本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 DynamoDB 中使用全域次要索引進行具體化彙總查詢
快速變更的資料中維護接近即時彙總和索引鍵指標,對於企業來說變得越來越重要。例如,音樂資料庫可能想要以接近即時的速度展示最常下載的歌曲。
考慮下列音樂資料庫資料表配置:
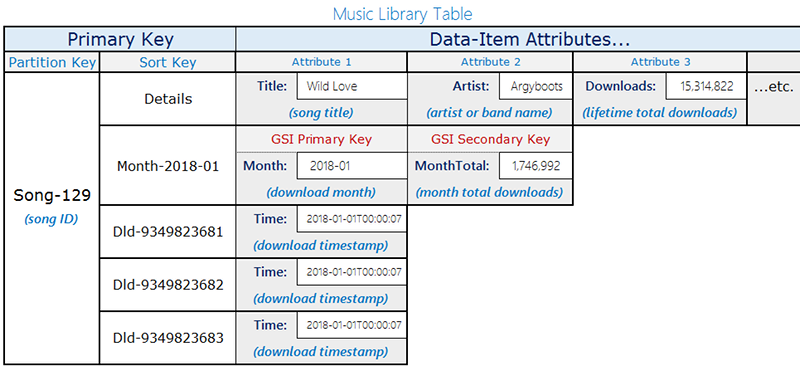
此範例的資料表會使用 songID 做為分割區索引鍵來儲存歌曲。您可以在此資料表上啟用 Amazon DynamoDB Streams 並將 Lambda 函數附加到該串流中,如此隨著每個歌曲的下載,系統會使用 Partition-Key=SongID 和 Sort-Key=DownloadID 來將項目新增至資料表。隨著這些更新的進行,更新會在 DynamoDB Streams 中觸發 Lambda 函數。Lambda 函數可能會彙總並依照 songID 分組下載並更新頂層項目、Partition-Key=songID 和 Sort-Key=Month。請記住,如果 lambda 執行在寫入新的彙總值之後失敗,則可能會重試並將該值多次彙總,留下近似值。
若要以單位毫秒延遲,接近即時的速度讀取更新,則使用全域次要索引,內含查詢條件 Month=2018-01、ScanIndexForward=False、Limit=1。
在此使用的另一個最佳化方式是將全域次要索引定為稀疏索引,且僅在需要查詢即時擷取資料的項目時才供使用。在需要排名前十流行歌曲或在該月下載的任何歌曲的資訊時,全域次要索引可以做為額外工作流程。
