本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將資料新增至來源 RDS 資料庫並進行查詢
若要完成建立將資料從 Amazon RDS 複寫到 Amazon Redshift 的零 ETL 整合,您必須在目標目的地中建立資料庫。
對於與 Amazon Redshift 的連線,請連線至 Amazon Redshift 叢集或工作群組,並建立參考整合識別符的資料庫。然後,您可以將資料新增至來源 RDS 資料庫,並查看在 Amazon Redshift 或 中複寫的資料Amazon SageMaker。
主題
建立目標資料庫
您必須先在目標資料倉儲中建立資料庫,才能開始將資料複寫至 Amazon Redshift。此資料庫必須包含整合識別符的參考。您可以使用 Amazon Redshift 主控台或查詢編輯器第 2 版來建立資料庫。
如需建立目的地資料庫的指示,請參閱在 Amazon Redshift 中建立目的地資料庫。
將資料新增至來源資料庫
設定整合之後,您可以將要複寫至資料倉儲的資料填入來源 RDS 資料庫。
注意
Amazon RDS 中的資料類型與目標分析倉儲之間存在差異。如需資料類型映射的資料表,請參閱 RDS 與 Amazon Redshift 資料庫之間的資料類型差異。
首先,使用您選擇的 MySQL 用戶端連線至來源資料庫。如需說明,請參閱連線至 MySQL 資料庫執行個體。
然後,建立資料表並插入一列範例資料。
重要
請確定資料表具有主索引鍵。否則,無法將其複寫到目標資料倉儲。
RDS for MySQL
下列範例使用 MySQL Workbench 公用程式
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for PostgreSQL
下列範例使用 psql PostgreSQL 互動式終端機。連線至資料庫時,請包含您要複寫的資料庫名稱。
psql -hmydatabase.123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for Oracle
下列範例使用 SQL*Plus 連線至 RDS for Oracle 資料庫。
sqlplus 'user_name@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_name)(PORT=port))(CONNECT_DATA=(SID=database_name)))' SQL> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); SQL> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
在 Amazon Redshift 中查詢 Amazon RDSAurora 資料
將資料新增至 RDS 資料庫後,資料會複寫至目的地資料庫,並準備好進行查詢。
查詢複製的資料
-
導覽至 Amazon Redshift 主控台,然後從左側導覽窗格中選擇查詢編輯器第 2 版。
-
連線到您的叢集或工作群組,然後從下拉式功能表中選擇您已從整合中建立的目的地資料庫 (在此範例中為 destination_database)。如需建立目的地資料庫的指示,請參閱在 Amazon Redshift 中建立目的地資料庫。
-
使用 SELECT 陳述式查詢您的資料。在此範例中,您可以執行下列命令,從您在來源 RDS 資料庫中建立的資料表中選取所有資料:
SELECT * frommy_db."books_table";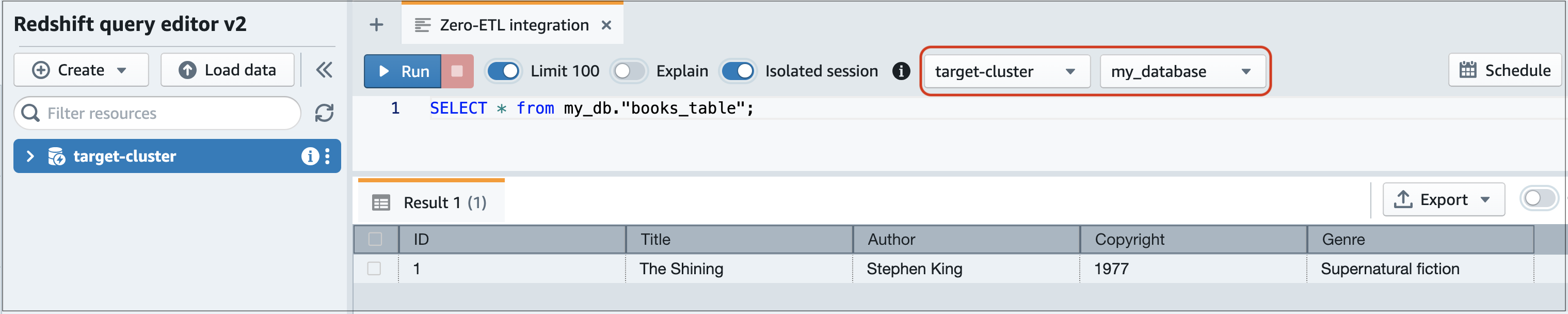
-
my_db -
books_table
-
您也可以使用命令列用戶端查詢資料。例如:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
注意
如需區分大小寫,請針對結構描述、資料表和資料欄名稱使用雙引號 (" ")。如需詳細資訊,請參閱 enable_case_sensitive_identifier。
RDS 與 Amazon Redshift 資料庫之間的資料類型差異
下表顯示 RDS for MySQL、RDS for PostgreSQL 和 RDS for Oracletables 的映射。Amazon RDS 目前僅支援零 ETL 整合的這些資料類型。
如果來源資料庫中的資料表包含不支援的資料類型,則資料表會不同步,且目的地目標不會消耗。從來源到目標的串流會繼續進行,但是無法使用其中資料類型不受支援的資料表。若要修正資料表並在目標目的地中提供,您必須手動還原重大變更,然後執行 重新整理整合ALTER DATABASE...INTEGRATION REFRESH。
注意
您無法重新整理與 Lakehouse Amazon SageMaker 的零 ETL 整合。相反地,請刪除 並嘗試再次建立整合。
RDS for MySQL
| RDS for MySQL 資料類型 | 目標資料類型 | 描述 | 限制 |
