本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用毒性言论检测
在批量转录中使用毒性言论检测
要将毒性言论检测与批量转录一起使用,请查看以下示例:
-
在导航窗格中,选择转录作业,然后选择创建作业(右上角)。这将打开指定作业详细信息页面。
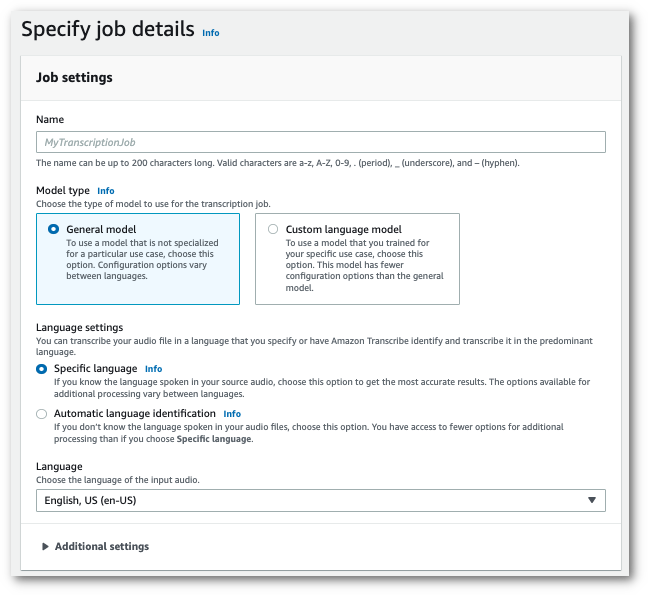
-
在指定作业详细信息页面上,您也可以根据需要启用 PII 编辑。请注意,毒性检测不支持列出的其它选项。选择下一步。此时您将会看到配置作业 - 可选页面。在音频设置 面板中,选择毒性检测。
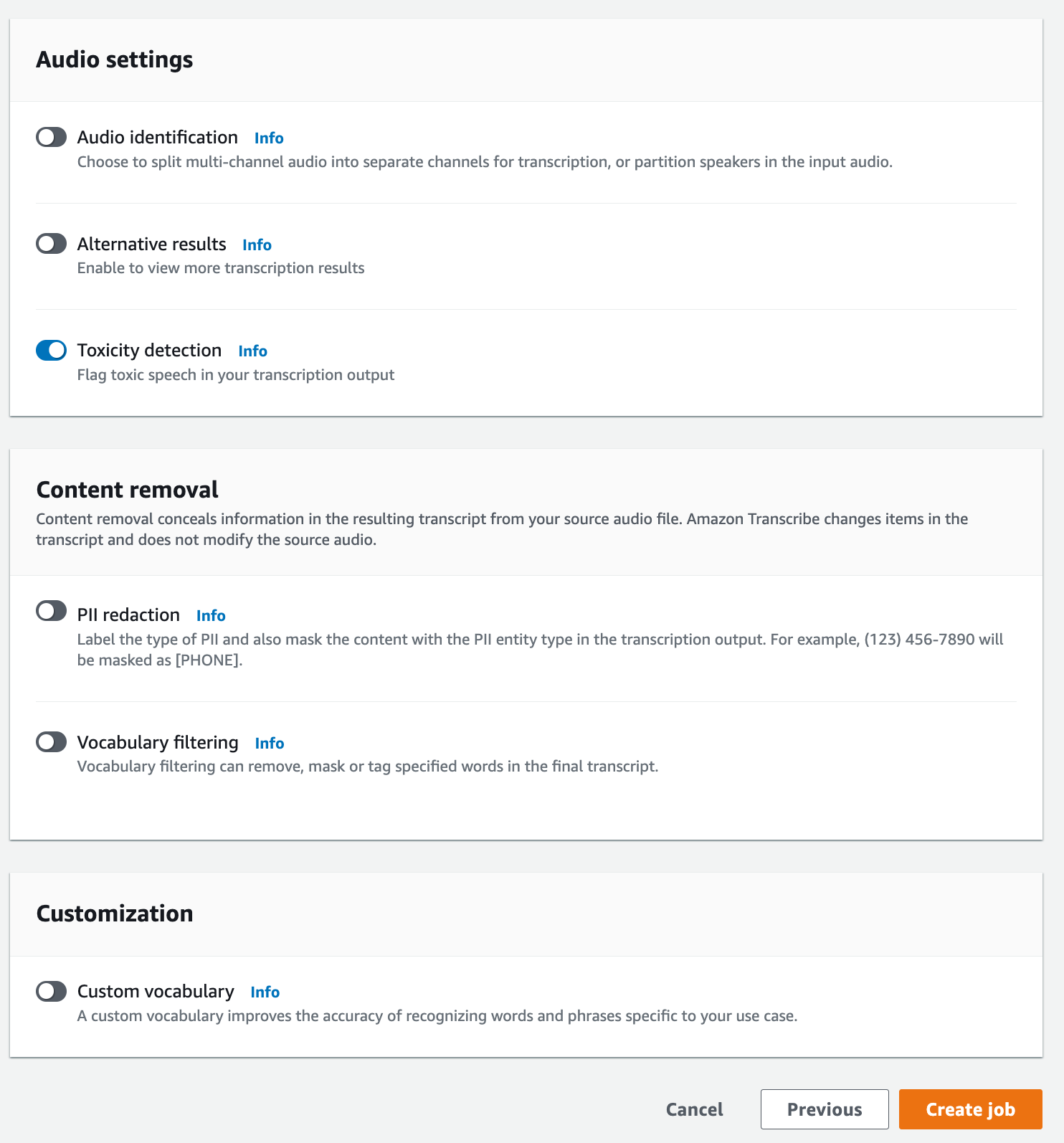
-
选择创建作业以运行您的转录作业。
-
转录作业完成后,您可以从转录作业详情页面的下载下拉菜单中下载转录。
此示例使用start-transcription-jobToxicityDetection参数。有关更多信息,请参阅StartTranscriptionJob 和ToxicityDetection。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/\ --language-code en-US \ --toxicity-detection ToxicityCategories=ALL
这是另一个使用start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-jsonfile://filepath/my-first-toxicity-job.json
my-first-toxicity-job.json 文件包含以下请求正文。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ToxicityDetection": [ { "ToxicityCategories": [ "ALL" ] } ] }
此示例使用启用 start_t ransc ToxicityDetection ription_job 方法StartTranscriptionJob 和ToxicityDetection。
有关使用的其他示例 AWS SDKs,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ToxicityDetection = [ { 'ToxicityCategories': ['ALL'] } ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
示例输出
