本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在批量转录作业中编辑 PII
在批量转录作业中,当编辑笔录中的个人身份信息 (PII) 时,请将每个已识别的 PII 实例 Amazon Transcribe 替换为笔录正文[PII]中的每个已识别的 PII 实例。您还可以查看转录输出 word-for-word部分中已编辑的 PII 类型。有关示例输出,请参阅经过编辑的输出示例(批量转录)。
美国英语 (en-US) 和美国西班牙语 () 提供带批量转录的校订。es-US编辑与语言识别不兼容。
已编辑和未编辑的记录都存储在同一个输出存储桶中。 Amazon S3 Amazon Transcribe 将它们存储在您指定的存储桶中或服务管理的默认 Amazon S3 存储桶中。
| PII 类型 | 描述 |
|---|---|
ADDRESS |
实际地址,例如 100 Main Street, Anytown, USA or Suite #12, Building 123。地址可以包括街道、办公大楼、地点、城市、州、国家、县、邮政编码、辖区和社区等信息。 |
ALL |
编辑或识别此表中列出的所有 PII 类型。 |
BANK_ACCOUNT_NUMBER |
美国银行账号。这些账号的长度通常介于 10-12 位数之间,但当只有最后 4 位数字时, Amazon Transcribe 也可以识别银行账号。 |
BANK_ROUTING |
美国银行账户的路由号码。这些账号的长度通常为 9 位数,但当只有最后 4 位数字时, Amazon Transcribe 也可以识别路由号码。 |
CREDIT_DEBIT_CVV |
VISA、 MasterCard、Discover 信用卡和借记卡上显示的 3 位数信用卡验证码 (CVV)。在美国运通信用卡或借记卡中,这是一个 4 位数的数字代码。 |
CREDIT_DEBIT_EXPIRY |
信用卡或借记卡的到期日期。此数字的长度通常为 4 位数字,格式为month/year or MM/YY。例如, Amazon Transcribe 可以识别到期日期,例如 1 月 21 日、2021 年 1 月 1 日和 2021 年 1 月。 |
CREDIT_DEBIT_NUMBER |
信用卡或借记卡的号码。这些数字的长度可以从 13 到 16 位数字不等,但当只有最后 4 位数字存在时, Amazon Transcribe 也可以识别信用卡或借记卡号。 |
EMAIL |
电子邮件地址,例如 efua.owusu@email.com。 |
NAME |
个人的名字。此实体类型不包括头衔,例如 “先生”、“女士”、“小姐” 或 “博士”, Amazon Transcribe 不将此实体类型应用于属于组织或地址的姓名。例如,将 John Doe 组织 Amazon Transcribe 识别为组织,将 Jane Doe Stre et 识别为地址。 |
PHONE |
电话号码。该实体类型还包括传真号码和寻呼机号码。 |
PIN |
一个 4 位数的个人识别码 (PIN),允许他人访问其银行账户信息。 |
SSN |
社会安全号码 (SSN) 是发给美国公民、永久居民和临时在职居民的 9 位数字。 Amazon Transcribe 当只有最后 4 位数字存在时,还可以识别社会安全号码。 |
您可以使用 AWS Management Console、 AWS CLI或 AWS SDK 启动批量转录作业。
