本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 DynamoDB 中製作關聯式資料模型的第一步
重要
NoSQL 設計思維與 RDBMS 設計不同。針對 RDBMS,您可以建立標準化的資料模型,而不需考量存取模式。您可以在稍後有新問題與查詢要求時擴展此模型。相反地,在 Amazon DynamoDB 中,您不應開始設計結構描述,除非您知道其需要回答的問題。您絕對必須事先了解企業問題和應用程式使用案例。
若要開始設計能有效擴展的 DynamoDB 資料表,您必須先執行數個步驟,以識別操作所需的存取模式與其需要支援的企業支援系統 (OSS/BSS):
針對新應用程式,檢視活動與目標相關的使用者案例。記錄您識別的各種使用案例,並分析案例需要的存取模式。
針對現有應用程式,分析查詢記錄以找出人員目前使用系統的方式與索引鍵存取模式為何。
完成此程序後,您將收到一個清單,其看起來可能與以下類似。
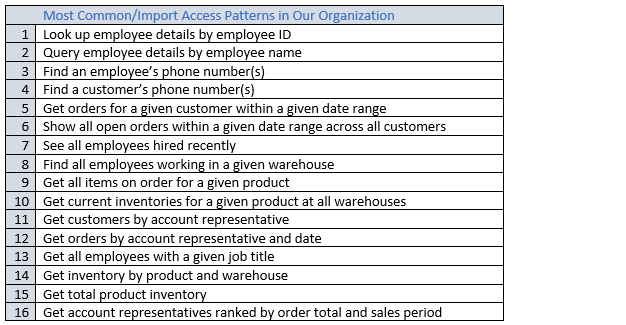
在實際應用中,您的清單可能會更長。但此集合代表您可能會在生產環境中找到的查詢模式複雜度範圍。
DynamoDB 結構描述設計的常見方法是識別應用程式層實體,並使用非標準化和複合金鑰彙總來降低查詢複雜性。
在 DynamoDB 中,此表示使用複合排序索引鍵、多載全域次要索引、分割區資料表/索引和其他設計模式。您可以使用這些元素來建構資料,如此應用程式就可以使用對資料表或索引的單一查詢來擷取特定存取模式所需的項目。在 關聯式模型 中顯示您可以用來製作標準化結構描述模型的主要模式是相鄰清單模式。此設計中使用的其他模式可能包含全域次要索引寫入分片、全域次要索引多載、複合索引鍵和具體化的彙總。
重要
一般來說,您在 DynamoDB 應用程式中維護的資料表應越少越好。例外狀況包含大量時間序列資料涉及其中的案例,或存取模式極為不同的資料集。含反轉索引的單一資料表通常可以啟用簡單查詢,來建立並擷取您應用程式所需的複雜階層資料結構。
若要使用適用於 DynamoDB 的 NoSQL Workbench 來協助視覺化您的分割區索引鍵設計,請參閱 使用 NoSQL Workbench 建立資料模型。
