This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Data lake foundation
Amazon S3 provides the foundation for building a data lake, along with integration to other services that can be tailored to your business needs. A common challenge faced by users when building a data lake is the categorization of data and maintaining data across different stages as it goes through the transformation process.
The following figure depicts a sample data lake and the transformation journey data goes through in its lifecycle.
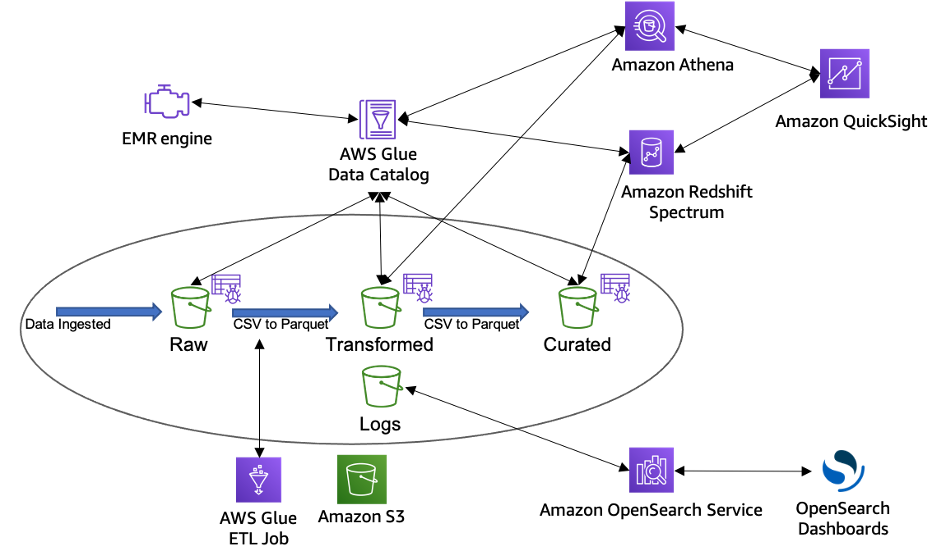
Sample data lake transformation journey
This section provides a recommended bucket strategy for building a data lake foundation.
A data lake can be broadly categorized across four distinct buckets:
-
Raw data – Data ingested from the data sources in the raw data format, which is the immutable copy of the data. This can include structured, semi structured, and unstructured data objects such as databases, backups, archives, JSON, CSV, XML, text files, or images.
-
Transformed – This bucket consists of transformed data normalized to a specific use case for performance improvement and cost reduction. In this stage, data can be transformed into columnar data formats, such as Apache Parquet and Apache ORC, which can be used by Amazon Athena.
-
Curated – The transformed data can be further enriched by blending it with other data sets to provide additional insights. This layer typically contains S3 objects which are optimized for analytics, reporting using Amazon Athena, Amazon Redshift Spectrum, and loading into massively parallel processing data warehouses such as Amazon Redshift.
-
Logs – This bucket stores process logs for Amazon S3, and other services in the data lake architecture. The logs can include S3 access logs, CloudWatch logs, or CloudTrail logs.
The following table shows a recommended sample folder structure for your data lake per environment. Each environment can have the same folder structure with tags to segregate across each environment.
Recommended sample folder structure for your data lake per environment
| Bucket | Raw | Transformed | Curated |
|---|---|---|---|
| Folder | / |
/ |
/ |
| Tagging | Object level | Object level | Object level |
| File format | Source defined | User defined (Recommended: Apache Parquet) | Final processed files (Recommended: Apache Parquet) |
| Compression | Can be applied for cost optimization | Snappy | Snappy |
| Lifecycle policy | Driven by individual object tags | Can have a bucket or object-level policy | Driven by individual object tags |
| Access | No user access. Use TBAC to enforce services principals access. | Users can have access to the bucket via AWS Lake Formation - AWS IAM | Users can have access to this data through AWS Lake Formation to a specific dataset or tables. (Column-level access is enabled and recommended for access policies.) |
| Partitioning | By source process date | By business date | By business date |
| File sizes | Source-defined | User defined (Recommended file size: 128 MB) |
|
| Encryption | AWS KMS/AWS CloudHSM/HSM | AWS KMS/AWS CloudHSM/HSM | AWS KMS/AWS CloudHSM/HSM |
It is recommended you follow best practices when defining your bucket strategy for your data lake built on Amazon S3:
-
Buckets names must be unique within a partition. Currently there are three partitions (
aws– Standard Regions,aws-cn– China Regions,aws-us-gov– AWS GovCloud (US); however, names can be reused after the buckets are deleted (with several exceptions). -
Deleted bucket names are not available to reuse immediately; hence, if users want to use a particular bucket name, they should not delete the bucket.
-
All bucket names across all AWS Regions should comply with DNS naming conventions.
-
Buckets can store an unlimited number of objects in a bucket without impacting performance. The objects can be stored in a single bucket or across multiple buckets; however, you cannot create a bucket from within another bucket.
-
Production S3 buckets should be hosted under a different AWS account, separate from non-production workloads.
-
Build an automatic ingestion mechanism to catalog and create the multiple layers of data storage including Raw, Transformed, and Curated.
-
Consider building automatic data classification rules based on schema and data.
-
Consider additional folders within the data lakes, such as reports, downstream applications, or user folders.
-
Enable versioning, if needed, for protection from accidental deletes.
-
Use separate buckets for S3 data which needs to be replicated.
