本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
解析程式
從先前的章節中,您已了解結構描述和資料來源的元件。現在,我們需要解決結構描述和資料來源的互動方式。一切都從解析程式開始。
解析程式是程式碼單位,可處理在向服務提出請求時,該欄位的資料將如何解決。解析程式會連接到您結構描述中類型內的特定欄位。它們最常用於實作查詢、變動和訂閱欄位操作的狀態變更操作。解析程式會處理用戶端的請求,然後傳回結果,可以是一組輸出類型,例如物件或純量:

Resolver 執行時間
在 中 AWS AppSync,您必須先指定解析程式的執行時間。解析程式執行時間表示執行解析程式的環境。它還指定解析程式將寫入的語言。 AWS AppSync 目前支援 APPSYNC_JS for JavaScript and Velocity Template Language (VTL)。請參閱適用於 JavaScript 的解析程式和函數的 JavaScript 執行期功能,或適用於 VTL 的解析程式映射範本公用程式參考。 JavaScript
解析程式結構
解析程式的程式碼化結構有兩種方式。有單位和管道解析程式。
單位解析程式
單位解析程式是由程式碼組成,可定義針對資料來源執行的單一請求和回應處理常式。請求處理常式會將內容物件做為引數,並傳回用來呼叫資料來源的請求承載。回應處理常式會從資料來源接收承載,其中包含執行請求的結果。回應處理常式會將承載轉換為 GraphQL 回應,以解析 GraphQL 欄位。
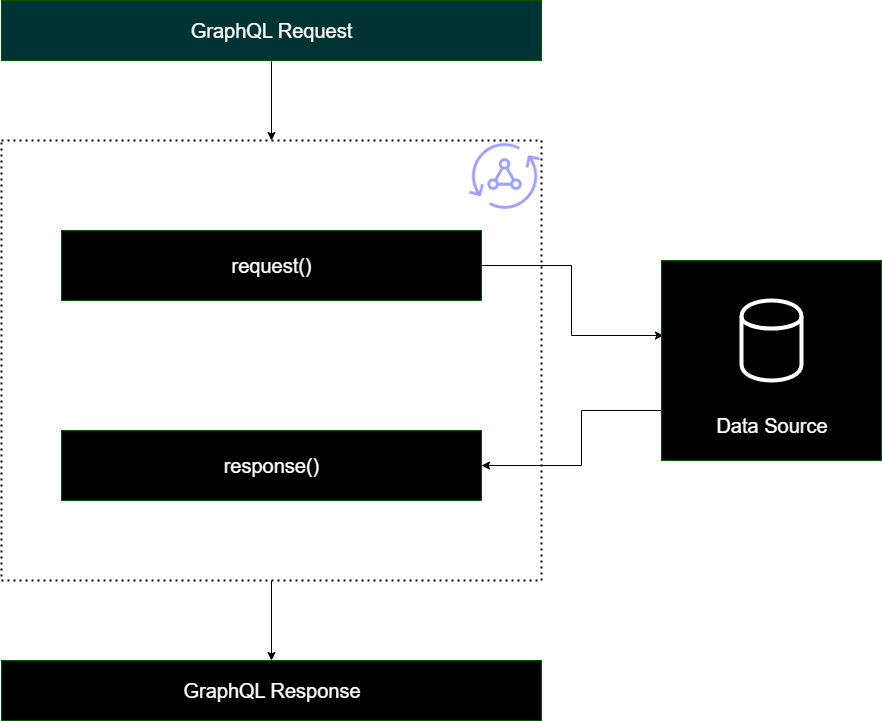
管道解析程式
實作管道解析程式時,會遵循一般結構:
-
在步驟之前:當用戶端提出請求時,所使用結構描述欄位的解析程式 (通常是您的查詢、變動、訂閱) 會傳遞請求資料。解析程式將開始在步驟處理常式之前處理請求資料,這允許在資料通過解析程式之前執行一些預先處理操作。
-
Function(s):在步驟執行之前,請求會傳遞至函數清單。清單中的第一個函數會針對資料來源執行。函數是解析程式程式碼的子集,其中包含自己的請求和回應處理常式。請求處理常式會取得請求資料,並對資料來源執行操作。回應處理常式會先處理資料來源的回應,再將其傳回清單。如果有多個函數,請求資料會傳送至清單中要執行的下一個函數。清單中的函數將按照開發人員定義的順序序列執行。執行所有函數後,最終結果會傳遞至步驟後 。
-
後步驟:後步驟是處理常式函數,可讓您先對最終函數的回應執行一些最終操作,再將其傳遞至 GraphQL 回應。

Resolver 處理常式結構
處理常式通常是稱為 Request和 的函數Response:
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
在單位解析程式中,只有一組這些函數。在管道解析程式中,在步驟前後會有一組適用於 的集合,以及每個函數的額外集合。為了視覺化這看起來的樣子,讓我們檢閱一個簡單的Query類型:
type Query { helloWorld: String! }
這是簡單的查詢,有一個欄位稱為helloWorld類型 String。假設我們一律希望此欄位傳回字串 "Hello World"。若要實作此行為,我們需要將解析程式新增至此欄位。在單位解析程式中,我們可以新增如下內容:
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
request 只能保留空白,因為我們不會請求或處理資料。我們也可以假設資料來源為 None,表示此程式碼不需要執行任何調用。回應只會傳回「Hello World」。若要測試此解析程式,我們需要使用查詢類型提出請求:
