本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用自定义语言模型
创建自定义语言模型后,您可以将其包含在转录请求中;有关示例,请参阅以下各节。
您在请求中包含的模型语言必须与您为媒体指定的语言代码相匹配。如果语言不匹配,则您的自定义语言模型不会应用于您的转录,也不会出现任何警告或错误。
在批量转录中使用自定义语言模型
要将自定义语言模型用于批量转录,请查看以下示例:
-
在导航窗格中,选择转录作业,然后选择创建作业(右上角)。这将打开指定作业详细信息页面。
-
在作业设置面板的模型类型下,选中自定义语言模型复选框。
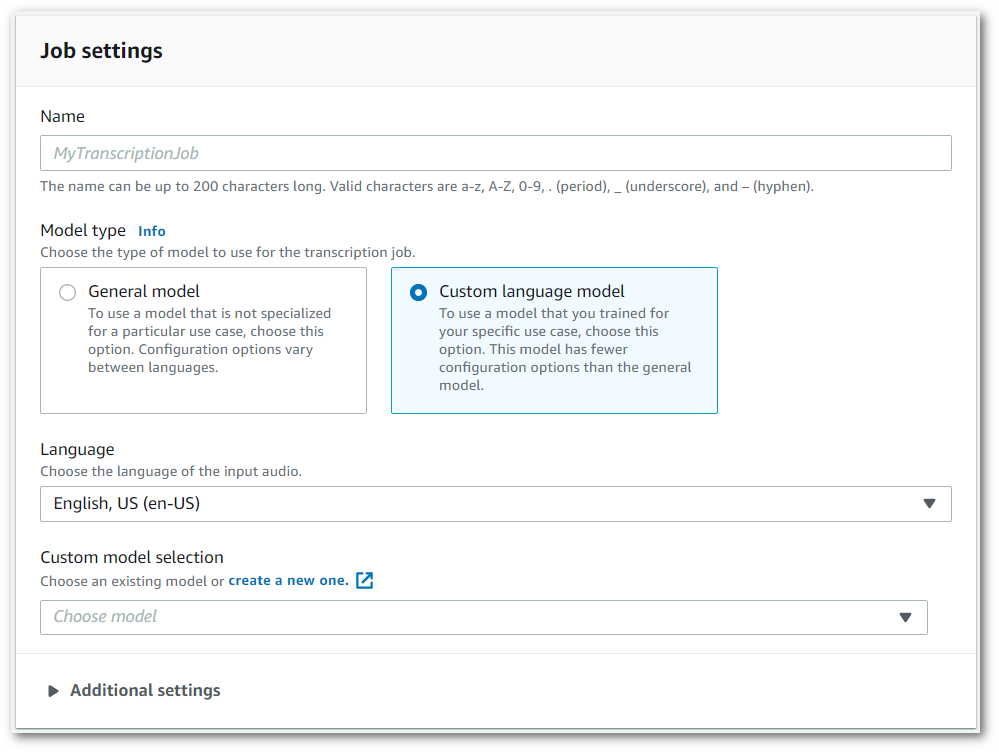
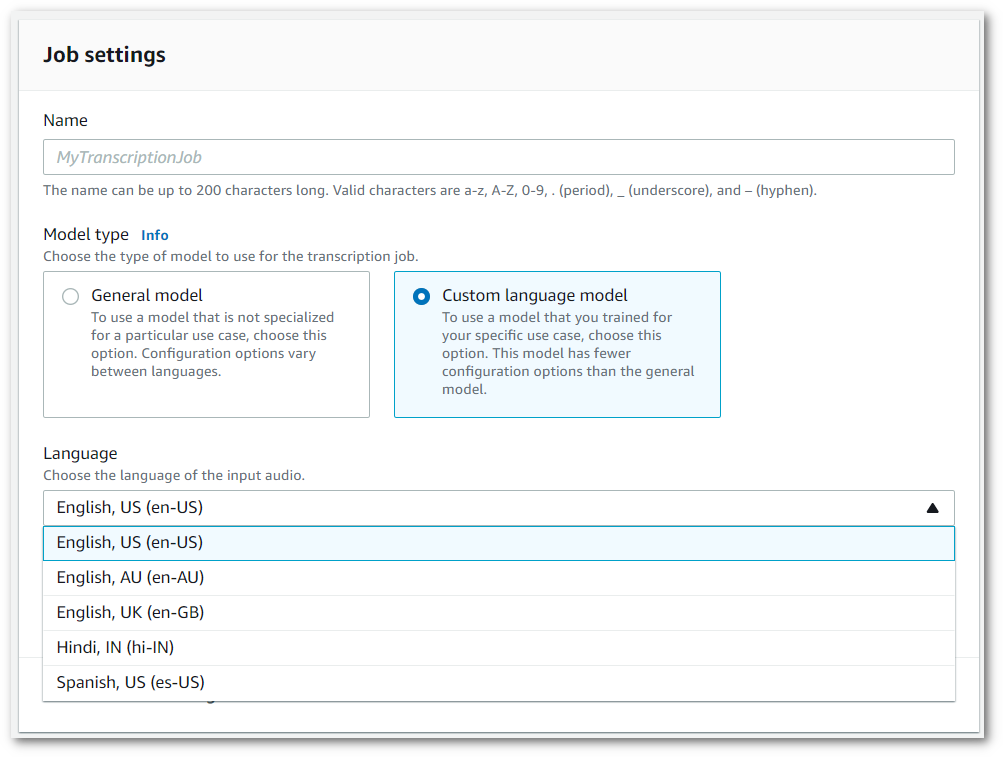
您还必须从下拉菜单中选择一种输入语言。
-
在自定义模型选择下,从下拉菜单中选择现有的自定义语言模型或创建新的自定义语言模型。
在输入数据面板中添加输入文件 Amazon S3 的位置。
-
选择下一步以查看其它配置选项。
选择创建作业以运行您的转录作业。
此示例使用带有VocabularyName子ModelSettings参数的start-transcription-jobStartTranscriptionJob 和ModelSettings。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --model-settings LanguageModelName=my-first-language-model
以下是另一个使用start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-model-job.json
my-first-model-job.json 文件包含以下请求正文。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ModelSettings": { "LanguageModelName": "my-first-language-model" } }
此示例使用 st art_transcription_ModelSettings参数来包含自定义语言模型。 适用于 Python (Boto3) 的 AWS SDK 有关更多信息,请参阅StartTranscriptionJob 和ModelSettings。