-
在导航窗格中,选择转录作业,然后选择创建作业(右上角)。这将打开指定作业详细信息页面。
-
在指定作业详细信息页面上填写所需字段后,选择下一步转到配置作业 - 可选页面。在这里,您将找到带有 PII 编辑切换按钮的内容移除面板。
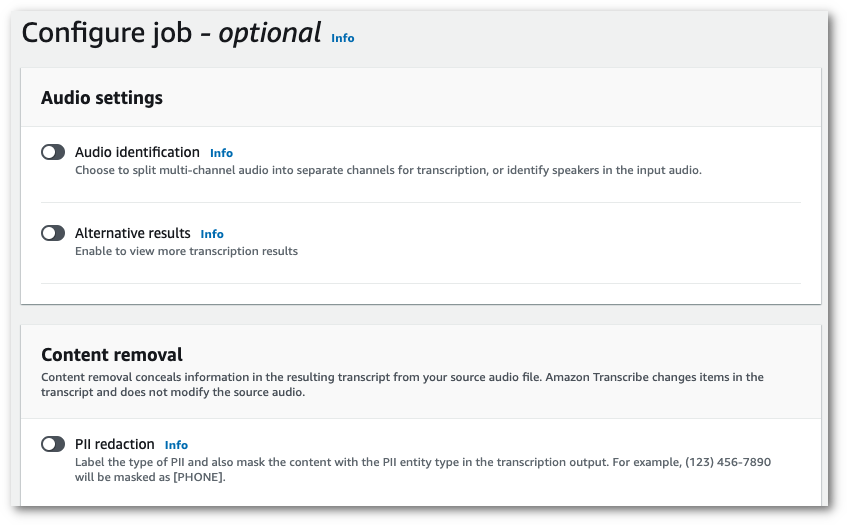
-
选择 PII 编辑后,您可以选择要编辑的所有 PII 类型。如果选择在作业输出框中包含未编辑的转录,则也可以选择使用未经编辑的转录。
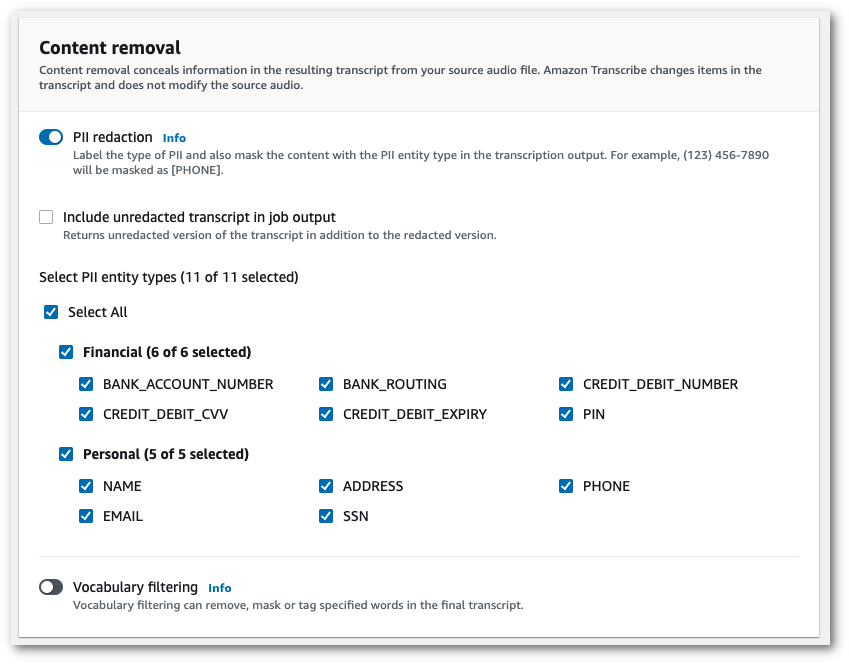
-
选择创建作业以运行您的转录作业。
此示例使用start-transcription-jobcontent-redaction参数。有关更多信息,请参阅StartTranscriptionJob 和ContentRedaction。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --content-redaction RedactionType=PII,RedactionOutput=redacted,PiiEntityTypes=NAME,ADDRESS,BANK_ACCOUNT_NUMBER
这是使用该start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-redaction-job.json
my-first-redaction-job.json 文件包含以下请求正文。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ContentRedaction": { "RedactionOutput":"redacted", "RedactionType":"PII", "PiiEntityTypes": [ "NAME", "ADDRESS", "BANK_ACCOUNT_NUMBER" ] } }
此示例使用 start_tr 适用于 Python (Boto3) 的 AWS SDK anscription_ContentRedaction参数来编辑内容。有关更多信息,请参阅StartTranscriptionJob 和ContentRedaction。
有关使用的其他示例 AWS SDKs,包括特定功能示例、场景示例和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ContentRedaction = { 'RedactionOutput':'redacted', 'RedactionType':'PII', 'PiiEntityTypes': [ 'NAME','ADDRESS','BANK_ACCOUNT_NUMBER' ] } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
注意
只有以下地区支持批处理作业的 PII 编辑 AWS 区域:亚太地区(香港)、亚太地区(孟买)、亚太地区(首尔)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、(美国西部)、加拿大(中部)、欧洲 GovCloud (法兰克福)、欧洲(爱尔兰)、欧洲(伦敦)、欧洲(巴黎)、中东(巴林)、南美洲(圣保罗)、美国东部(弗吉尼亚北部)、美国东部(俄亥俄州)、美国西部(俄勒冈)和美国西部(加利福尼亚北部)。
