本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon Bedrock 知識庫的運作方式
Amazon Bedrock 知識庫可協助您利用擷取增強生成 (RAG),這是一種熱門的技術,涉及從資料存放區提取資訊,以增強大型語言模型 (LLMs) 產生的回應。當您使用資料來源設定知識庫時,應用程式可以查詢知識庫以傳回資訊,以使用來源的直接引號或查詢結果產生的自然回應來回答查詢。
使用 Amazon Bedrock 知識庫,您可以建置應用程式,這些應用程式會因查詢知識庫而收到的內容而擴充。透過從繁重的建置管道中抽取出來,並提供現成可用的 RAG 解決方案,以減少應用程式的建置時間,進而加快上市時間。新增知識庫也可提高成本效益,因為不需要持續訓練模型來利用您的私有資料。
以下圖表以圖解方式說明 RAG 的進行方式。知識庫透過自動執行此過程中的幾個步驟,簡化 RAG 的設定和實作。
預先處理非結構化資料
若要從非結構化私有資料 (不存在於結構化資料存放區中的資料) 進行有效擷取,常見的做法是將資料轉換為文字,並將其分割為可管理的部分。然後,片段或區塊會轉換為內嵌,並寫入向量索引,同時維持與原始文件的映射。這些內嵌項用於確定查詢和資料來源的文字之間的語意相似性。下圖說明了向量資料庫資料的預先處理。
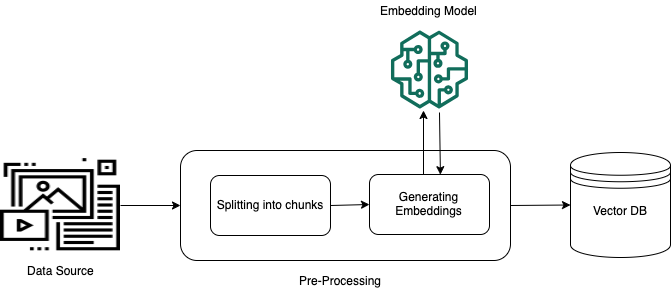
向量內嵌是代表每個文字區塊的一系列數字。模型會將每個文字區塊轉換為一系列數字,稱為向量,以數學方式比較文字。這些向量可以是浮點數 (float32) 或二進位數字。根據預設,Amazon Bedrock 支援的大多數內嵌模型都會使用浮點向量。不過,某些模型支援二進位向量。如果您選擇二進位內嵌模型,您還必須選擇支援二進位向量的模型和向量存放區。
每個維度僅使用 1 位元的二進位向量,其在儲存上的成本不如浮點 (float32) 向量高,每個維度使用 32 位元。不過,二進位向量在文字的呈現方式中不如浮點向量精確。
下列範例以三種表示法顯示一段文字:
| 代表 | Value |
|---|---|
| 文字 | 「Amazon Bedrock 使用來自領導 AI 公司和 Amazon 的高效能基礎模型。」 |
| 浮點向量 | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| 二進位向量 | [1,1,0,0,0, ...] |
執行期執行
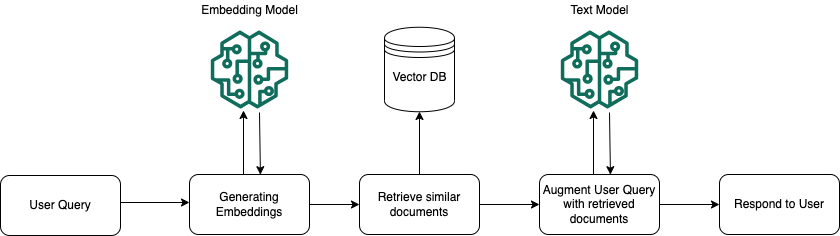
在執行期,內嵌模型用於將使用者的查詢轉換為向量。然後查詢向量索引,藉由將文件向量與使用者查詢向量進行比較,以尋找語意與使用者查詢類似的區塊。在最後一個步驟中,使用從向量索引擷取的區塊中的其他內容來增強使用者提示。然後,提示與附加上下文一起傳送到模型,為使用者產生回應。下圖說明 RAG 如何在執行期運作,以增強對使用者查詢的回應。
若要進一步了解如何將資料轉換為知識庫、如何在設定知識庫之後查詢知識庫,以及您可以在擷取期間套用至資料來源的自訂,請參閱下列主題:
