本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
最佳化
為了充分利用您的 GPU,您可以最佳化資料管道及調整深度學習網路。如下圖所述,神經網路的單純或基本實作使用 GPU 的方式可能不一致,而未完全發揮其潛能。當您最佳化您的前處理和資料載入時,您可以降低從 CPU 到 GPU 的瓶頸。您可以使用雜合 (當架構支援時)、調整批次大小和同步化呼叫,以調整神經網路本身。您在大多數架構中也可以使用多精確度 (float16 或 int8) 培訓,這可以大幅影響提高輸送量。
下列圖表顯示套用不同的最佳化時累積的效能提升。您的結果將取決於您處理的資料和您最佳化的網路。
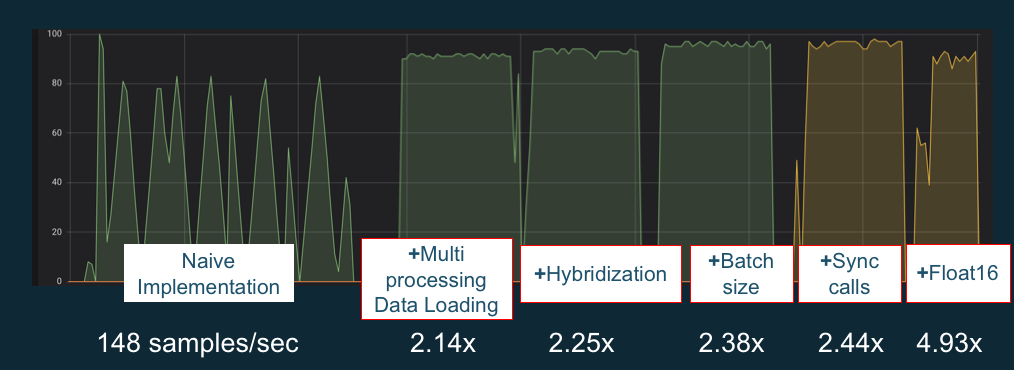
範例 GPU 效能最佳化。圖表來源:使用 MXNet Gluon 的效能技巧
下列指南介紹可搭配 DLAMI 使用的選項,協助您提升 GPU 效能。