query helloWorldTest { helloWorld }
這是名為 的查詢helloWorldTest,會傳回 helloWorld 欄位。執行時,helloWorld欄位解析程式也會執行並傳回回應:
{ "data": { "helloWorld": "Hello World" } }
傳回像這樣的常數是最簡單的方法。實際上,您將傳回輸入、清單等。以下是更複雜的範例:
type Book { id: ID! title: String } type Query { getBooks: [Book] }
在這裡,我們會傳回 的清單Books。假設我們使用 DynamoDB 資料表來存放書籍資料。我們的處理常式可能如下所示:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
我們的請求使用內建掃描操作來搜尋資料表中的所有項目、將調查結果存放在內容中,然後將其傳遞給回應。回應接受了結果項目,並在回應中傳回它們:
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
解析程式內容
在解析程式中,處理常式鏈中的每個步驟都必須知道先前步驟的資料狀態。一個處理常式的結果可以儲存並傳遞給另一個處理常式做為引數。GraphQL 定義四個基本解析程式引數:
| 解析程式基本引數 | Description |
|---|---|
obj、root、parent 等等 |
父系的結果。 |
args |
提供給 GraphQL 查詢中 欄位的引數。 |
context |
提供給每個解析程式的值,並保留如目前登入使用者或資料庫存取權等重要內容資訊。 |
info |
值,其中包含與目前查詢相關的欄位特定資訊,以及結構描述詳細資訊。 |
在 中 AWS AppSync, context (ctx) 引數可以保留上述所有資料。這是每個請求建立的物件,包含授權登入資料、結果資料、錯誤、請求中繼資料等資料。內容是程式設計人員操作來自請求其他部分的資料的簡單方法。再次使用此程式碼片段:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
請求會指定內容 (ctx) 做為引數;這是請求的狀態。它會對資料表中的所有項目執行掃描,然後將結果存放在 的內容中result。接著內容會傳遞至回應引數,該引數會存取 result並傳回其內容。
請求和剖析
當您查詢 GraphQL 服務時,必須先執行剖析和驗證程序,才能執行。您的請求將會剖析並翻譯為抽象語法樹。透過針對結構描述執行多個驗證演算法來驗證樹狀目錄的內容。在驗證步驟之後,會周遊和處理樹狀結構的節點。系統會叫用解析程式、將結果儲存在內容中,並傳回回應。例如,採取以下查詢:
query { Person { //object type name //scalar age //scalar } }
我們會Person傳回 name和 age 欄位。執行此查詢時,樹狀結構看起來會像這樣:
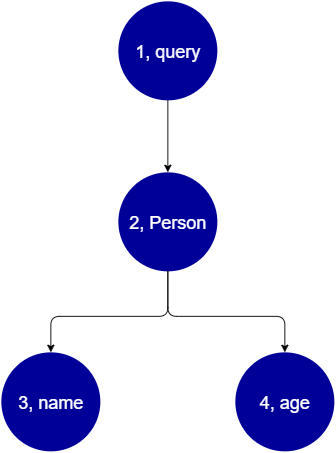
從樹狀目錄中,此請求似乎會在結構描述Query中搜尋 的根目錄。在查詢內, Person 欄位將會解析。從先前的範例中,我們知道這可能是來自 使用者的輸入、值清單等。 Person 很可能與保存所需欄位 (name 和 age) 的物件類型相關聯。找到這兩個子欄位後,它們會依指定的順序 (name 後面接著 age) 解析。樹狀結構完全解決後,請求即完成,並將傳回用戶端。
