本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Kubernetes 擴展理論
節點與流失率
當我們討論 Kubernetes 的可擴展性時,通常會根據單一叢集中有多少節點來執行此操作。有趣的是,這很少是了解可擴展性最有用的指標。例如,具有大量但固定數量 Pod 的 5,000 個節點叢集在初始設定後不會對控制平面造成很大的壓力。不過,如果我們採用 1,000 個節點叢集,並在不到一分鐘內嘗試建立 10,000 個短期活體任務,它會對控制平面造成很大的持續壓力。
只需使用節點數量來了解擴展可能會誤導。最好考慮特定期間內發生的變化率 (我們在此討論中使用 5 分鐘的間隔,因為這是 Prometheus 查詢預設通常會使用的間隔)。讓我們來探索為什麼根據變革速率來建構問題框架,可以讓我們更清楚要調整哪些內容以實現所需的規模。
每秒查詢數的思考
Kubernetes 為每個元件提供許多保護機制,包括 Kubelet、Scheduler、Kube Controller Manager 和 API 伺服器,以防止 Kubernetes 鏈中的下一個連結不堪負荷。例如,Kubelet 有一個標記,以特定速率調節對 API 伺服器的呼叫。這些保護機制通常是,但不總是以每秒允許的查詢或 QPS 來表示。
變更這些 QPS 設定時必須特別小心。移除一個瓶頸,例如 Kubelet 上的每秒查詢,將影響其他下游元件。這可能會和將會超過特定速率,因此了解和監控服務鏈的每個部分是成功擴展 Kubernetes 工作負載的關鍵。
注意
API 伺服器具有更複雜的系統,引進 API Priority and Fairness,我們將另行討論。
注意
注意,某些指標看起來很適合,但實際上是測量其他指標。例如, 只與 Kubelet 中的指標伺服器kubelet_http_inflight_requests相關,而不是 Kubelet 對 apiserver 請求的請求數量。這可能會導致我們在 Kubelet 上設定錯誤 QPS 旗標。查詢特定 Kubelet 的稽核日誌會是檢查指標的更可靠方式。
擴展分散式元件
由於 EKS 是一項受管服務,讓我們將 Kubernetes 元件分為兩個類別:AWS 受管元件,包括 etcd、Kube Controller Manager 和 Scheduler (位於圖表左側),以及客戶可設定的元件,例如 Kubelet、Container Runtime,以及呼叫 AWS APIs 的各種運算子,例如網路和儲存驅動程式 (位於圖表右側)。即使 API 伺服器受 AWS 管理,仍會將其保留在中間,因為客戶可以設定 API Priority 和 Fairness 的設定。
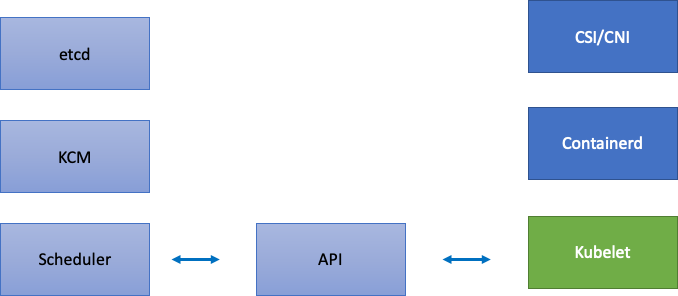
上游和下游瓶頸
當我們監控每個服務時,請務必查看兩個方向的指標,以尋找瓶頸。讓我們了解如何使用 Kubelet 作為範例來執行此操作。Kubelet 會與 API 伺服器和容器執行期進行通訊;我們需要監控什麼和方式來偵測任一元件是否發生問題?
每個節點的 Pod 數量
當我們查看擴展數字時,例如節點上可執行的 Pod 數量時,我們可以採用上游支援的每個節點 110 個 Pod 的臉部值。
不過,您的工作負載可能比在上游的可擴展性測試中測試的工作負載更複雜。為了確保我們可以為要在生產環境中執行的 Pod 數量提供服務,讓我們確保 Kubelet 與 Containerd 執行期保持同步。
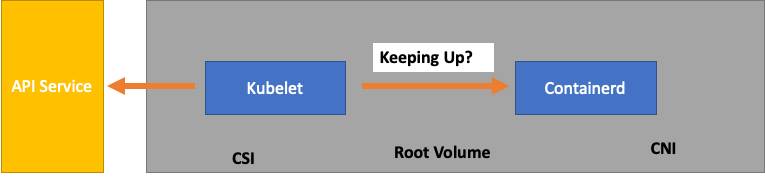
為了過度簡化,Kubelet 正在從容器執行時間 (在我們的案例中為 Containerd) 取得 Pod 的狀態。如果我們有太多 Pod 太快變更狀態,該怎麼辦? 如果變更率太高, 【對容器執行時間】 的請求可能會逾時。
注意
