本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將全域次要索引寫入碎片用於 DynamoDB 中的選擇性資料表查詢
當您需要查詢特定時段內的最新資料時,DynamoDB 為大多數讀取操作提供分割區索引鍵的需求可能會帶來挑戰。若要解決這種情況,您可以使用寫入碎片和全域次要索引 (GSI) 的組合來實作有效的查詢模式。
這種方法可讓您有效率地擷取和分析時間敏感的資料,而無需執行完整的資料表掃描,這可能會耗費大量資源且成本高昂。透過策略性設計資料表結構和索引,您可以建立彈性解決方案,支援以時間為基礎的資料擷取,同時維持最佳效能。
模式設計
使用 DynamoDB 時,您可以透過實作結合寫入碎片和全域次要索引的複雜模式,在最近的資料時段之間啟用靈活、有效率的查詢,來克服以時間為基礎的資料擷取挑戰。
資料表的結構
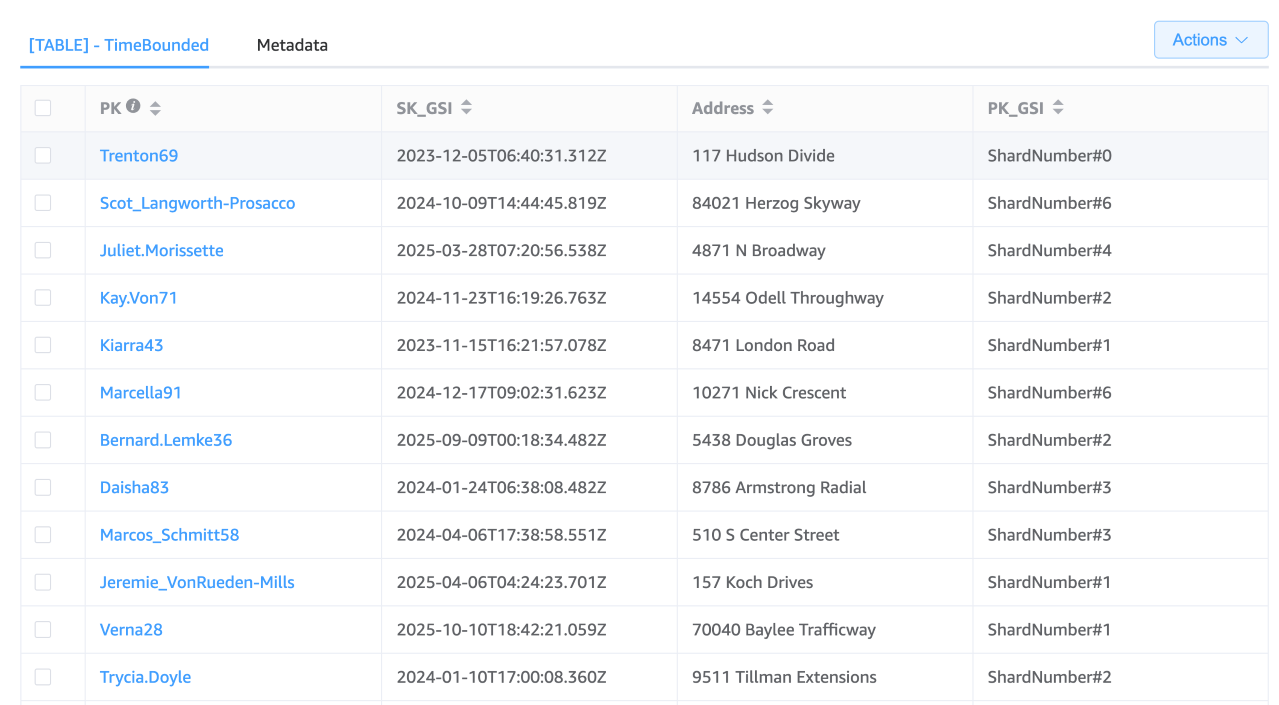
分割區索引鍵 (PK):"Username"
GSI 的結構
GSI 分割區索引鍵 (PK_GSI):"ShardNumber#"
GSI 排序金鑰 (SK_GSI):ISO 8601 時間戳記 (例如 "2030-04-01T12:00:00Z")
碎片策略
假設您決定使用 10 個碎片,您的碎片號碼範圍可從 0 到 9。記錄活動時,您會計算碎片編號 (例如,在使用者 ID 上使用雜湊函數,然後取得碎片數量的模數),並將其附加到 GSI 分割區索引鍵。此方法會將項目分散到不同的碎片,降低熱分割區的風險。
查詢碎片 GSI
在 DynamoDB 資料表中,查詢 DynamoDB 資料表中特定時間範圍內項目的所有碎片,其中資料分片跨越多個分割區索引鍵,需要與查詢單一分割區不同的方法。由於 DynamoDB 查詢一次僅限於單一分割區索引鍵,因此您無法透過單一查詢操作直接跨多個碎片進行查詢。不過,您可以透過應用程式層級邏輯來達成所需的結果,方法是執行多個查詢,每個查詢都以特定碎片為目標,然後彙總結果。以下程序說明如何執行此操作。
查詢和彙總碎片
識別碎片策略中使用的碎片編號範圍。例如,如果您有 10 個碎片,您的碎片編號範圍為 0-9。
針對每個碎片,建構並執行查詢,以擷取所需時間範圍內的項目。這些查詢可以平行執行,以提高效率。使用分割區索引鍵搭配碎片號碼,以及排序索引鍵搭配這些查詢的時間範圍。以下是單一碎片的範例查詢:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'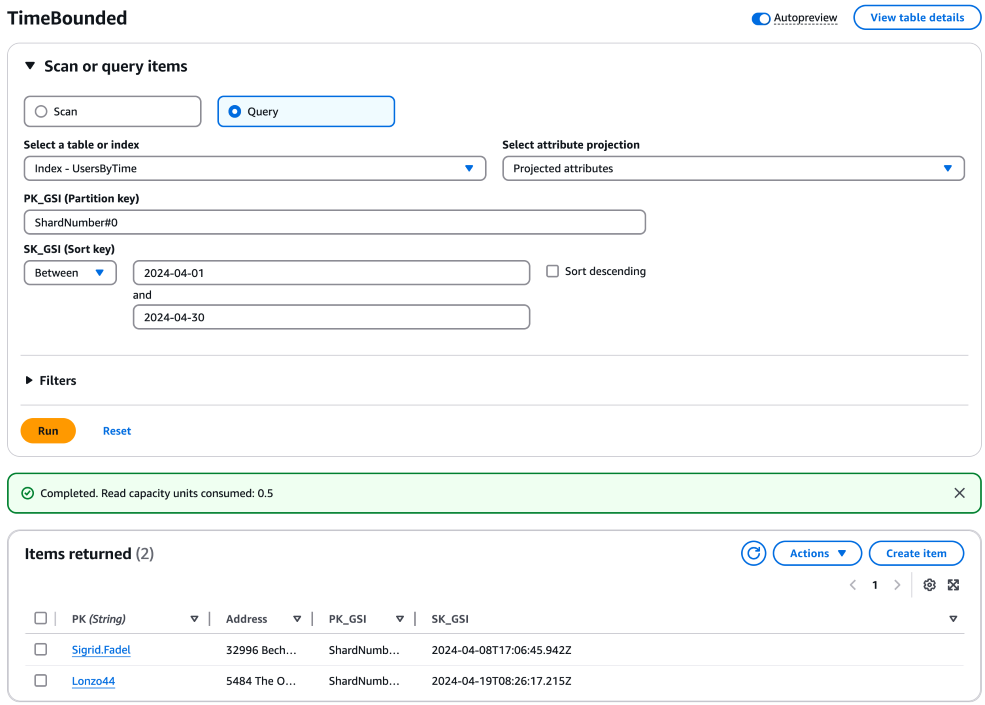
您可以為每個碎片複寫此查詢,並相應地調整分割區索引鍵 (例如,「ShardNumber#1」、「ShardNumber#2」、...、「ShardNumber#9」)。
所有查詢完成後,彙總每個查詢的結果。在應用程式程式碼中執行此彙總,將結果合併為代表指定時間範圍內所有碎片項目的單一資料集。
平行查詢執行考量
每個查詢都會消耗資料表或索引的讀取容量。如果您使用的是佈建的輸送量,請確定您的資料表已佈建足夠的容量來處理大量的平行查詢。如果您使用的是隨需容量,請注意潛在的成本影響。
程式碼範例
若要使用 Python 在 DynamoDB 中跨碎片執行平行查詢,您可以使用 boto3 程式庫,這是適用於 Python 的 Amazon Web Services SDK。此範例假設您已安裝 boto3 並使用適當的 AWS 登入資料進行設定。
下列 Python 程式碼示範如何在指定時間範圍內跨多個碎片執行平行查詢。它使用並行未來平行執行查詢,相較於循序執行,可縮短整體執行時間。
