本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用績效詳情 API 來擷取指標
在啟用績效詳情時,API 會提供對執行個體效能的可見性。Amazon CloudWatch Logs 提供授權來源,以用於 AWS 服務的付費監控指標。
績效詳情提供以平均作用中工作階段 (AAS) 評估的資料庫負載特定網域檢視。此指標在 API 消費者看來是二維時間序列資料集。資料的時間維度提供查詢的時間範圍內各時間點的資料庫負載資料。每個時間點會根據請求的維度來分解整體負載,例如 Query、Wait-state、Application、或者 Host,在該時間點所測得。
Amazon DocumentDB Performance Insights 會監控您的 Amazon DocumentDB 資料庫執行個體,讓您可以分析資料庫效能並進行疑難排解。檢視績效詳情資料的一個方法就是使用 AWS Management Console。績效詳情也提供公有 API,讓您可以查詢自己的資料。您可以使用 API 執行下列動作:
-
將資料卸載至資料庫
-
將績效詳情資料新增至現有監控儀表板
-
建置監控工具
若要使用績效詳情 API,請在其中一個 Amazon DocumentDB 執行個體上啟用績效詳情。如需啟用績效詳情的相關資訊,請參閱 啟用和停用績效詳情。如需績效詳情 API 的相關詳細資訊,請參閱 績效詳情 API 參考。
績效詳情 API 提供下列操作。
|
績效詳情動作 |
AWS CLI 命令 |
描述 |
|---|---|---|
|
針對特定時段,擷取其指標的前 N 個維度金鑰。 |
||
|
擷取資料庫執行個體或資料來源之指定維度群組的屬性。例如,如果您指定查詢 ID,而且有可用的維度詳細資訊, 會 |
||
GetResourceMetadata |
檢索不同功能的中繼資料。例如,中繼資料可能指出特定資料庫執行個體上某項功能已開啟或關閉。 |
|
|
擷取一組資料來源某個時段的績效詳情指標。您可以提供特定維度群組和維度,以及為每個群組提供彙總和篩選條件。 |
||
ListAvailableResourceDimensions |
檢索指定執行個體上每個指定指標類型可查詢的維度。 |
|
ListAvailableResourceMetrics |
檢索可為指定資料庫執行個體查詢的指定指標類型中所有可用的指標。 |
AWS CLI for Performance Insights
您可以使用 AWS CLI檢視績效詳情資料。您可以透過在命令列輸入以下內容來檢視績效詳情 AWS CLI 命令的說明。
aws pi help
如果您尚未 AWS CLI 安裝 ,請參閱AWS CLI 《 使用者指南》中的安裝 AWS 命令列界面,以取得安裝它的相關資訊。
擷取時間序列指標
GetResourceMetrics 操作會從績效詳情資料中擷取一或多個時間時間序列指標。GetResourceMetrics 需要指標和時間間隔,並傳回含資料點清單的回應。
例如, AWS Management Console 使用 GetResourceMetrics 填入計數器指標圖表和資料庫負載圖表,如下圖所示。
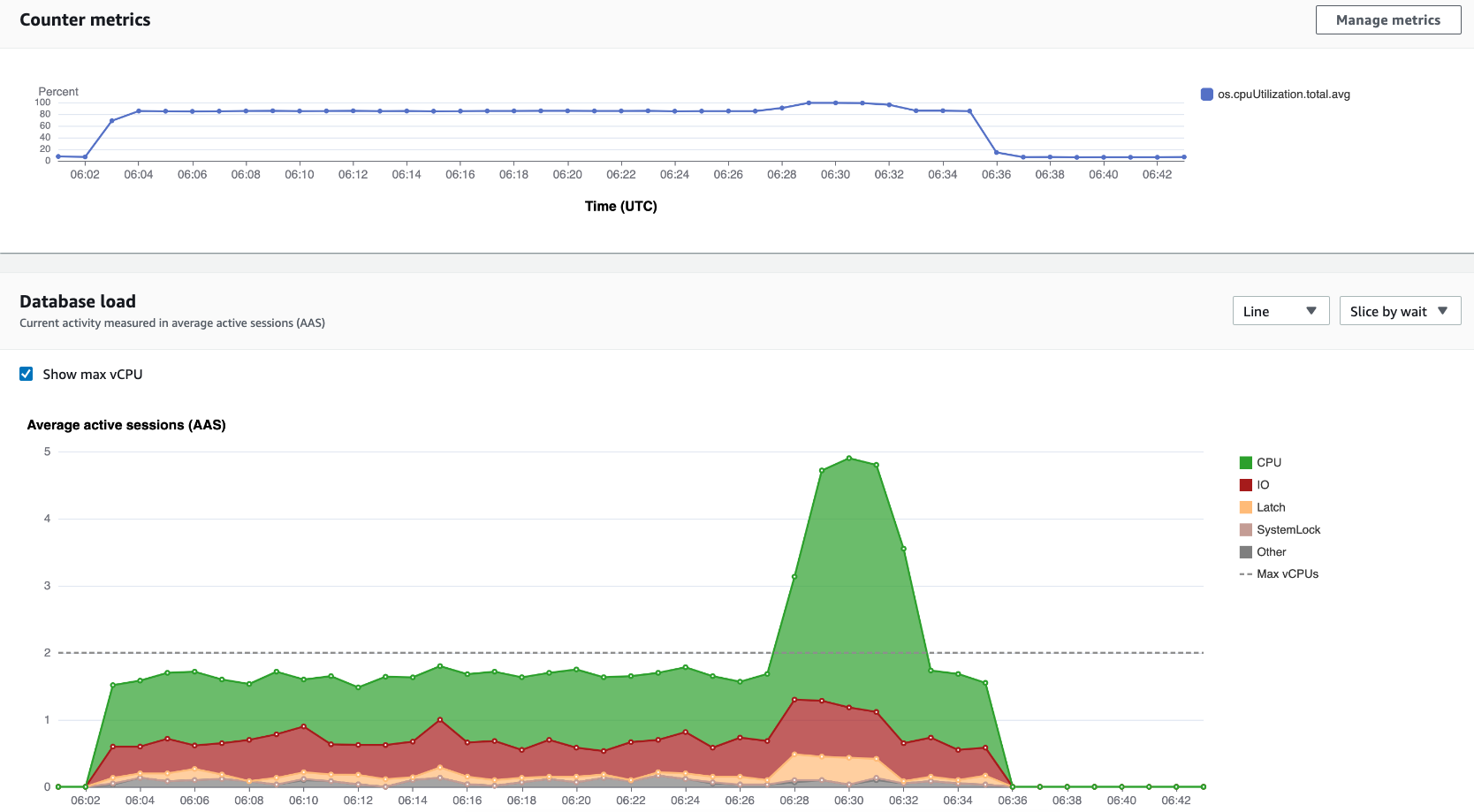
GetResourceMetrics 傳回的所有指標,除 db.load 之外,皆為標準的時間序列指標。此指標會顯示在 Database Load (資料庫負載) 圖表中。db.load 指標與其他時間序列指標不同,因為您可以將它分為名為維度的子元件。在先前的影像中,db.load 已被細分,分組依據為組成 db.load 的等待狀態。
注意
GetResourceMetrics 也可以傳回 db.sampleload 指標,但 db.load 指標適用於大部分情況。
如需 GetResourceMetrics 所傳回指標的相關資訊,請參閱計數器指標的績效詳情。
這些指標支援下列計算:
-
平均值 – 指標在一段時間內的平均值。將
.avg附加至指標名稱。 -
最小值 – 指標在一段時間內的最小值。將
.min附加至指標名稱。 -
最大值 – 指標在一段時間內的最大值。將
.max附加至指標名稱。 -
總和 – 指標值在一段時間內的總和。將
.sum附加至指標名稱。 -
取樣計數 – 在一段時間內收集指標的次數。將
.sample_count附加至指標名稱。
例如,假設收集指標的時間為 300 秒 (5 分鐘),且每分鐘收集一次指標。每分鐘的值為 1、2、3、4 和 5。在此情況下,會傳回下列計算:
-
平均值 – 3
-
最小值 – 1
-
最大值 – 5
-
總和 – 15
-
取樣計數 – 5
如需使用 get-resource-metrics AWS CLI 命令的資訊,請參閱 get-resource-metrics。
對於 --metric-queries 選項,請指定您要取得結果的一或多個查詢。每個查詢的組成為必要的 Metric 和選用的 GroupBy 及 Filter 參數。以下是 --metric-queries 選項規格的範例。
{ "Metric": "string", "GroupBy": { "Group": "string", "Dimensions": ["string", ...], "Limit": integer }, "Filter": {"string": "string" ...}
AWS CLI 績效詳情的範例
下列範例示範如何使用 AWS CLI for Performance Insights 的 。
擷取計數器指標
下列螢幕擷取畫面顯示 AWS Management Console中的兩個計數器指標圖表。
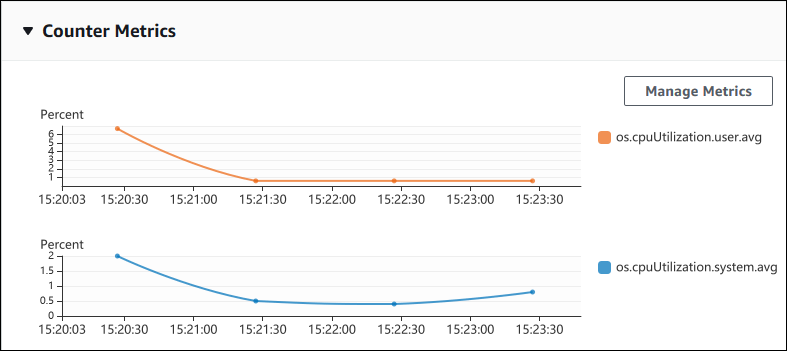
下凸顯是如何蒐集 AWS Management Console 用來產生兩個計數器指標圖表的相同資料。
針對 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
針對 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
您也可以透過指定 --metrics-query 選項的檔案來提高命令的可讀性。以下範例會將名為 query.json 的檔案用於此選項。此檔案的內容如下。
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
執行下列命令來使用檔案。
針對 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
針對 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
先前的範例會為選項指定下列值:
-
--service-type–DOCDB適用於 Amazon DocumentDB -
--identifier– 資料執行個體的資源 ID -
--start-time和--end-time– 要查詢期間的 ISO 8601DateTime值,支援多種格式
它會查詢一小時的時間範圍:
-
--period-in-seconds–60適用於每分鐘的查詢 -
--metric-queries– 兩個查詢的陣列,一個指標剛好一個查詢。此指標名稱會使用點將指標分類在實用的類別,其中最後一個元素則做為函數。在此範例中,此函數是每個查詢的
avg。如同 Amazon CloudWatch,支援的函數是min、max、total和avg。
回應看起來類似以下的內容。
{ "AlignedStartTime": "2022-03-13T08:00:00+00:00", "AlignedEndTime": "2022-03-13T09:00:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ { "Key": { "Metric": "os.cpuUtilization.user.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", //Minute1 "Value": 3.6 }, { "Timestamp": "2022-03-13T08:02:00+00:00", //Minute2 "Value": 2.6 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric { "Key": { "Metric": "os.cpuUtilization.idle.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", "Value": 92.7 }, { "Timestamp": "2022-03-13T08:02:00+00:00", "Value": 93.7 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric ] } ] //end of MetricList } //end of response