|---|---|---|---|
| INT | INTEGER | 帶正負號的 4 位元組整數 | 無 |
| SMALLINT | SMALLINT | 帶正負號的 2 位元組整數 | 無 |
| TINYINT | SMALLINT | 帶正負號的 2 位元組整數 | 無 |
| MEDIUMINT | INTEGER | 帶正負號的 4 位元組整數 | 無 |
| BIGINT | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| INT UNSIGNED | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| TINYINT UNSIGNED | SMALLINT | 帶正負號的 2 位元組整數 | 無 |
| MEDIUMINT UNSIGNED | INTEGER | 帶正負號的 4 位元組整數 | 無 |
| BIGINT UNSIGNED | DECIMAL(20,0) | 可選擇精確度 (有效位數) 的精確數值 | 無 |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | 可選擇精確度 (有效位數) 的精確數值 |
不支援大於 38 的精確度和大於 37 的擴展 |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | 可選擇精確度 (有效位數) 的精確數值 |
不支援大於 38 的精確度和大於 37 的擴展 |
| FLOAT4/REAL | REAL | 單精度浮點數 | 無 |
| FLOAT4/REAL UNSIGNED | REAL | 單精度浮點數 | 無 |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | 雙精度浮點數 | 無 |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | 雙精度浮點數 | 無 |
| BIT(n) | VARBYTE(8) | 可變長度二進位值 | 無 |
| BINARY(n) | VARBYTE(n) | 可變長度二進位值 | 無 |
| VARBINARY(n) | VARBYTE(n) | 可變長度二進位值 | 無 |
| CHAR(n) | VARCHAR(n) | 可變長度字串值 | 無 |
| VARCHAR(n) | VARCHAR(n) | 可變長度字串值 | 無 |
| TEXT | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| TINYTEXT | VARCHAR(255) | 變數長度字串值最多 255 個字元 | 無 |
| MEDIUMTEXT | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| LONGTEXT | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| ENUM | VARCHAR(1020) | 變數長度字串值最多 1,020 個字元 | 無 |
| SET | VARCHAR(1020) | 變數長度字串值最多 1,020 個字元 | 無 |
| DATE | DATE | 日曆日期 (年、月、日) | 無 |
| DATETIME | TIMESTAMP | 日期和時間 (未使用時區) | 無 |
| TIMESTAMP(p) | TIMESTAMP | 日期和時間 (未使用時區) | 無 |
| TIME | VARCHAR(18) | 變數長度字串值最多 18 個字元 | 無 |
| YEAR | VARCHAR(4) | 變數長度字串值最多 4 個字元 | 無 |
| JSON | SUPER | 半結構化資料或文件作為值 | 無 |
RDS for PostgreSQL
RDS for PostgreSQL 的零 ETL 整合不支援自訂資料類型或延伸模組建立的資料類型。
| RDS for PostgreSQL 資料類型 | Amazon Redshift 資料類型 | 描述 | 限制 |
|---|---|---|---|
| 陣列 | SUPER | 半結構化資料或文件作為值 | 無 |
| bigint | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| bigserial | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| 位元變化 (n) | VARBYTE(n) | 可變長度二進位值,最多 16,777,216 個位元組 | 無 |
| bit(n) | VARBYTE(n) | 可變長度二進位值,最多 16,777,216 個位元組 | 無 |
| 位元、位元變化 | VARBYTE(16777216) | 可變長度二進位值,最多 16,777,216 個位元組 | 無 |