在您的转录输出中,会对毒性言论进行标记和分类。对每个毒性言论进行分类并分配置信度分数(介于 0 和 1 之间的值)。置信度值越大,表示内容属于指定类别的毒性言论的可能性越大。
以下是 JSON 格式的示例输出,显示了经过分类的毒性言论以及相关的置信度分数。
{ "jobName": "my-toxicity-job", "accountId": "111122223333", "results": { "transcripts": [...], "items":[...], "toxicity_detection": [ { "text": "What the * are you doing man? That's why I didn't want to play with your * . man it was a no, no I'm not calming down * man. I well I spent I spent too much * money on this game.", "toxicity": 0.7638, "categories": { "profanity": 0.9913, "hate_speech": 0.0382, "sexual": 0.0016, "insult": 0.6572, "violence_or_threat": 0.0024, "graphic": 0.0013, "harassment_or_abuse": 0.0249 }, "start_time": 8.92, "end_time": 21.45 }, Items removed for brevity { "text": "What? Who? What the * did you just say to me? What's your address? What is your * address? I will pull up right now on your * * man. Take your * back to , tired of this **.", "toxicity": 0.9816, "categories": { "profanity": 0.9865, "hate_speech": 0.9123, "sexual": 0.0037, "insult": 0.5447, "violence_or_threat": 0.5078, "graphic": 0.0037, "harassment_or_abuse": 0.0613 }, "start_time": 43.459, "end_time": 54.639 }, ] }, ... "status": "COMPLETED" }
