备上运行。
提示
按 f 键可放大选定内核。
以下屏幕截图是上一个屏幕截图中的 step_233 和 step_234 的放大视图。以下屏幕截图中选定的时间线间隔是在 GPU-0 设备上运行的 AllReduce 操作,它是分布式训练中必不可少的通信和同步步骤。在屏幕截图中,请注意,GPU-0 主机中的内核启动会连接到 GPU-0 设备流 1 中的内核运行,用青色箭头表示。
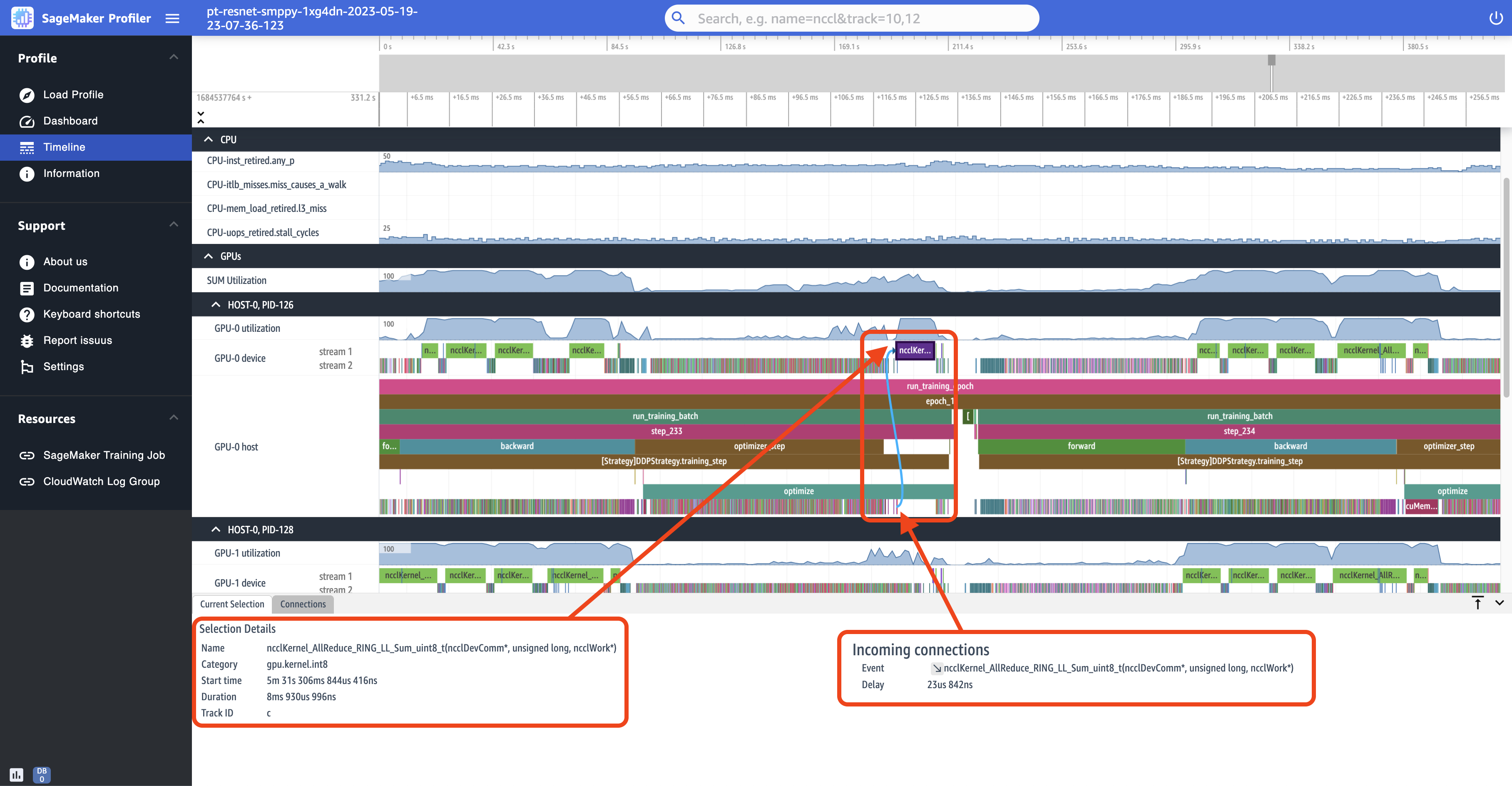
在选择时间线间隔时,UI 的底部窗格中还会显示两个信息选项卡,如上一个屏幕截图中所示。当前选择选项卡显示主机中的选定内核以及已连接的内核启动的详细信息。连接方向始终是从主机 (CPU) 到设备 (GPU),因为总是会从 CPU 调用每个 GPU 内核。连接选项卡显示选定的内核启动和运行对。您可以选择其中任一项来将其移动到时间线视图的中心。
