本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 DynamoDB 中處理時間序列資料的最佳實務
Amazon DynamoDB 中的一般設計原則會建議您盡量減少使用的資料表數量。對於大多數應用程式,您只需要一張資料表。不過,對於時間序列資料,您通常可以在每個期間針對每個應用程式使用一個資料表,這是最好的處理方式。
時間序列資料的設計模式
假設一個典型的時間序列情況,這時您想追蹤大量事件。您的寫入存取模式是所有正在記錄的事件都記有今天的日期。您的讀取存取模式可能是讀取今天最頻繁的活動,昨天的活動則較少讀存,然後更舊的活動則極少讀存。處理這種情況的一個方法,就是將目前的日期和時間內建到主索引鍵中。
以下設計模式通常能有效處理這種情況:
-
每個期間建立一個資料表,並且佈建所需的讀取和寫入容量,以及必要的索引。
-
在每個期間結束之前,先為下一個期間預先建立資料表。在目前時段結束時,將事件流量引導至新資料表。您可以為這些資料表指派名稱,來為其所記錄的期間命名。
-
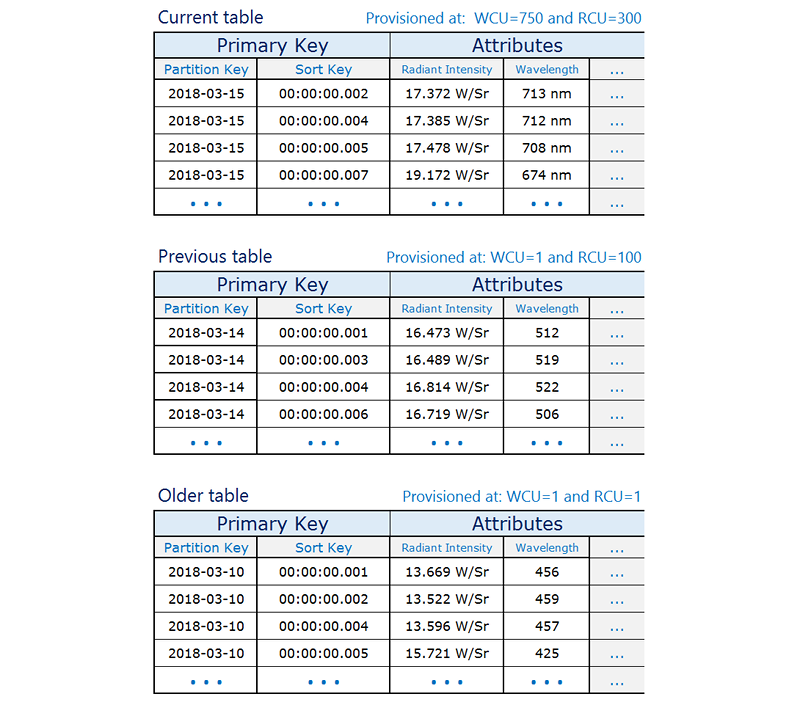
一旦資料表不再被寫入,會將其佈建的寫入容量減少到較低的值 (例如,1 個 WCU),並佈建適當的讀取容量。隨著舊資料表的存在時間拉長,逐漸地縮減其佈建的讀取容量。您可以針對內容極少用到或不再需要的資料表,選擇封存或刪除這些資料表。
這個概念是針對目前將會產生最高流量的期間,配置所需的資源,然後針對目前未經常使用的舊資料表,縮減佈建的容量,以節省成本。根據您的業務需求,您可能需要考慮寫入分片的方法,來將流量平均地分配到邏輯分割區索引鍵。如需詳細資訊,請參閱使用寫入碎片在 DynamoDB 資料表中平均分配工作負載。
時間序列資料表範例
下列是時間序列資料的範例,其中針對目前的資料表佈建了較高的讀取/寫入容量,並縮減舊資料表的佈建容量,因為這些資料表不常存取。