Kubernetes 不斷發展,此子系統目前正在進行變更。https://https://github.com/kubernetes/enhancements/issues/3386
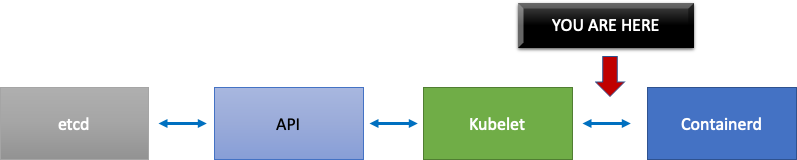

在上圖中,我們看到一條扁平線,指出我們剛達到 Pod 生命週期事件產生持續時間指標的逾時值。如果您想要在自己的叢集中看到此項目,您可以使用下列 PromQL 語法。
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
如果我們目擊此逾時行為,我們知道我們已將節點推送到其能夠達到的限制。我們需要修正逾時的原因,才能繼續。這可以透過減少每個節點的 Pod 數量,或尋找可能導致大量重試 (因此影響流失率) 的錯誤來實現。重要的重點是指標是了解節點是否能夠處理指派之 Pod 的流失率與使用固定數字的最佳方式。
依指標擴展
雖然使用指標來最佳化系統的概念是舊的,但當人們開始 Kubernetes 旅程時,通常會被忽略。我們不專注於特定數量 (即每個節點 110 個 Pod),而是專注於尋找指標,以協助我們找出系統中的瓶頸。了解這些指標的正確閾值可以讓我們對系統進行最佳設定的高度信任。
變更的影響
可能讓我們陷入麻煩的常見模式是專注於第一個看起來可疑的指標或日誌錯誤。當我們看到 Kubelet 提早逾時時,可以嘗試隨機物件,例如提高允許 Kubelet 傳送的每秒速率等。不過,最好先查看錯誤下游所有內容的全貌。以目的進行每項變更,並以資料為後盾。
Kubelet 下游會是 Containerd 執行時間 (Pod 錯誤)、DaemonSets,例如儲存驅動程式 (CSI) 和與 EC2 API 通訊的網路驅動程式 (CNI) 等。
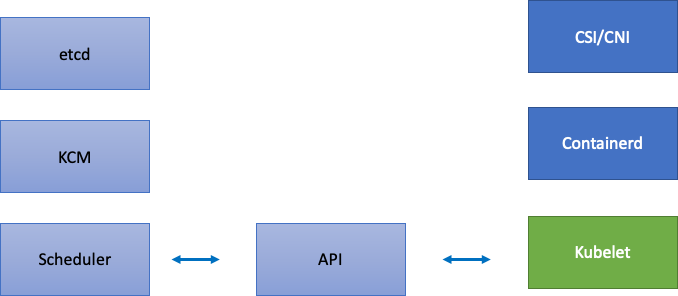
讓我們繼續先前的 Kubelet 範例,以免跟上執行時間。我們有許多點可以封裝節點,因此會密集地觸發錯誤。
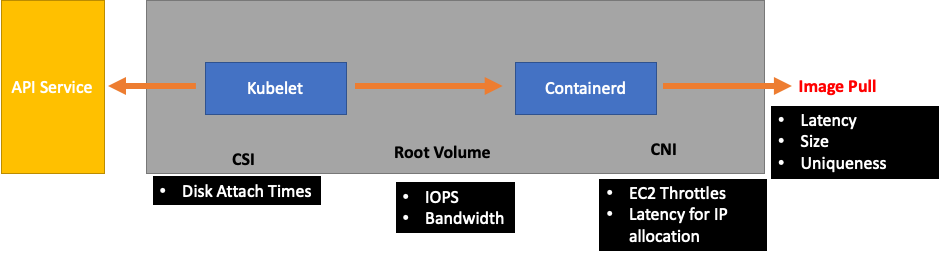
為工作負載設計正確的節點大小時,這些是easy-to-overlook的訊號,可能會對系統造成不必要的壓力,從而限制我們的規模和效能。
不必要的錯誤成本
Kubernetes 控制器在發生錯誤時擅長重試,但這需要付費。這些重試可能會增加 Kube Controller Manager 等元件的壓力。這是監控此類錯誤的重要規模測試租用戶。
當發生較少的錯誤時,更容易發現系統中的問題。透過定期確保叢集在主要操作 (例如升級) 之前沒有錯誤,我們可以在發生無法預期的事件時簡化日誌故障診斷。
擴展我們的檢視
在具有 1,000 個節點的大規模叢集中,我們不想個別尋找瓶頸。在 PromQL 中,我們可以使用稱為 topk 的函數在資料集中找到最高值;K 是我們放置所需項目數量的變數。在這裡,我們使用三個節點來了解叢集中的所有 Kubelet 是否飽和。到目前為止,我們一直在查看延遲,現在讓我們來看看 Kubelet 是否正在捨棄事件。
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
分解此陳述式。
-
我們使用 Grafana 變數
$__rate_interval來確保它取得所需的四個範例。這會略過使用簡單變數監控的複雜主題。 -
topk只給予我們最高結果,而數字 3 將這些結果限制為三個。這是適用於整個叢集指標的實用函數。 -
{}告訴我們沒有篩選條件,通常您會將任何抓取規則的任務名稱放入,但由於這些名稱不同,我們將保留空白。
將問題分割成一半
為了解決系統中的瓶頸,我們將採取方法來尋找顯示上游或下游發生問題的指標,因為這可讓我們將問題分成兩半。它也會是我們顯示指標資料的核心原則。
從此程序開始的好地方是 API 伺服器,因為它可讓我們查看用戶端應用程式或控制平面是否有問題。