| boolean | BOOLEAN | 邏輯布林值 (true/false) | 無 |
| bytea | VARBYTE(16777216) | 可變長度二進位值,最多 16,777,216 個位元組 | 無 |
| char(n) | CHAR(n) | 固定長度字元字串值最多 65,535 個位元組 | 無 |
| 字元變化 (n) | VARCHAR(65535) | 可變長度字元字串值最多 65,535 個字元 | 無 |
| cid | BIGINT |
帶正負號的 8 位元組整數 |
無 |
| cidr |
VARCHAR(19) |
變數長度字串值最多 19 個字元 |
無 |
| date | DATE | 日曆日期 (年、月、日) |
不支援大於 294,276 A.D. 的值 |
| double precision | DOUBLE PRECISION | 雙精確度浮點數 | 未完全支援的異常值 |
|
gtsvector |
VARCHAR(65535) |
變數長度字串值最多 65,535 個字元 |
無 |
| inet |
VARCHAR(19) |
變數長度字串值最多 19 個字元 |
無 |
| integer | INTEGER | 帶正負號的 4 位元組整數 | 無 |
|
int2vector |
SUPER | 半結構化資料或文件做為值。 | 無 |
| 間隔 | INTERVAL | 持續時間 | 僅支援指定年到月或日到秒限定詞的 INTERVAL 類型。 |
| json | SUPER | 半結構化資料或文件作為值 | 無 |
| jsonb | SUPER | 半結構化資料或文件作為值 | 無 |
| jsonpath | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
|
macaddr |
VARCHAR(17) | 變數長度字串值最多 17 個字元 | 無 |
|
macaddr8 |
VARCHAR(23) | 變數長度字串值最多 23 個字元 | 無 |
| money | DECIMAL(20,3) | 貨幣金額 | 無 |
| name | VARCHAR(64) | 變數長度字串值最多 64 個字元 | 無 |
| numeric(p,s) | DECIMAL(p,s) | 使用者定義的固定精確度值 |
|
| oid | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| 向量 | SUPER | 半結構化資料或文件做為值。 | 無 |
| pg_brin_bloom_summary | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| pg_dependencies | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| pg_lsn | VARCHAR(17) | 變數長度字串值最多 17 個字元 | 無 |
| pg_mcv_list | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| pg_ndistinct | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| pg_node_tree | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| pg_snapshot | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| real | REAL | 單精度浮點數 | 未完全支援的異常值 |
| 反射器 | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| smallint | SMALLINT | 帶正負號的 2 位元組整數 | 無 |
| smallserial | SMALLINT | 帶正負號的 2 位元組整數 | 無 |
| serial | INTEGER | 帶正負號的 4 位元組整數 | 無 |
| text | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| tid | VARCHAR(23) | 變數長度字串值最多 23 個字元 | 無 |
| time 【(p)】 不含時區 | VARCHAR(19) | 變數長度字串值最多 19 個字元 | Infinity 不支援 和 -Infinity值 |
| time 【(p)】 與時區 | VARCHAR(22) | 變數長度字串值最多 22 個字元 | Infinity 不支援 和 -Infinity值 |
| 沒有時區的時間戳記 【(p)】 | TIMESTAMP | 日期和時間 (未使用時區) |
|
| 具有時區的時間戳記 【(p)】 | TIMESTAMPTZ | 日期和時間 (包含時區) |
