本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
io/aurora_redo_log_flush
當工作階段將持久性資料寫入至 Amazon Aurora 儲存體時,io/aurora_redo_log_flush 事件便會發生。
支援的引擎版本
下列引擎版本支援這個等待事件資訊:
-
Aurora MySQL 第 2 版
Context
io/aurora_redo_log_flush 事件適用於 Aurora My 中的寫入 input/output (I/O) 操作SQL。
注意
在 Aurora MySQL 第 3 版中,此等待事件名為 io/redo_log_flush。
等待時間增加的可能原因
對於資料持久性,遞交需要持久寫入至穩定的儲存。如果資料庫執行太多的遞交,寫入輸入/輸出作業上會有等待事件,即 io/aurora_redo_log_flush 等待事件。
在下列範例中,使用 db.r5.xlarge 資料庫執行個體類別將 50,000 筆記錄插入 Aurora MySQL 資料庫叢集:
-
在第一個範例中,每個工作階段逐列插入 10,000 筆記錄。根據預設,如果資料處理語言 (DML) 命令不在交易中,Aurora MySQL 會使用隱含遞交。系統會開啟自動遞交。這表示對於每個資料列插入都有一個遞交。績效詳情顯示,連線花費其大部分時間等待
io/aurora_redo_log_flush等待事件。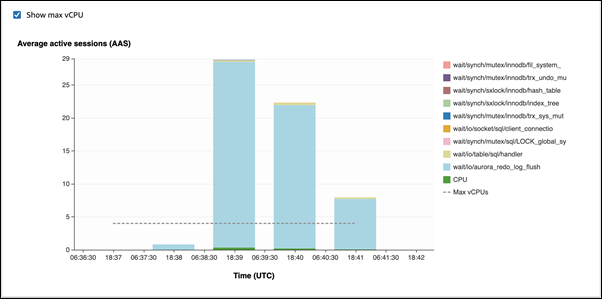
這是由使用的簡單插入陳述式引起的。
插入 50,000 筆記錄需要 3.5 分鐘。
-
在第二個範例中,插入是以 1,000 個批次進行,亦即每個連線執行 10 個遞交,而不是 10,000 個。績效詳情顯示,連線不會將其大部分時間花費在
io/aurora_redo_log_flush等待事件上。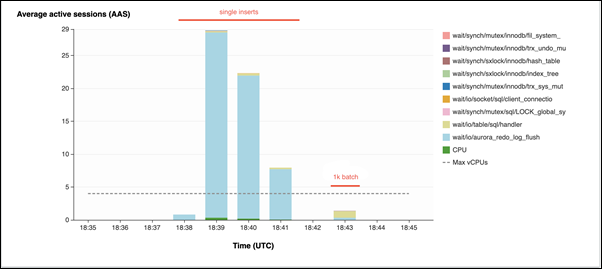
插入 50,000 筆記錄需要 4 秒。
動作
根據等待事件的原因,我們會建議不同的動作。
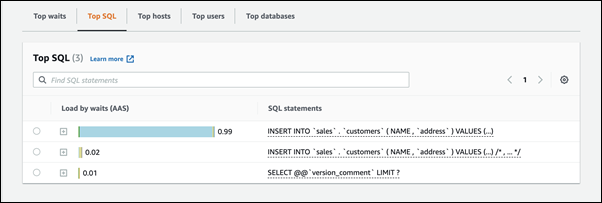
識別有問題的工作階段和查詢
如果您的資料庫執行個體遭遇瓶頸,您的第一項任務是尋找造成瓶頸的工作階段和查詢。如需實用的 AWS 資料庫部落格文章,請參閱使用績效詳情分析 Amazon Aurora MySQL Workloads
識別造成瓶頸的工作階段和查詢
登入 AWS Management Console ,並在 開啟 Amazon RDS主控台https://console.aws.amazon.com/rds/
。 -
在導覽窗格中,選擇 Performance Insights (績效詳情)。
-
選擇資料庫執行個體。
-
在 Database load (資料庫負載) 中,選擇 Slice by wait (依等待建立配量)。
-
在頁面底部,選擇頂端 SQL。
清單頂端的查詢對資料庫造成最高負載。
將您的寫入作業分組
下列範例會觸發 io/aurora_redo_log_flush 等待事件。(系統會開啟自動遞交)。
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
若要減少等待 io/aurora_redo_log_flush 等待事件所花費的時間,將您的寫入作業邏輯分組為單一遞交,以減少持續呼叫儲存。
關閉自動遞交
在進行不在交易內的大規模變更之前,請先關閉自動遞交,如下列範例所示。
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
使用交易
您可以使用交易,如下列範例所示。
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
使用批次
您也可以批次進行變更,如下列範例所示。不過,使用過大的批次可能會導致效能問題,特別是在僅供讀取複本或執行 point-in-time復原時 (PITR)。
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
