第 5 步:生成和使用预测进行决策
一旦您有了满足特定使用案例所需的精度阈值(通过回溯测试确定)的模型,最后一步就是部署模型和生成预测。要在 Amazon Forecast 中部署模型,您必须运行 Create_Forecast API。此操作托管通过对整个历史数据集进行训练而创建的模型(与 Create_Predictor 不同,它会将数据拆分为训练集和测试集)。然后,可以通过两种方式使用在预测范围内生成的模型预测:
-
您可以使用
Query_ForecastAPI 从 AWS CLI或直接通过 AWS Management Console ,查询特定商品的预测(通过指定商品或商品/维度的组合)。 -
您可以使用
Create_Forecast_Export_JobAPI 为所有分位数的所有商品和维度组合生成预测。此 API 会生成一个 CSV 文件,该文件安全地存储在您选择的 Amazon Simple Storage Service(Amazon S3)位置。然后,您可以使用 CSV 文件中的数据,将它们插入用于决策的下游系统。例如,您现有的供应链系统可以直接从 Amazon Forecast 中提取输出,帮助就特定 SKU 的制造做出决策。
概率预测
Amazon Forecast 可以在不同分位数处生成预测,这在预测不足和过度预测的成本不同时特别有用。与预测器训练阶段类似,可以为 p1 到 p99 之间的分位数生成概率预测。
默认情况下,Amazon Forecast 针对预测器训练期间使用的相同分位数生成预测。如果在预测器训练期间未指定分位数,则默认情况下将在 p10、p50 和 p90 处生成预测。
对于 p10 预测,预计真实值将在 10% 的时间内低于预测值,并且 wQL[0.1] 指标可用于评测其精度。这意味着在 90% 的时间内,P10 的预测被低估了,如果用来储备库存,90% 的时间内该商品会被售完。当存储空间不足,或者投资资本成本比较高时,P10 预测可能很有用。
注意
分位数预测的正式定义是 Pr(实际值 <= 分位数 q 处的预测)= q。从技术上讲,分位数是百分位数/100。统计学家倾向于说“P90 分位数层次”,因为这比“分位数 0.9”更容易说。例如,P90 分位数层次的预测意味着可以预计实际值在 90% 的时间内小于预测值。具体而言,如果 time=t1 和 quantile-level=0.9,预测值 = 30,这意味着如果您有 1000 次模拟,则在 time= t1 时的实际值预计将在 900 次模拟中小于 30,而对于 100 次模拟,实际值预计将超过 30。
另一方面,在 90% 的时间中,P90 预测是过度预测的,当不出售商品的机会成本极高或投资资本成本很低时,它很有用。对于杂货店来说,P90 预测可能用于牛奶或厕纸之类的东西,商店永远不想售完,也不介意总是有一些留在货架上。
对于 p50 预测(通常也称为中位数预测),预计真实值将在 50% 的时间内低于预测值,并且 wQL[0.5] 指标可用于评测其精度。如果库存积压并不太令人担忧,并且对给定商品的需求适度,此时 p50 分位数预测可能很有用。
可视化
Amazon Forecast 允许在AWS Management Console中本地绘制预测。此外,您还可以利用完整的 Python 数据科学堆栈(参见 Amazon Forecast 示例ExportForecastJob API 将预测导出为 CSV 文件,这允许用户在他们选择的分析工具中对预测进行可视化。
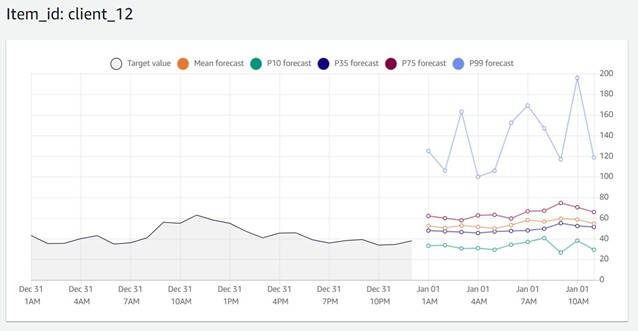
在 Amazon Forecast 控制台中对不同的分位数提供的可视化