import boto3 from concurrent.futures import ThreadPoolExecutor, as_completed # Initialize a DynamoDB client dynamodb = boto3.client('dynamodb') # Define your table name and the total number of shards table_name = 'YourTableName' total_shards = 10 # Example: 10 shards numbered 0 to 9 time_start = "2030-03-15T09:00:00Z" time_end = "2030-03-15T10:00:00Z" def query_shard(shard_number): """ Query items in a specific shard for the given time range. """ response = dynamodb.query( TableName=table_name, IndexName='YourGSIName', # Replace with your GSI name KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end", ExpressionAttributeValues={ ":pk_val": {"S": f"ShardNumber#{shard_number}"}, ":date_start": {"S": time_start}, ":date_end": {"S": time_end}, } ) return response['Items'] # Use ThreadPoolExecutor to query across shards in parallel with ThreadPoolExecutor(max_workers=total_shards) as executor: # Submit a future for each shard query futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)} # Collect and aggregate results from all shards all_items = [] for future in as_completed(futures): shard_number = futures[future] try: shard_items = future.result() all_items.extend(shard_items) print(f"Shard {shard_number} returned {len(shard_items)} items") except Exception as exc: print(f"Shard {shard_number} generated an exception: {exc}") # Process the aggregated results (e.g., sorting, filtering) as needed # For example, simply printing the count of all retrieved items print(f"Total items retrieved from all shards: {len(all_items)}")
執行此程式碼之前,請務必YourTableNameYourGSIName使用 DynamoDB 設定中的實際資料表和 GSI 名稱取代 和 。此外,請根據您的特定需求調整 time_start、 total_shards和 time_end變數。
此指令碼會查詢每個碎片中指定時間範圍內的項目,並彙總結果。