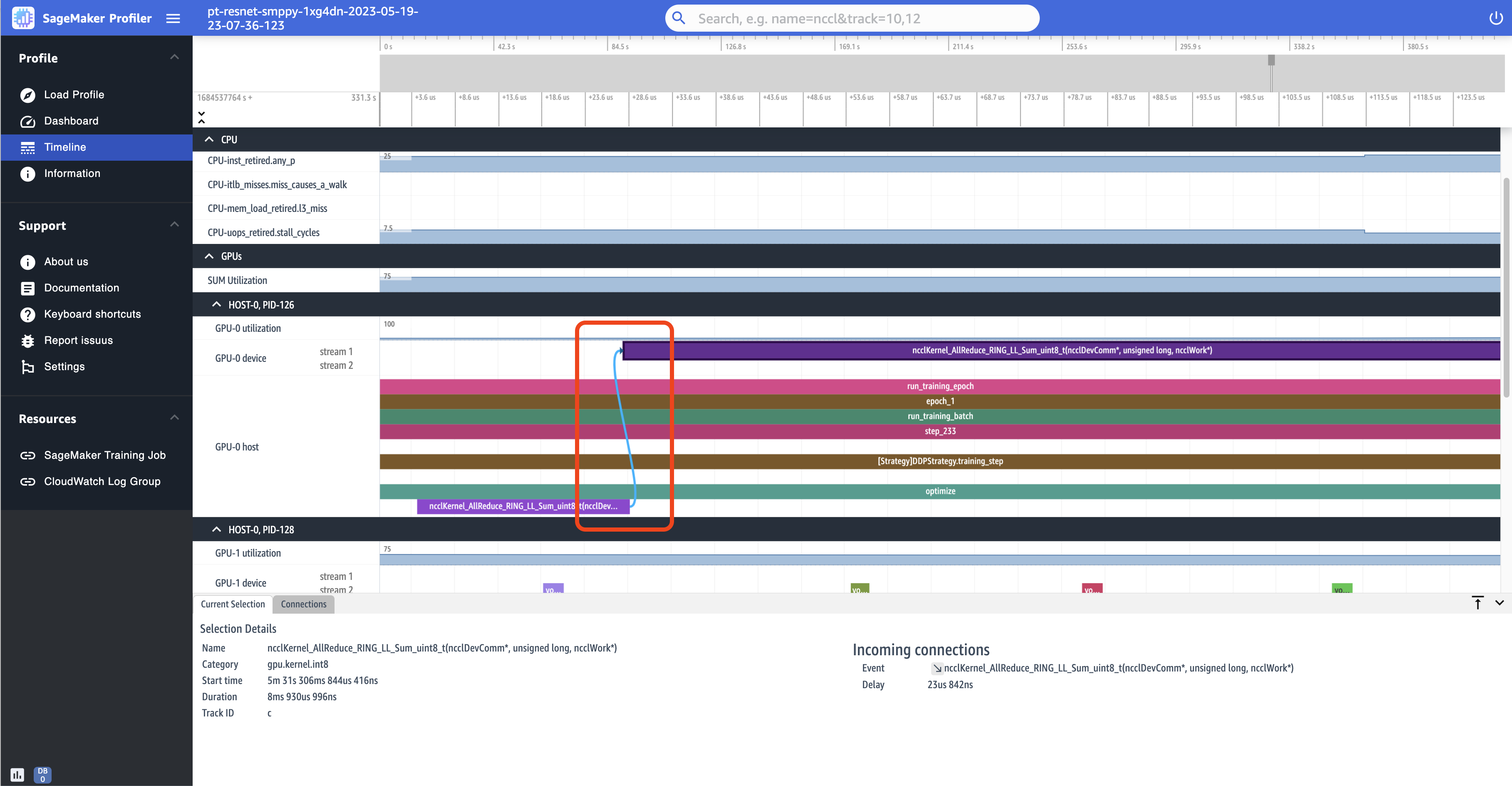
以下屏幕截图进一步放大了 AllReduce 操作启动和运行对。
信息
在 “信息” 中,您可以访问有关已加载训练作业的信息,例如实例类型、为任务预配置的计算资源的 Amazon 资源名称 (ARNs)、节点名称和超参数。
设置
默认情况下, SageMaker AI Profiler 用户界面应用程序实例配置为在空闲时间 2 小时后关闭。在设置中,使用以下设置来调整自动关闭计时器。
-
启用应用程序自动关闭 – 选择并设置为启用,让应用程序在闲置时间超过指定小时数后自动关闭。要禁用自动关闭功能,请选择禁用。
-
自动关闭阈值(以小时为单位)– 如果您为启用应用程序自动关闭选择启用,则可以设置应用程序自动关闭的阈值时间(以小时为单位)。默认情况下,该选项设置为 2。