|
| 查詢 | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| tvector | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| txid_snapshot | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
| uuid | VARCHAR(36) | 可變長度 36 個字元字串 | 無 |
| xid | BIGINT | 帶正負號的 8 位元組整數 | 無 |
| xid8 | DECIMAL(20, 0) | 修正精確度小數位數 | 無 |
| xml | VARCHAR(65535) | 變數長度字串值最多 65,535 個字元 | 無 |
RDS for Oracle
不支援的資料類型
Amazon Redshift 不支援下列 RDS for Oracle 資料類型:
-
ANYDATA -
BFILE -
REF -
ROWID -
UROWID -
VARRAY -
SDO_GEOMETRY -
使用者定義的資料類型
資料類型差異
下表顯示當 RDS for Oracle 是來源且 Amazon Redshift 是目標時,影響零 ETL 整合的資料類型差異。
| RDS for Oracle 資料類型 | Amazon Redshift 資料類型 |
|---|---|
|
BINARY_FLOAT |
FLOAT4 |
|
BINARY_DOUBLE |
FLOAT8 |
|
BINARY |
VARCHAR (長度) |
|
FLOAT (P) |
如果精確度 =< 24,則 FLOAT4。 如果精確度 > 24,則 FLOAT8。 |
|
NUMBER (P,S) |
如果擴展 => 0 且 =< 37,則 NUMERIC (p,s)。 如果擴展 => 38 且 =< 127,則 VARCHAR (長度)。 如果比例為 0:
如果擴展小於 0,則為 INT8。 |
|
DATE |
如果比例為 => 0 且 =< 6,取決於 Redshift 目標資料欄類型,則為下列其中一項:
如果比例為 => 7 且 =< 9,則 VARCHAR (37)。 |
|
INTERVAL_YEAR TO MONTH |
如果長度為 1–65,535,則 VARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 VARCHAR (65535)。 |
|
INTERVAL_DAY TO SECOND |
如果長度為 1–65,535,則 VARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 VARCHAR (65535)。 |
|
TIMESTAMP |
如果比例為 => 0 且 =< 6,取決於 Redshift 目標資料欄類型,則為下列其中一項:
如果比例為 => 7 且 =< 9,則 VARCHAR (37)。 |
|
TIMESTAMP WITH TIME ZONE |
如果長度為 1–65,535,則 VARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 VARCHAR (65535)。 |
|
TIMESTAMP WITH LOCAL TIME ZONE |
如果長度為 1–65,535,則 VARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 VARCHAR (65535)。 |
|
CHAR |
如果長度為 1–65,535,則 VARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 VARCHAR (65535)。 |
|
VARCHAR2 |
當長度大於 4,000 個位元組時,則 VARCHAR (LOB 大小上限)。LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 當長度為 4,000 個位元組或更少時,則 VARCHAR (長度以位元組為單位)。 |
|
NCHAR |
如果長度為 1–65,535,則 NVARCHAR (長度以位元組為單位)。 如果長度為 65,536–2,147,483,647,則 NVARCHAR (65535)。 |
|
NVARCHAR2 |
當長度大於 4,000 個位元組時,則為 NVARCHAR (LOB 大小上限)。LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 當長度為 4,000 個位元組或更少時,則 NVARCHAR (長度以位元組為單位)。 |
|
RAW |
VARCHAR (長度) |
|
REAL |
FLOAT8 |
|
BLOB |
VARCHAR (LOB 大小上限 * 2) LOB 大小上限不能超過 31 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