回應具有 Identifier、AlignedStartTime 和 AlignedEndTime。--period-in-seconds 值為 60,開始和結束時間皆一致使用分鐘。如果 --period-in-seconds 是 3600,開始和結束時間則會一致使用小時。
回應中的 MetricList 擁有許多項目,每個都包含 Key 和 DataPoints 項目。每個 DataPoint 都有 Timestamp 和 Value。每個 Datapoints 清單有 60 個資料點,因為查詢是適用於一小時中的每分鐘資料,內含 Timestamp1/Minute1、Timestamp2/Minute2 等,最多可達 Timestamp60/Minute60。
因為此查詢是適用於兩個不同的計數器指標,回應 MetricList 中會有兩個元素。
擷取最高等待狀態的資料庫負載平均值
下列範例與 AWS Management Console 用來產生堆疊區域折線圖的查詢相同。此範例會擷取最後一個小時db.load.avg的 ,負載會根據前七個等待狀態分割。此命令與 擷取計數器指標 中的命令相同。然而,查詢 query.json 檔案有以下內容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 7 } } ]
執行下列命令。
針對 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
針對 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
此範例會指定 的指標,db.load.avg以及前七大等待狀態GroupBy的 。如需此範例有效值的詳細資訊,請參閱績效詳情 API 參考中的DimensionGroup。
回應看起來類似以下的內容。
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_state.name": "CPU" } }, "DataPoints": [ { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the CPU key ] },//... In total we have 3 key/datapoints entries, 1) total, 2-3) Top Wait States ] //end of MetricList } //end of response
在此回應中, 中有三個項目MetricList。總計 有一個項目db.load.avg,根據前三個等待狀態之一db.load.avg分割的 有三個項目。由於有分組維度 (與第一個範例不同),因此指標的每個分組都必須有一個索引鍵。每個指標不能只有一個索引鍵,如同基本計數器指標使用案例。
擷取熱門查詢的資料庫負載平均值
下列範例db.wait_state依前 10 個查詢陳述式分組。查詢陳述式有兩個不同的群組:
-
db.query– 完整的查詢陳述式,例如{"find":"customers","filter":{"FirstName":"Jesse"},"sort":{"key":{"$numberInt":"1"}}} -
db.query_tokenized– 字符化查詢陳述式,例如{"find":"customers","filter":{"FirstName":"?"},"sort":{"key":{"$numberInt":"?"}},"limit":{"$numberInt":"?"}}
分析資料庫效能時,將僅因參數而異的查詢陳述式視為一個邏輯項目非常有用。因此,您可以在查詢時使用 db.query_tokenized。不過,特別是當您對 感興趣時explain(),有時使用參數檢查完整的查詢陳述式會比較有用。字符化查詢與完整查詢之間存在父子關係,多個完整查詢 (子) 分組在相同的字符化查詢 (父) 下。
此範例中的命令與 擷取最高等待狀態的資料庫負載平均值 中的命令類似。然而,查詢 query.json 檔案有以下內容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Limit": 10 } } ]
以下範例使用 db.query_tokenized。
針對 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
針對 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
