本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Athena 使用 EXPLAIN 和 EXPLAIN ANALYZE
EXPLAIN 陳述式會顯示指定 SQL 陳述式的邏輯或分散式執行計劃,或驗證 SQL 陳述式。您可以以文字格式或資料格式輸出結果,以便轉譯成圖形。
注意
您可以在 Athena 主控台中檢視查詢的邏輯和分散式計劃的圖形呈現,無需使用 EXPLAIN 語法。如需詳細資訊,請參閱檢視 SQL 查詢的執行計劃。
EXPLAIN ANALYZE 陳述式會顯示指定 SQL 陳述式的分散式執行計劃,以及 SQL 查詢中每個操作的運算成本。您可以將結果輸出為文字或 JSON 格式。
考量與限制
在 Athena 的 EXPLAIN 和 EXPLAIN ANALYZE 陳述式有下列限制。
-
EXPLAIN查詢不會掃描任何資料,因此 Athena 不會為此收取費用。然而,由於EXPLAIN查詢會呼叫 AWS Glue 來擷取資料表中繼資料,如果呼叫超過 Glue 免費方案限制的次數,則會從 Glue 收取費用。 -
因為已執行
EXPLAIN ANALYZE查詢,它們會掃描資料,並且 Athena 會針對掃描的資料量收取費用。 -
在 Lake Formation 中定義的資料列或儲存格篩選資訊及查詢統計資料資訊未在
EXPLAIN和EXPLAIN ANALYZE的輸出中顯示。
EXPLAIN 語法
EXPLAIN [ (option[, ...]) ]statement
option 可為下列項目之一:
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
如果未指定 FORMAT 選項,則輸出預設為 TEXT 格式。IO 類型提供有關查詢讀取的資料表和結構描述的資訊。
EXPLAIN ANALYZE 語法
除了包含在 EXPLAIN,EXPLAIN
ANALYZE 輸出也包含指定查詢的執行時間統計數字,例如 CPU 用量、資料列輸入數目以及資料列輸出數目。
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option 可為下列項目之一:
FORMAT { TEXT | JSON }
如果未指定 FORMAT 選項,則輸出預設為 TEXT 格式。因為 EXPLAIN ANALYZE 的所有查詢為 DISTRIBUTED,則 TYPE 選項不可為 EXPLAIN ANALYZE。
陳述式可為下列其中之一:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAIN 範例
下列針對 EXPLAIN 的範例從較簡單的內容進展到較複雜的內容。
在下列範例中,EXPLAIN 會顯示對 Elastic Load Balancing 日誌的 SELECT 查詢的執行計劃。格式預設為文字輸出。
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
結果
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULAR您可以使用 Athena 主控台來繪製查詢計劃圖。在查詢編輯器中輸入類似以下的 SELECT 陳述式,然後選擇 EXPLAIN。
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
Athena 查詢編輯器的 Explain (解釋) 頁面隨即開啟,並顯示查詢的分散式計劃和邏輯計劃。下圖顯示範例的邏輯計劃。
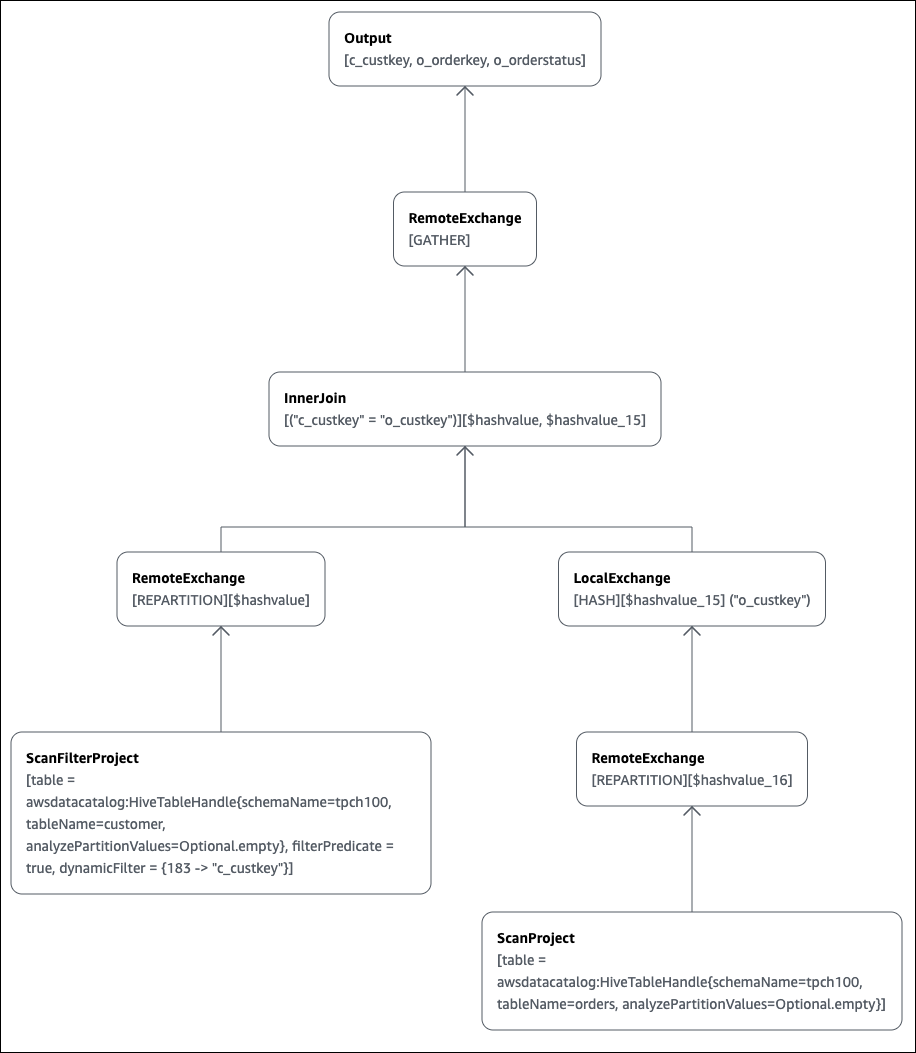
重要
目前,即使 Athena 確實將這些篩選條件套用至您的查詢,有些分割區篩選條件可能不會顯示在巢狀運算子樹狀結構圖形中。若要驗證此等篩選條件的效果,請在查詢上執行 EXPLAIN 或 EXPLAIN
ANALYZE 並查看結果。
如需在 Athena 主控台中使用查詢計劃圖形功能的詳細資訊,請參閱 檢視 SQL 查詢的執行計劃。
當您對分割的金鑰使用篩選述詞來查詢分割的資料表時,查詢引擎會將述詞套用至分割的金鑰,以減少讀取的資料量。
以下範例使用 EXPLAIN 查詢,對分割資料表上的 SELECT 查詢驗證分割區剔除。首先,CREATE TABLE 陳述式會建立 tpch100.orders_partitioned 資料表。該資料表在資料欄 o_orderdate 上分割。
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