有关使用的其他示例 AWS SDKs,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ModelSettings = { 'LanguageModelName': 'my-first-language-model' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
在流式转录中使用自定义语言模型
要将自定义语言模型用于流式转录,请查看以下示例:
-
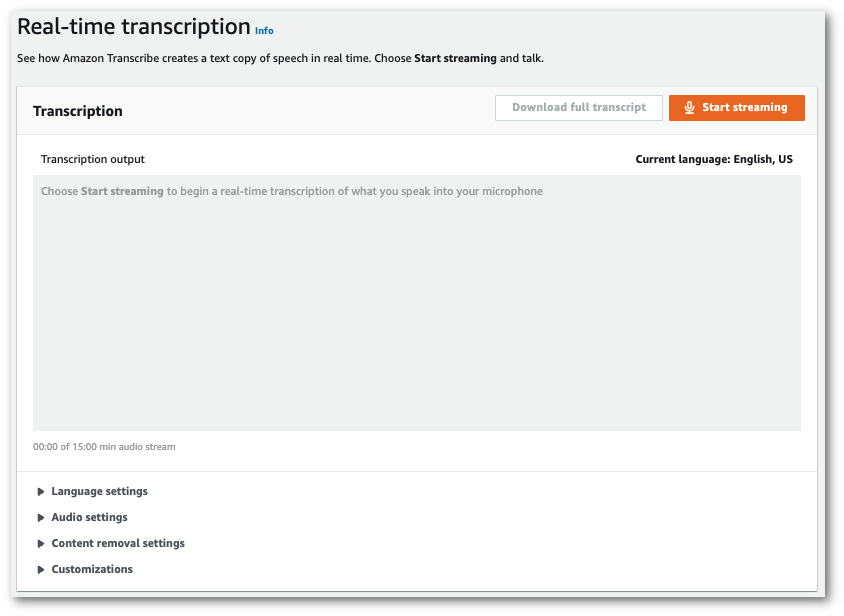
在导航窗格中,选择 Real-time transcription (实时转录)。向下滚动到自定义,如果该字段已最小化,则将其展开。
-
开启自定义语言模型,然后从下拉菜单中选择一个模型。
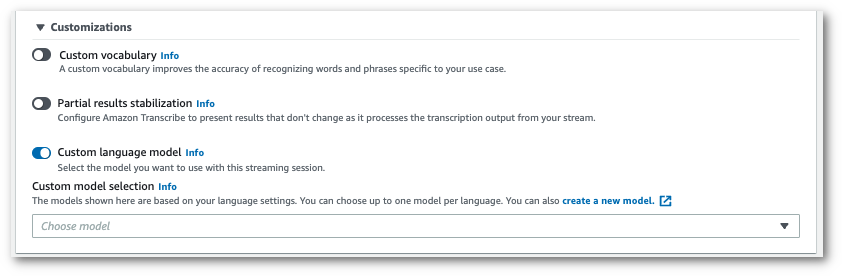
添加您希望应用于流式转录的所有其它设置。
-
您现在已准备就绪,可以转录音频流了。选择开始流式转录并开始讲话。要结束口述,请选择停止流式转录。
此示例创建了一个包含您自定义语言模型的 HTTP/2 请求。有关使用 HTTP/2 流式传输的更多信息 Amazon Transcribe,请参阅。设置 HTTP/2 音频流有关特定于的参数和标题的更多详细信息 Amazon Transcribe,请参阅StartStreamTranscription。
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-language-model-name:my-first-language-modeltransfer-encoding: chunked
此示例创建了一个预签名 URL,该网址将您的自定义语言模型应用于 WebSocket 直播。为了便于阅读,已增加了换行符。有关将 WebSocket 直播与配合使用的更多信息 Amazon Transcribe,请参阅设置直 WebSocket 播。有关参数的更多详细信息,请参阅 StartStreamTranscription。
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&language-model-name=my-first-language-model