此範例會查詢超過 1 小時,並以一分鐘period-in-seconds。
此範例會指定 的指標,db.load.avg以及前七大等待狀態GroupBy的 。如需此範例有效值的詳細資訊,請參閱績效詳情 API 參考中的DimensionGroup。
回應看起來類似以下的內容。
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { "Metric": "db.load.avg" }, "DataPoints": [ //... 60 datapoints for the total db.load.avg key ] }, { "Key": {//Next key are the top tokenized queries "Metric": "db.load.avg", "Dimensions": { "db.query_tokenized.db_id": "pi-1064184600", "db.query_tokenized.id": "77DE8364594EXAMPLE", "db.query_tokenized.statement": "{\"find\":\"customers\",\"filter\":{\"FirstName\":\"?\"},\"sort\":{\"key\":{\"$numberInt\":\"?\"}},\"limit\" :{\"$numberInt\":\"?\"},\"$db\":\"myDB\",\"$readPreference\":{\"mode\":\"primary\"}}" } }, "DataPoints": [ //... 60 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized queries, 1 total key ] //End of MetricList } //End of response
此回應在 中有 11 個項目 MetricList(總計 1 個,最多 10 個字符化查詢),每個項目每小時 24 個DataPoints。
對於字符化查詢,每個維度清單中有三個項目:
-
db.query_tokenized.statement– 字符化查詢陳述式。 -
db.query_tokenized.db_id– Performance Insights 為您產生的合成 ID。此範例會傳回pi-1064184600合成 ID。 -
db.query_tokenized.id– 績效詳情中查詢的 ID。在 中 AWS Management Console,此 ID 稱為支援 ID。其名稱如下,因為 ID 是 AWS Support 可以檢查的資料,以協助您對資料庫的問題進行故障診斷。 非常重視資料 AWS 的安全性和隱私權,而且幾乎所有資料都會以您的 加密儲存 AWS KMS key。因此,內部沒有人 AWS 可以查看此資料。在先前的範例中,
tokenized.statement和tokenized.db_id都同時會以加密的形式存放。如果您的資料庫發生問題, AWS Support 可以透過參考支援 ID 來協助您。
進行查詢時,在 Group 中指定 GroupBy 可能會讓您省下不少心力。然而,如需對已傳回的資料進行更精細的控制,請指定維度的清單。例如,如果所需的是 db.query_tokenized.statement,則可將 Dimensions 屬性新增至 query.json 檔案。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Dimensions":["db.query_tokenized.statement"], "Limit": 10 } } ]
擷取依查詢篩選的資料庫負載平均值
此範例中的對應 API 查詢與 擷取熱門查詢的資料庫負載平均值 中的命令類似。然而,查詢 query.json 檔案有以下內容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 5 }, "Filter": { "db.query_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
在此回應中,會根據 query.json 檔案中指定的字符化查詢 AKIAIOSFODNN7EXAMPLE 貢獻來篩選所有值。金鑰也可能遵循與沒有篩選條件的查詢不同的順序,因為這是影響篩選查詢的前五個等待狀態。