tpch100.orders_partitioned 資料表在 o_orderdate 上有多個分割區,如 SHOW PARTITIONS 命令所示。
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
下列 EXPLAIN 查詢會對指定 SELECT 陳述式驗證分割區剔除。
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
結果
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR結果中的粗體文字顯示述詞 o_orderdate =
'1995' 已套用於 PARTITION_KEY。
下列 EXPLAIN 查詢會檢查 SELECT 陳述式的聯結順序和聯結類型。使用這樣的查詢來檢查查詢記憶體的使用情況,以便減少取得 EXCEEDED_LOCAL_MEMORY_LIMIT 錯誤的可能性。
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
結果
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR查詢範例在交叉聯結中得到最佳化處理,以獲得更好的性能。結果顯示 tpch100.orders 將作為 BROADCAST 分佈類型進行分配。這意味著 tpch100.orders 資料表將分配到執行聯結操作的所有節點。BROADCAST 分佈類型會要求 tpch100.orders 資料表的所有篩選結果納入執行聯結操作的每個節點的記憶體。
不過,tpch100.customer 資料表比 tpch100.orders 小。由於 tpch100.customer 需要更少的記憶體,您可以將查詢重寫為 BROADCAST
tpch100.customer,而非 tpch100.orders。這可減少查詢取得 EXCEEDED_LOCAL_MEMORY_LIMIT 錯誤的可能性。此策略假設下列要點:
-
在
tpch100.customer資料表中tpch100.customer.c_custkey為唯一。 -
在
tpch100.customer和tpch100.orders間有一對多的映射關係。
下列範例顯示重寫的查詢。
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
您可以使用 EXPLAIN 查詢來檢查篩選述詞的有效性。您可以使用結果移除沒有效果的述詞,如下列範例所示。
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
結果
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAR結果中的 filterPredicate 顯示優化器將原始三個述詞合併為兩個述詞,並更改了應用程式的順序。
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
因為結果顯示述詞 AND c.c_custkey BETWEEN
1000 AND 2000 沒有任何效果,您可以在不更改查詢結果的情況下移除此述詞。
如需有關 EXPLAIN 查詢結果中所使用術語的詳細資訊,請參閱了解 Athena EXPLAIN 陳述式結果。
EXPLAIN ANALYZE 範例
下列範例將顯示範例 EXPLAIN ANALYZE 查詢和輸出。
在下列範例中,EXPLAIN ANALYZE 會顯示對 CloudFront 日誌的 SELECT 查詢的執行計劃和運算成本。格式預設為文字輸出。
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
結果
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAR下列範例會顯示對 CloudFront 日誌的 SELECT 查詢的執行計劃和運算成本。此範例指定 JSON 作為輸出格式。
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
結果
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}其他資源
如需其他資訊,請參閱以下資源。
-
Trino
EXPLAIN文件 -
Trino
EXPLAIN ANALYZE文件 -
AWS 大數據部落格中的使用 Amazon Athena 中的 EXPLAIN 和 EXPLAIN ANALYZE 優化聯合查詢效能
。