|
CLOB |
VARCHAR (LOB 大小上限) LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
|
NCLOB |
NVARCHAR (LOB 大小上限) LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
|
LONG |
VARCHAR (LOB 大小上限) LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
|
LONG RAW |
VARCHAR (LOB 大小上限 * 2) LOB 大小上限不能超過 31 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
|
XMLTYPE |
VARCHAR (LOB 大小上限) LOB 大小上限不能超過 63 KB。Amazon Redshift 不支援大於 64 KB VARCHARs。 |
RDS for PostgreSQL 的 DDL 操作
Amazon Redshift 衍生自 PostgreSQL,因此由於其常見的 PostgreSQL 架構,它與 RDS for PostgreSQL PostgreSQL 共用數個功能。零 ETL 整合利用這些相似性來簡化從 RDS for PostgreSQL 到 Amazon Redshift 的資料複寫、依名稱映射資料庫,以及利用共用資料庫、結構描述和資料表結構。
管理 RDS for PostgreSQL 零 ETL 整合時,請考慮下列事項:
-
隔離是在資料庫層級管理。
-
複寫會在資料庫層級發生。
-
RDS for PostgreSQL 資料庫會依名稱映射至 Amazon Redshift 資料庫,如果原始資料庫重新命名,資料會流向對應的重新命名 Redshift 資料庫。
雖然兩者相似,但 Amazon Redshift 和 RDS for PostgreSQL 仍有重要的差異。下列各節概述常見 DDL 操作的 Amazon Redshift 系統回應。
資料庫操作
下表顯示資料庫 DDL 操作的系統回應。
| DDL 操作 | Redshift 系統回應 |
|---|---|
CREATE DATABASE |
無操作 |
DROP DATABASE |
Amazon Redshift 會捨棄目標 Redshift 資料庫中的所有資料。 |
RENAME DATABASE |
Amazon Redshift 會捨棄原始目標資料庫中的所有資料,並重新同步新目標資料庫中的資料。如果新的資料庫不存在,您必須手動建立資料庫。如需說明,請參閱在 Amazon Redshift 中建立目的地資料庫。 |
結構描述操作
下表顯示結構描述 DDL 操作的系統回應。
| DDL 操作 | Redshift 系統回應 |
|---|---|
CREATE SCHEMA |
無操作 |
DROP SCHEMA |
Amazon Redshift 會捨棄原始結構描述。 |
RENAME SCHEMA |
Amazon Redshift 會捨棄原始結構描述,然後重新同步新結構描述中的資料。 |
資料表操作
下表顯示資料表 DDL 操作的系統回應。
| DDL 操作 | Redshift 系統回應 |
|---|---|
CREATE TABLE |
Amazon Redshift 會建立資料表。 有些操作會導致資料表建立失敗,例如在沒有主索引鍵的情況下建立資料表,或執行宣告性分割。如需詳細資訊,請參閱限制及對 Amazon RDS Aurora零 ETL 整合進行故障診斷。 |
DROP TABLE |
Amazon Redshift 捨棄資料表。 |
TRUNCATE TABLE |
Amazon Redshift 會截斷資料表。 |
ALTER TABLE
(RENAME...) |
Amazon Redshift 會重新命名資料表或資料欄。 |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift 會在原始結構描述中捨棄資料表,並重新同步新結構描述中的資料表。 |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift 新增主索引鍵並重新同步資料表。 |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift 會將資料欄新增至資料表。 |
ALTER TABLE (DROP
COLUMN) |
如果資料欄不是主索引鍵資料欄,Amazon Redshift 會捨棄資料欄。否則,它會重新同步資料表。 |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
如果您將資料表變更為已記錄,Amazon Redshift 會重新同步資料表。如果您將資料表變更為未記錄,Amazon Redshift 會捨棄資料表。 |
